一 运算符
1. 算数运算符
以下假设变量: a=10,b=20:

2. 比较运算符
以下假设变量a为10,变量b为20:

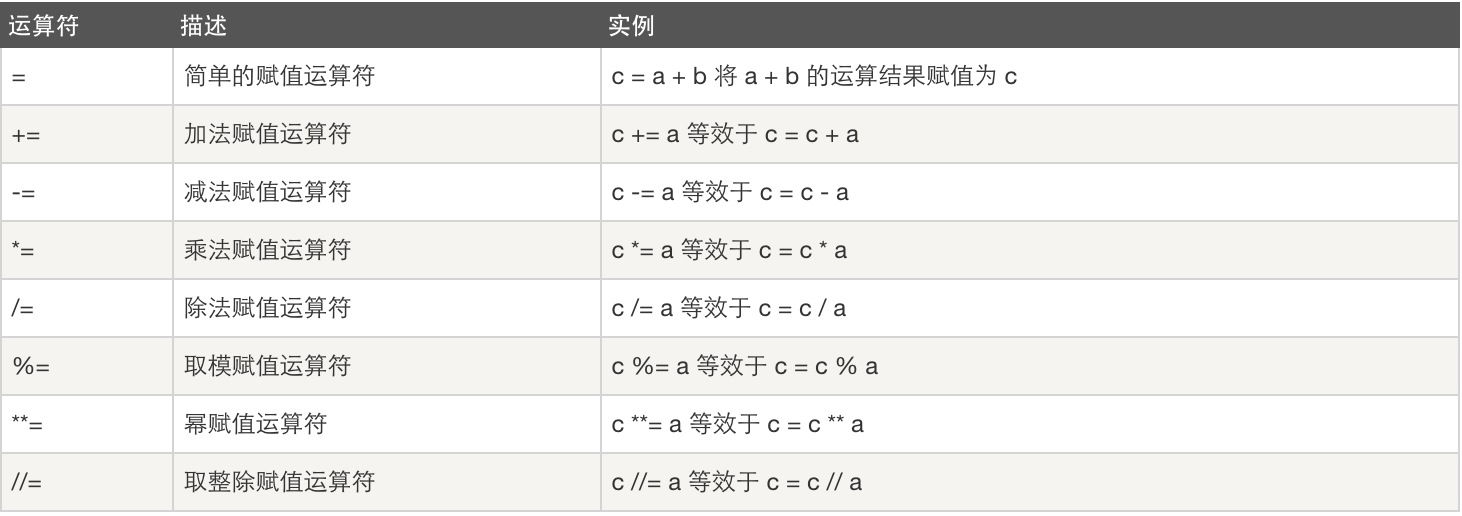
3. 赋值运算符
4. 逻辑运算符
以下假设变量 a 为 10, b为 20

and 改写为:如果x为False,x and y返回 x值 ,否则返回y值
记忆规律:在 x and/or y 中,整体的返回值一般不是True和False,而是x或者y值, 第一步都是看x。
print(1 and 0)
print(0 and 1)
print('' and 2)
print(2 or 0)
print(0 or 2)
结果为:
0;0; ; 2;2
运算顺序为: 顺序: () ==> not ==> and ==> or
print(not 2 >1 and 3<4 or 4>5 and 2>1 and 9<8 or 7<6)
False
5. 成员运算符

6. 身份运算符
身份运算符用于比较两个对象的存储单元

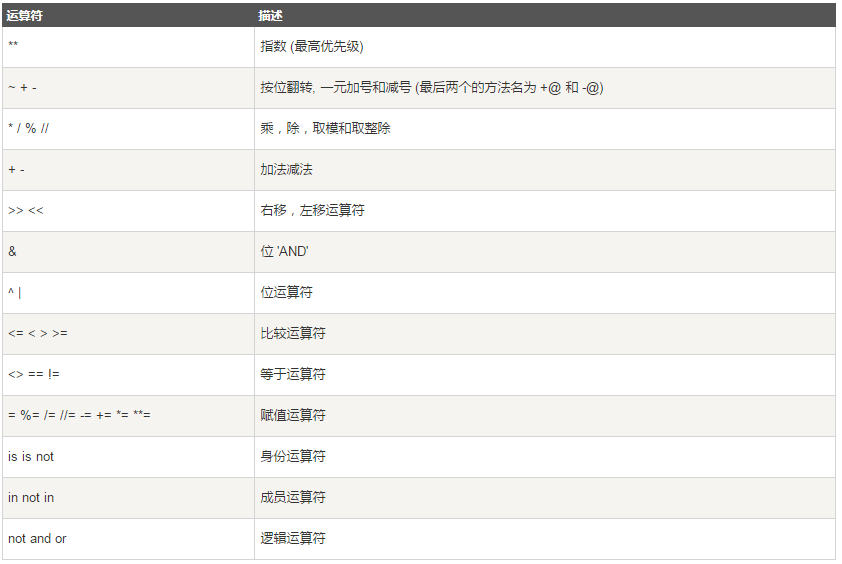
7. 运算符优先级
以下表格列出了从最高到最低优先级的所有运算符:
参考
运算符详解:
https://www.runoob.com/python3/python3-basic-operators.html
二 数据类型之间转换
int(x [,base ]) 将x转换为一个整数
long(x [,base ]) 将x转换为一个长整数
float(x ) 将x转换到一个浮点数
complex(real [,imag ]) 创建一个复数
str(x ) 将对象 x 转换为字符串
repr(x ) 将对象 x 转换为表达式字符串
eval(str ) 用来计算在字符串中的有效Python表达式,并返回一个对象
tuple(s ) 将序列 s 转换为一个元组
list(s ) 将序列 s 转换为一个列表
chr(x ) 将一个整数转换为一个字符
unichr(x ) 将一个整数转换为Unicode字符
ord(x ) 将一个字符转换为它的整数值
hex(x ) 将一个整数转换为一个十六进制字符串
oct(x ) 将一个整数转换为一个八进制字符串
三 数字(Number)
在Python3中,支持的数字类型有:
- int--整型
- float--浮点型
- fractions--分数
- complex--复数
1. 数值内部方法
####内部方法为该数据类型内部的方法,内置函数为系统的内置方法####
var.bit_length() 求二进制长度
a= 3 print(a.bit_length()) #必须通过变量调用
2
2. 数值内置函数
1,abs(x) 求x的绝对值
2,divmod(x,y) 相当于%,divmod(10,3)结果是(3,1)也就是商3余1
3,pow(x,y[,z]) 函数表示x的y次方,如果由参数z则表示x的y次方,然后用x进行模运算之后的余数,即幂余函数,这是为了防止x,的y次幂太大导致计算机无法工作,而经常需要的
只是后几位而已
4,round(x[,d]) 表示对x进行四舍五入,精度默认为0,d代表去小数点后第d位,四舍五入
5,max( ) 返回给定参数的最大值,参数可以为序列
6,min( ) 返回给定参数的最小值,参数可以为序列
7,int(x) 取整函数,把参数,不论是小数,还是字符串都可以,转换成整数
8,float(x) 可以把参数转换成浮点数,如果是整数的话,则设置小数点后一位为0,如果是字符串则直接转换为浮点数
参考
math及cmath模块更多数值运算函数:
https://www.runoob.com/python/python-numbers.html
四 布尔(Bool)
布尔只有两个值:True和False
只有一个方法 bool()
与False对应的值都有:None、 [ ]、( )、" "、{ }、0
五 字符串(String)
sequence(序列)是内置数据类型(Built-in type),可迭代对象,包含list、str、tuple、range、bytes。而dict则是一种map(映射)
population:Population must be a sequence or set. For dicts, use list(d)
python中字符串是不可变对象,所以所有修改和生成字符串的操作的实现方法都是另一个内存片段中新生成一个字符串对象。例如,'abc'.upper()将会在划分另一个内存片段,并将返回的ABC保存在此内存中。
