在Linux使用Jmeter做性能测试需要4个前提条件,这4个前提条件已经在之前的文档里提到了,重复一下加深印象:
(1) 在本地已安装xshell 参考《SecureCRT-转换密钥-Xshell-配置服务-使用xshell登录远程linux服务器》
(2) 在Linux有Java运行环境 参考《Jmeter-安装JDK- 配置Jmeter运行的环境 - 是使用Jmeter的前提》
(3) 在Linux已安装Jmeter 参考《Jmeter-安装Jmeter - 在Linux环境安装Jmeter - 在Windows环境安装Jmeter》
(4) 在Linux已配置HOSTS 参考《在Linux配置HOSTS的方法》、《在Windows配置HOSTS的方法》
那么本篇文档里会介绍:
(5) 在Windows构建1个测试脚本 //第1个步骤
(6) 在Windows,参数化这个测试脚本 //第2个步骤
(7) 在Windows把构建的这个测试脚本转化为用在Linux的测试脚本: //第3个步骤
a) 修改“线程组”的“线程数”、“启动线程时间”、“循环次数”、“调度器”
b) 参数化Request的值
c) 参数化Request的路径
d) 将“测试结果树”修改为“聚合报告”
e) 配置“聚合报告”的文件名
f) 配置“聚合报告”的Configure
第1个步骤:在Windows构建1个测试脚本 ( 以访问豆瓣的电影为例 )
场景1:验证用户访问豆瓣网站里《博物馆奇妙夜》这部电影(http://movie.douban.com/subject/1835843/)的页面。
#如何在Windows构建1个测试脚本可以参考之前的文档《Jmeter-一个完整的接口测试的脚本》,那篇文档描述得更加详细。所以本篇文档只作截图。但是也能很明白。
测试计划节点
因为我们是在Windows构建这个测试脚本,建议为这个脚本加1个标识(如:testPlanForWindows)[说白了,就是把测试计划保存的时候,名字写成"testPlanForWindows.jmx"]。这样就不会与"第3个步骤的测试脚本"混淆。

线程组节点
系统默认的“线程数”、“启动线程时间”、“循环次数”都是1,暂不作修改

HTTP请求默认值节点

HTTP请求节点
《博物馆奇妙夜》这部电影的URL是:http://movie.douban.com/subject/1835843/

察看结果树节点

运行一下测试脚本,看看脚本是不是能用
看看取样器结果返回是否:200 ok

看看Request这个URL是否写对了
通常我们在“HTTP请求默认值”写域名或者IP,在“HTTP请求”写剩余的URL,Jmeter会将这两部分的URL自动拼接成1个完整的Request URL。那么如果某1部分写错了,那么就会HTTP404,此时切换到“察看结果树-请求TAB”检查检查Request URL具体是哪里写错了,然后到“HTTP请求默认值”和“HTTP请求”修改正确就可以了。

第2个步骤:在Windows参数化这个测试脚本 ( 以访问豆瓣的电影为例,既然是参数化,那么就不只是访问1部电影了,我们以访问2部电影举例 )
场景1:验证用户访问豆瓣网站里《博物馆奇妙夜》这部电影的页面。
场景2:验证用户访问豆瓣网站里《博物馆奇妙夜》、《憨豆特工》这2部电影的页面。
那么先把两部电影的URL摆出来:
《博物馆奇妙夜》 http://movie.douban.com/subject/1835843/
《憨豆特工》http://movie.douban.com/subject/1307389/
我们只需要把“HTTP请求节点”处理一下就可以了
HTTP请求节点
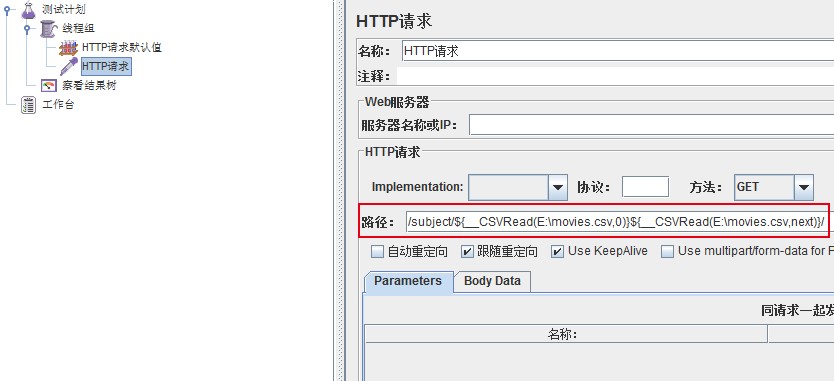
1、 对比一下参数化前后这个URL的变化
参数化前:/subject/1835843/
参数化后:/subject/${__CSVRead(E:movies.csv,0)}${__CSVRead(E:movies.csv,next)}/
2、 说明一下这2个URL的意思
参数化前:查看某1个豆瓣电影
参数化后:查看很多个豆瓣电影
3、 了解一下E:movies.csv文件是什么?里面有什么?
E:movies.csv文件是什么:.csv文件是Jmeter参数化的文件,当并发请求时,Jmeter会读取这个文件。
E:movies.csv文件里面有什么:每1行是1个电影ID,如下图所示

