SENet (Squeeze-and-Excitation Network) https://arxiv.org/pdf/1709.01507
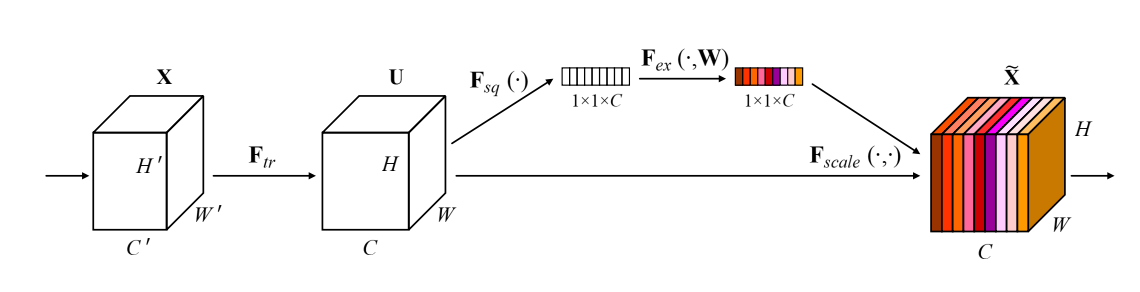
原理
SE模块是一个即插即用的模块,它是对特征图进行处理变换,将输入的(C^{’}*W^{’}*H^{’})变为(C*W*H)。如上图。做这个变换的原因是考虑特征的不同通道之间的关系,对于特征图而言,大量的通道中,可能有的通道的特征图有用,而有的无效,SE的想法就是通过学习的方式获取每个特征通道的重要程度,然后依照这个重要程度提升有用的特征,抑制无效的特征。
模块名称的由来是图上的两个操作:squeeze和excitation。(F_{tr})部分是一个普通的卷积变换,将输入变为(C*W*H)形状的(U)。对(U)进行(sq)和(ex)操作。
sq操作 : 将每个通道的(W*H)的特征图映射为一个可以表示其全局信息的数,用一个全局信息嵌入的向量表示特征图。论文中使用的是全局池化,对于每个通道的特征图(u_c),挤压后的输出通过公式(z_c = frac {Sum(u_c)}{H imes W}) 得到。原文表述如下图。
当然除了这里提到的全局平均池化,也有其他方式计算,只要得到的特征向量能够描述全局信息即可。

对每个通道进行上述操作,就可以得到(C)个数,是这(C)个通道的特征图描述算子。
ex操作 : 这个操作是通过上面得到的特征向量学习每个通道的特征权重。这个操作是为了获取通道之间的依赖性。
这一部分有两个要求:1.足够灵活,尤其是要能学习到通道之间的非线性相互作用(nonlinear interaction between channels)。 2. 要能学习到非互斥关系( non-mutually-exclusive relationship),因为要能确保多个通道被强调,意思就是突出某些通道,抑制另一些通道。而不是强制one-hot 激活,因为one-hot编码在同一个时间只有一个激活点,除了这个特征点外,其他都是0,而这里我们需要的是不同通道有各自对应的权重,而不是只突出一个。

论文中采用了一种简单的门控机制。使用两层全连接实现,两层先后用了ReLU和sigmoid激活,公式如上图。简化一下,输入(1*1*C)的向量(z),输出是(1*1*C)的向量(s),中间的变换为
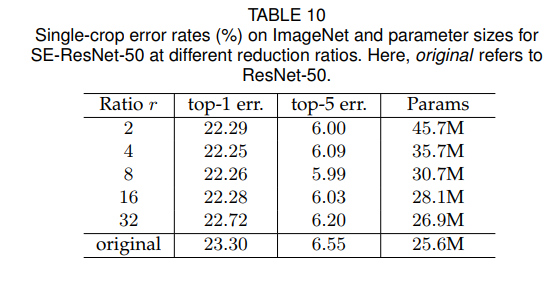
其中(W_1,W_2)是要学习的参数。显然,通道数目(C)中间经历了(C o mid\_channel o C)的变化。那么这个中间的通道数怎么计算呢?论文中定义了中间瓶颈的维度缩减比例(r), 这个超参数的取值是通过实验获得的,在ResNet-50的实验中,结果表明取(r=16)时在准确率与参数量(模型的复杂度)上取得较好的平衡。当然,论文中也说了,这个参数并不是一定是这个值,只是对ResNet-50网络中,采用16这个比例较好。对于不同的网络要自行决定这个超参数的值。
In practice, using an identical ratio throughout a network may not be optimal (due to the distinct roles performed by different layers), so further improvements may be achievable by tuning the ratios to meet the needs of a given base architecture.