1. 大小写转换
1、 S.upper() 把所有字符中的小写字母转换成大写字母
2、 S.lower() 把所有字符中的大写字母转换成小写字母
3、 S.capitalize() 首字母大写
4、 S.title() 所有单词首字母大写
5、 S.swapcase() 所有字符串做大小写转换(大写-->小写,小写-->大写)
2. is判断
6、 S.isdecimal() 如果字符串是否只包含十进制字符返回True,否则返回False。
7、 S.isalpha() 判断是否都是字母
8、 S.isdigit() 判断是否都是整数
1 >>> '8.35'.isdigit() 2 False
9、 S.isnumeric() 判断是否都是数字
isdigit isdecimal isnumeric的区别
https://zhidao.baidu.com/question/496610701775817084.html
10、S.isalnum() 检测字符串是否由字母和数字组成。
1 >>> 'a8Yn9'.isalnum() 2 True
11、 S.islower() 判断是否都是小写
12、S.isupper() 判断是否都是大写
13、S.istitle() 是否符合符合标题
14、S.isspace() 是否是空白(空格、制表符、换行符等)字符
15、S.isprintable 是否是可打印字符(例如制表符、换行符就不是可打印字符,但空格是)
16、S.isdentifer() 是否满足标识符定义规则
标识符定义规则为:只能是字母或下划线开头、不能包含除数字、字母和下划线以外的任意字符
3. 填充
17、S.center(width[, fillchar])
1 >>> name = 'matt' 2 >>> name.center(50,'-') 3 '-----------------------matt-----------------------'
18、S.ljust(width[, fillchar]) 使用fillchar填充在字符串S的右边,使得整体长度为width
19、S.rjust(width[, fillchar]) 填充在左边。如果不指定fillchar,则默认使用空格填充
20、S.zfill(width) 用0填充在字符串S的左边使其长度为width
4. 检索
21、S.count(sub[, start[, end]]) 返回字符串S中子串sub出现的次数,可以指定从哪里开始计算(start)以及计算到哪里结束(end)
22、S.endswith(suffix[, start[, end]]) endswith()检查字符串S是否以suffix结尾,返回布尔值的True和False。suffix可以是一个元组(tuple),只要tuple中任意一个元素满足endswith的条件,就返回True。
23、S.startswith 判断字符串S是否是以prefix开头
24、S.find(sub[, start[, end]]) 搜索字符串S中是否包含子串sub,如果包含,则返回sub的索引位置,否则返回"-1"。
25、S.rfind(sub[, start[, end]]) 返回搜索到的最右边子串的位置
26、S.index(sub[, start[, end]]) 和find()一样,唯一不同点在于当找不到子串时,抛出ValueError错误
27、S.rindex(sub[, start[, end]]) 返回搜索到的最右边子串的位置
5. 替换
28、S.replace(old, new[, count]) 将字符串中的子串old替换为new字符串,如果给定count,则表示只替换前count个old子串。如果S中搜索不到子串old,则无法替换,直接返回字符串S(不创建新字符串对象)。
1 >>> 'abcandabc'.replace('abc','matt') 2 'mattandmatt'
29、S.expandtabs(N) 将字符串S中的 替换为一定数量的空格。默认N=8。
30、S.translate(table) 和 str.maketrans(x[, y[, z]]) str.maketrans()生成一个字符一 一映射的table,然后使用translate(table)对字符串S中的每个字符进行映射。
1 >>> str_in = 'abcxyz' 2 >>> str_out = '123456' 3 >>> transtab = str.maketrans(str_in,str_out) 4 >>> 'i am matt'.translate(transtab) 5 'i 1m m1tt'