4、 说明一下怎么制作这个.csv文件
a) 新建1个写字板文件
b) 第1行写1条数据
c) 第2行写1条数据
d) 保存
e) 将.txt后缀修改为.csv
[ 备注:当.csv文件需要有上百条数据,需要使用脚本语言自己写,或者由开发人员协助生成这个.csv格式的文件 ]
5、 重点说明一下"错误的"制作.csv文件的方式
a) 新建1个Excel文件
b) 第1行写1条数据,第2行写1条数据,保存
c) 将.xls后缀修改为.csv
因为Excel会涉及文本的样式、编码等东西,所以当最终将.xls保存为.csv后,在运行Jmeter的时候,参数化的东西读取存在乱码,那么就会造成HTTP404。
6、 说明一下CSVRead函数的意思
参数化后:/subject/${__CSVRead(E:movies.csv,0)}${__CSVRead(E:movies.csv,next)}/
意思是:Jmeter从E:movies里面的第0行开始读数据,读完第0行接着读下一行。
7、 看看Request这个参数化了的URL是否写对了
//因为有2个电影ID嘛,所以我们可以将“线程组-线程数”设置是2



第3个步骤:在Windows把构建的这个测试脚本转化为用在Linux的测试脚本
1. 建议新建1个一模一样的测试脚本
这么做的目的是:减轻工作量,事半功倍。
2. 命名方式
testPlanForWindows.jmx //第1个步骤、第2个步骤均使用了这个测试脚本,使用的是同一个测试脚本
testPlanForLinux.jmx //第3个步骤需要新建1个测试脚本,命名为"testPlanForLinux.jmx"
3.testPlanForLinux.jmx有哪些不一样的地方
a) 线程组
//注意:我们当前执行的修改,都是在1个新的测试脚本内操作的,即:testPlanForLinux.jmx

b) HTTP请求
我们去掉了E:,因为在Linux是没有E:这个路径的。
由于我们会将moives.csv上传到远程Linux服务器的“Jmeter安装文件”的bin目录下(即:与Jmeter可执行文件是同一级目录),那么所以我们直接去掉E:就可以了。

c) 聚合报告
"文件名":../../result/testResult.csv
"Configure":保留如下5项
Save Filed Names(CSV):结果文件以CSV的形式保存
Save Response Code:保存返回值,比如http的200、4xx、5xx //如果是4xx,首先去检查hosts文件是否配置ok了。如果是5xx,去找开发问问是不是在nginx里deny了测试机的请求,是的话把测试机ip加到服务器的配置文件里。
Save Time Stamp:每一条服务器的响应显然对应了一个本地的时间,比如现在是2014年4月24号11:17,那么在这条响应的旁边显示了201404241117
Save Latency:保存请求被服务器响应的时间,比如20毫秒、50毫秒、100毫秒
Save URL:保存测试机向服务器发送的请求,完整记录下来,有利于检查拼接的URL是不是正确的,有没有失误导致URL多了一个空格或者少了什么

至此,接下来就可以将testPlanForLinux.jmx和movies.csv上传到远程Linux测试机了,上传的目录是Jmeter安装文件的bin目录下。然后就可以在Linux使用Jmeter做性能测试了。(具体操作我仍然会输出1个文档)