通过ex操作后的(1*1*C)的向量,实际上描述了每个通道特征图的权重,最后加权到特征图上。即(F_{scale})部分,点积相乘(F_{scale}(u_c,s_c) = s_cu_c)。
效果
使用torch实现一个SE模块,代码如下。
import torch.nn as nn
class selayer(nn.Module):
def __init__(self,channel, ratio=16):
super(selayer,self).__init__()
self.gap = nn.AdaptiveAvgPool2d(1) # 全局平均池化 sq操作
self.fc = nn.Sequential( # 两个全连接层,ex操作
nn.Linear(channel, channel//ratio, bias=False), # 从 c -> c/r
nn.ReLU(inplace=True),
nn.Linear(channel//ratio, channel, bias=False), # 从 c/r -> c
nn.Sigmoid()
)
def forward(self,x ):
b, c, h, w = x.size()
y = self.gap(x).view(b,c) # sq
y = self.fc(y).view(b,c,1,1) # ex
return x*y.expand_as(x) # 将得到的权重乘以原来的特征图x
SE模块非常简单,但效果很好,可以添加到网络的各个部位,论文中实验了在ResNet中添加SE模块的效果。另外还探究了模块在网络中集成的位置,如下四种连接方式。
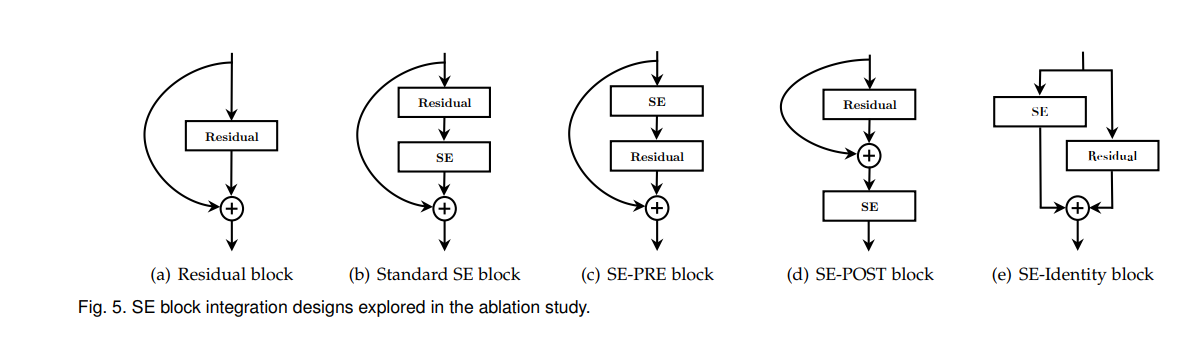
此外,论文还研究了sq操作和ex操作是否真的起了作用,还对比了替换掉池化操作,并将两个全连接层替换为(1 imes 1)卷积的 NoSqueeze。总之,论文最后的各种实验都证明了SE模块的有效性,emmm,结果就略了。
思考: 可以看到,SE模块的主要思想是通过权重的方式表示各通道特征图的重要性,这个所谓权重的计算是通过sq和ex操作完成。sq操作聚合了单个通道的空间信息,而ex操作则采用了两个全连接层,是对这(C)个特征向量的变换处理,从特征维度(channel-wise)方面聚合了信息,使用变换后的特征向量作为每个特征图的权重系数,从而改进特征图。在原论文的基础上,我们可以进行一些尝试,如其他获取全局信息特征向量的sq操作,不使用论文中的GAP,ex操作的压缩,有没有可能采用其他方法而不使用全连接层。或者sq操作中采用不同分支(事实上这就是改进版的SKNet,在sq和ex操作上增加了不同的分支)。对SE的魔改,主要就集中在sq聚合单个通道的信息和ex变换各个通道的特征向量上。