maketrans 和translate是联合起来用的,加密的作用
6. 分割
31、S.partition(sep) 搜索字符串S中的子串sep,并从sep处对S进行分割,最后返回一个包含3元素的元组:sep左边的部分,sep自身素,sep右边。如果搜索不到sep,则返回的3元素元组中,有两个元素为空。
32、S.rpartition(sep) rpartition(sep)从右边第一个sep进行分割。
33、S.split(sep=None, maxsplit=-1) 都是用来分割字符串,并生成一个列表。
1 >>> 'a,b,c,d'.split(',',2) 2 ['a', 'b', 'c,d']
34、S.rsplit(sep=None, maxsplit=-1) 从右边向左边搜索
35、S.splitlines([keepends=True]) 可以指定各种换行符,常见的是 、 、
7. 拼接
36、S.join(iterable) 将可迭代对象(iterable)中的字符串使用S连接起来。注意,iterable中必须全部是字符串类型,否则报错
1 >>> '|'.join(['a','b','c']) 2 'a|b|c'
8. 修剪
37、S.strip([chars]) 移除左右两边的字符char。如果不指定chars或者指定为None,则默认移除空白(空格、制表符、换行符)
>>> ' a a '.strip() 'a a' >>> '--a-a--'.strip('-') 'a-a'
38、S.lstrip([chars])
39、S.rstrip([chars])
9.字符串拼接:
加号(+)又称为 "万恶的加号",因为使用加号连接2个字符串会调用静态函数string_concat(register PyStringObject *a ,register PyObject * b),在这个函数中会开辟一块大小是a+b的内存的和的存储单元,然后将a,b字符串拷贝进去。如果是n个字符串相连 那么会开辟n-1次内存,是非常耗费资源的。
9.1 占位符:S%s(string),S %d(digital),S %f(float)
name = 'matt'
age = 23
salary = 10000
print(''' #多行打印
---------format info------
name:%s
age:%d
salary:%d
'''%(name, age, salary))
注意:
print("我叫%s, 今年22岁了, 学习python2%%了" % '王尼玛') 我叫王尼玛, 今年22岁了, 学习python2%了
9.2 格式化输出 :S({}).format(var)
1 >>> 'my name is {}, and i am {}'.format('zt',22) #位置参数 2 'my name is zt, and i am 22' 3 >>> 'my name is {1}, and i am {0}'.format('zt',22) #位置参数 4 'my name is 22, and i am zt' 5 >>> 'my name is{name}, and i am {age}'.format(name = 'zt',age =22) #关键词参数 6 'my name iszt, and i am 22'
9.3 format_map #以字典的形式赋值
1 >>> 'my name is {name}, and i am {age}'.format_map({'name': 'zt','age':22}) 2 'my name is zt, and i am 22'
10. 字符串切片
str = '0123456789′ print str[0:3] #截取第一位到第三位的字符 print str[:] #截取字符串的全部字符 print str[6:] #截取第七个字符到结尾 print str[:-3] #截取从头开始到倒数第三个字符之前 print str[2] #截取第三个字符 print str[-1] #截取倒数第一个字符 print str[::-1] #创造一个与原字符串顺序相反的字符串 print str[-3:-1] #截取倒数第三位与倒数第一位之前的字符 print str[-3:] #截取倒数第三位到结尾 print str[:-5:-3] #逆序截取,截取倒数第五位数与倒数第三位数之间
这里需要强调的是,字符串对象是不可改变的,上面的函数改变了字符串后,都会返回一个新的字符串,原字串并没有变。
11. 遍历字符串
for 循环、 while 循环(借助len(str))
var = 'matt' for i in var : print(i) m a t t
参考:
isdigit isdecimal isnumeric的区别:
https://zhidao.baidu.com/question/496610701775817084.html
字符串操作实例:
https://www.jb51.net/article/141376.htm
六 列表(List)
1. 增
1、L.append(obj) 末尾添加
1 >>> name = ['matt', 'jordan', 'logan', 'summer'] 2 >>> name.append('tony') 3 >>> name 4 ['matt', 'jordan', 'logan', 'summer', 'tony']
2、L.insert(index, obj) 定位插入
>>> name.insert(1 ,'jump') >>> name ['matt', 'jump', 'jordan', 'logan', 'summer', 'linda', 'amy']
3、L.extend(seq) 在列表末尾一次性追加另一个序列中的多个值 与set.update()类似,
>>> name = ['matt', 'jordan', 'logan'] >>> names = ['summer', 'linda', 'amy'] >>> name.extend(names) >>> name ['matt', 'jordan', 'logan', 'summer', 'linda', 'amy']
2. 删
4、del List[index] 删除单一元素 通过索引删除 del List 删除整个列表 del list[1:4]切片删除
>>> name = ['matt', 'jordan', 'logan', 'summer', 'linda', 'amy'] >>> del name[2] >>> name ['matt', 'jordan', 'summer', 'linda', 'amy']
5、L.remove(obj) 对象
>>> name = ['matt', 'jordan', 'logan', 'summer', 'linda', 'amy'] >>> name.remove('matt') >>> name ['jordan', 'logan', 'summer', 'linda', 'amy']
6、L.pop([index=-1]) 可以指定索引,默认最后一个
>>> name = ['matt', 'jordan', 'logan', 'summer', 'linda', 'amy'] >>> name.pop() 'amy' >>> name.pop() 'linda' >>> name ['matt', 'jordan', 'logan', 'summer']
注意,list和dict在循环中禁止添加和删除,错误实例如下
name = ['matt', 'jordan', 'logan', 'summer', 'linda', 'amy'] for i in name: name.remove(i) #remove是在原列表的基础上进行的 print(name) ['jordan', 'summer', 'amy']
解决方法为新建一个空列表,在空列表中添加。
3. 改
7、L[index] = obj 只能通过索引修改
>>> name = ['matt', 'jordan', 'logan', 'summer', 'linda', 'amy'] >>> name[2] = 'mike' >>> name ['matt', 'jordan', 'mike', 'summer', 'linda', 'amy']
4. 查
8、 L.index(obj) 从列表中找出某个值第一个匹配项的索引位置,返回index
>>> name = ['matt', 'jordan', 'logan', 'summer', 'linda', 'amy'] >>> name.index('logan') 2
9、L[index] 通过索引查找对象,返回obj
5.排序
10、L.sort(cmp=None, key=None, reverse=False) 在原来列表的基础上修改,不会生成新的列表
11、L.reverse() 在原来列表的基础上修改,不会生成新的列表
>>> name = ['matt', 'jordan', 'logan', 'summer', 'linda', 'amy','1','2','3'] >>> name.sort() >>> name ['1', '2', '3', 'amy', 'jordan', 'linda', 'logan', 'matt', 'summer'] >>> name.reverse() >>> name ['summer', 'matt', 'logan', 'linda', 'jordan', 'amy', '3', '2', '1']
6. 统计
12、L.count(obj)
7. 切片
name = ['matt', 'jordan', 'logan', 'summer', 'linda', 'amy'] print(name[0:3]) #取前三个 print(name[:3]) #取前三个 print(name[2:-1]) #取第三个到最后第二个 print(name[2:]) #取第三个到最后 print(name[-2:-1]) #取倒数第二个 print(name[::3]) #每3个元素取一个
结果为:
['matt', 'jordan', 'logan'] ['matt', 'jordan', 'logan'] ['logan', 'summer', 'linda'] ['logan', 'summer', 'linda', 'amy'] ['linda'] ['matt', 'summer']
8. 赋值,浅copy,深copy
赋值(只是生产连接),L.copy() 浅copy(表层copy,下一层生成连接)和深copy(完全重建内存)
深浅copy不存在于数字,字符串中
import copy name = ['matt', 'jordan', 'logan', 'summer',['linda', 'amy'] ] name1 = name name2 = name.copy() name3 = copy.copy(name) name4 = copy.deepcopy(name) name[0] = 'MATT' name[4][0] = 'LINDA' print(name1);print(name2);print(name3);print(name4)
结果为:
['MATT', 'jordan', 'logan', 'summer', ['LINDA', 'amy']] ['matt', 'jordan', 'logan', 'summer', ['LINDA', 'amy']] ['matt', 'jordan', 'logan', 'summer', ['LINDA', 'amy']] ['matt', 'jordan', 'logan', 'summer', ['linda', 'amy']]
本方法不适用于数字和字符串
a = '2';b = a;a = 'aqs' print(b)
结果为:
2
9. 列表内置函数
1、len(list):列表元素个数
2、max(list):返回列表元素最大值
3、min(list):返回列表元素最小值
4、list(seq):将元组转换为列表
10. 列表操作符
>>> [1,2]+[3,4]
[1, 2, 3, 4]
>>> ['a']*3 ['a', 'a', 'a']
七 元组
元组可以称为只读列表
1. 元组内部方法
只有两个方法:L.count(obj) ,L.index(obj) 返回index
name = ('matt', 'jordan', 'logan', 'summer', 'linda', 'amy','amy') print(name.count('amy')) print(name.index('amy'))
2. 元组切片
name = ('matt', 'jordan', 'logan', 'summer', 'linda', 'amy','amy') print(name[1:4]) print(name) ('jordan', 'logan', 'summer') ('matt', 'jordan', 'logan', 'summer', 'linda', 'amy', 'amy')
3. 嵌套元组修改
name = ('matt', ['jordan', 'logan', 'summer'], 'linda', 'amy','amy') name[1].pop() print(name) ('matt', ['jordan', 'logan'], 'linda', 'amy', 'amy')
嵌套元组的内部元素可以修改。元组只包含一个元素时,必须加上逗号,否则不是元组。
八 字典
字典是无序的,所以先天排除重。dictionary
字典的key值必须是不可变的(可哈希的),value则没有规定
dic = {123: 456, True: 999, "id": 1, "name": 'sylar', "age": 18, "stu": ['帅哥', '美⼥'], (1, 2, 3): '麻花藤'}
可哈希:数字,字符串,元组
1. 增
1、dict[key] = value key存在就是修改,不存在就是添加
info = {'name': 'matt','age':'23', 'salary':'10000' }
info['job'] = 'it'
print(info)
结果为:
{'name': 'matt', 'age': '23', 'salary': '10000', 'job': 'it'}
2、dict.setdefault(key, default=None) 与get方法类似,如果 key 在 字典中,返回对应的值。如果不在字典中,则插入 key 及设置的默认值 default,并返回 default ,default 默认值为 None。
dict = {'Name': 'matt', 'Age': 20}
dict.setdefault('Age', 30) #返回值为20
dict.setdefault('Sex', 'F') #返回值为 F
print(dict)
结果为:
{'Name': 'matt', 'Age': 20, 'Sex': 'F'}
2. 删
3、del dict[key] 删除单一元素 没有返回值 del dict删除整个字典
4、pop(key) 删除单一元素 默认随机删除 返回值为删除的value值
5、popitem() 随机删除单一元素,返回值为删除的(key, value) ,不能删除指定key值
6、dict.clear() 清除字典
info = {'name': 'matt','age':'23', 'salary':'10000', 'job':'it' }
a = info.pop('name');print(a);print(info)
b = info.popitem();print(b);print(info)
del info['age'];print(info)
结果为:
matt
{'age': '23', 'salary': '10000', 'job': 'it'}
('job', 'it')
{'age': '23', 'salary': '10000'}
{'salary': '10000'}
3. 改
同添加 dict[key] = value key存在就是修改,不存在就是添加
info = {'name': 'matt','age':'23', 'salary':'10000', 'job':'it' }
info['name'] = 'logan'
print(info)
结果为:
{'name': 'logan', 'age': '23', 'salary': '10000', 'job': 'it'}
4. 查
7、dict[key] key值存在,返回value值,key值不存在,报错
8、 dict. get(key , default = None),访问字典中对应的键里的值,如不存在该键返回default的值
9、dict.has_key(key):如果键在字典dict里返回true,否则返回false 与in类似
info = {'name': 'matt','age':'23', 'salary':'10000', 'job':'it' }
print('name' in info)
print(info.get('name'))
print(info['name'])
结果为:
True;matt;matt
5. 遍历字典
10、dict.keys() 以列表返回一个字典所有的键
11、dict.values() 以列表返回字典中的所有值
12、dict.item() 以列表返回可遍历的(键, 值) 元组数组 ;会先把dict转成list,数据里大时莫用;类似于enumerate,返回的都是元组,然后一般在解包,enumerate一般用于list
info = {'name': 'matt', 'age': '23', 'salary': '10000', 'job': 'it'}
for i in info: #与for i in info.keys():相同
print(i, end=' ')
print()
for i in info.values():
print(i, end=' ')
print()
for i, j in info.items(): 类似于enumerate
print(i, j, end=', ')
结果为:
name age salary job
matt 23 10000 it
name matt, age 23, salary 10000, job it,
6. 字典其余函数
13、dict.update(dict2) 把字典dict2的键/值对更新到dict里,相当于字典拼接。无返回值,在dict的基础上拼接
info = {'name': 'matt', 'age': '23'}
info2 = {'salary': '10000', 'job': 'it'}
print(info.update(info2))
print(info)
print(info2)
结果为:
None
{'name': 'matt', 'age': '23', 'salary': '10000', 'job': 'it'}
{'salary': '10000', 'job': 'it'}
14、dict.copy() 返回一个字典的浅复制
15、dict.fromkeys():创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值
>>> dict.fromkeys([1,2,3],'testd') {1: 'testd', 2: 'testd', 3: 'testd'}
7. 字典内置函数
1、len(dict):计算字典元素个数,即键的总数。
2、str(dict):输出字典可打印的字符串。
3、type(variable):返回输入的变量类型,如果变量是字典就返回字典类型。
九 集合
set() 中的元素是不重复的,无序的。内部的元素必须是可hash的(int, str, tuple,bool), 我们可以这样来记. set就是dict类型的数据,但是不保存value, 只保存key。
set是可迭代对象
利用set()不重复的特性,给list()去重
# 给list去重复 lst = [45, 5, "哈哈", 45, '哈哈', 50] lst = list(set(lst)) # 把list转换成set, 然后再转换回list print(lst) [5, '哈哈', 50, 45]
1. 增
1、set.add(obj) add添加单个元素
2、set.update(set) update添加时首先生成set,然后再合并,类似于dict.update(dict2) 和 list.extend(seq)
s = {"刘嘉玲", '关之琳', "王祖贤"}
s.add(("郑裕玲",'张曼玉'))
print(s)
s.add("刘嘉玲") # 重复的内容不会被添加到set集合中
print(s)
s = {"刘嘉玲", '关之琳', "王祖贤"}
s.update("麻花藤") # 迭代更新
print(s)
s.update(["张曼", "李若彤","李若彤"])
print(s)
{'王祖贤', '刘嘉玲', '关之琳', ('郑裕玲', '张曼玉')}
{'王祖贤', '刘嘉玲', '关之琳', ('郑裕玲', '张曼玉')}
{'藤', '麻', '花', '王祖贤', '刘嘉玲', '关之琳'}
{'藤', '李若彤', '麻', '张曼', '花', '王祖贤', '刘嘉玲', '关之琳'}
2. 删
3、set.pop() 因为set没有索引,只能随机删除一个
4、set.remove(obj) 删除指定元素 删除不存在的元素会报错
5、set.discard() 删除集合中指定的元素 删除不存在的元素啥都不做
6、set.clear() 清空,最后的打印结果为:set()
s = {"刘嘉玲", '关之琳', "王祖贤","张曼", "李若彤"}
item = s.pop() # 随机弹出1个.
print(s)
print(item)
s.remove("关之琳") # 直接删除元素
# s.remove("疼") # 不存在这个元素. 删除会报错
print(s)
s.clear() # 清空set集合.需要注意的是set集合如果是空的. 打印出来是set() 因为要和dict区分的.
print(s) # set()
#discard() 删除集合中指定的元素 删除不存在的元素啥都不做
boys = {'bd','zw','jl','zy'}
boys.discard('zy1')
print(boys)
3. 改
set集合中的数据没有索引. 也没有办法去定位元素.。所以没有办法进行直接修改。我们可以采用先删除后添加的方式来完成修改操作。
s = {"刘嘉玲", '关之琳', "王祖贤","张曼⽟", "李若彤"}
# 把刘嘉玲改成赵本⼭
s.remove("刘嘉玲")
s.add("赵本⼭")
print(s)
4. 遍历集合
set是可迭代对象
s = {"刘嘉玲", '关之琳'}
for el in s:
print(el)
5. 集合操作
7、set.copy() 浅复制
#copy() 复制集合 boys = {'bd','zw','jl','zy'} newboys = boys.copy() print(newboys)
#集合推导式 var = {'蚂蚱','螳螂','蝈蝈','蛐蛐'} #基本的集合推导式 result = {'*'+i+'*' for i in var} print(result) #带有判断条件的集合推导式 result = {i for i in var if i != '蛐蛐'} print(result) #多循环集合推导式 colors = {'red','blue','pink'} sizes = {36,37,38,39} result = {c + str(s) for c in colors for s in sizes} print(result)
#difference() 计算2个集合的差集 dreamers = {'ljl','wc','xy','zb','lsy'} girls = {'mmf','lsy','syj'} result = dreamers.difference(girls)# result = a + b print(result) #difference_update() 计算2个集合的差集(差集更新操作) dreamers = {'ljl','wc','xy','zb','lsy'} girls = {'mmf','lsy','syj'} dreamers.difference_update(girls)#a = a + b a += b print(dreamers) #union() 并集操作 dreamers = {'ljl','wc','xy','zb','lsy'} girls = {'mmf','lsy','syj'} result = dreamers.union(girls) print(result) #update() 并集更新操作 dreamers = {'ljl','wc','xy','zb','lsy'} girls = {'mmf','lsy','syj'} dreamers.update(girls) print(dreamers) #intersection() 计算2个集合的交集 dreamers = {'ljl','wc','xy','zb','lsy'} girls = {'mmf','lsy','syj'} result = dreamers.intersection(girls) print(result) #intersection_update 交集更新操作 dreamers = {'ljl','wc','xy','zb','lsy'} girls = {'mmf','lsy','syj'} dreamers.intersection_update(girls) print(dreamers) #超集和子集 boys = {'zzy','yqw','dw','wzc','lyb','wym','chy'} zoudu = {'wzc','lyb','wym'} girls = {'lsy','mmf','syj'} #issuperset() 检测当前集合是否是另一个集合的超集 result = boys.issuperset(zoudu) print(result) #issubset() 检测当前集合是否是另一个集合的子集 result = zoudu.issubset(boys) print(result) #isdisjoint() 检测2个集合是否不存在交集 存在交集 False result = boys.isdisjoint(girls) print(result) #symmetric_difference() 对称差集 dreamers = {'ljl','wc','xy','zb','lsy'} girls = {'mmf','lsy','syj'} result = dreamers.symmetric_difference(girls) print(result) #symmetric_difference_update() 对称更新差集 dreamers = {'ljl','wc','xy','zb','lsy'} girls = {'mmf','lsy','syj'} dreamers.symmetric_difference_update(girls) print(dreamers)
6. 冰冻集合
set集合本是可以发生改变的,是不可hash的. 我们可以使用frozenset来保存数据。
frozenset 是不可变的. 也就是一个可哈希的数据类型 。
s = frozenset(["赵本", "刘能", "哈哈", "跪"]) dic = {s:'123'} # 可以正常使用 print(dic)
#冰冻集合 #冰冻集合是一种特殊的集合类型,也是集合(集合是列表的话,冰冻集合就是元组) #创建冰冻集合 #一般不会创建空的冰冻集合 var = frozenset() print(var,type(var)) #带有数据的冰冻集合 var = frozenset(('qs','szx','bjh','acs')) print(var,type(var)) #成员检测 result = 'szx' in var print(result) #遍历冰冻集合 for i in var: print(i) #集合推导式(无法得到冰冻集合,可以得到集合,列表,元组,字典类型) result = {i for i in var} print(result,type(result)) #函数 #冰冻集合可以使用集合的函数(不修改集合本身的函数都可以使用) var = frozenset(('qs','szx','bjh','acs')) #copy() result = var.copy() print(result) #集合操作 交集,并集,差集,对称差集等 不修改冰冻集合本身就能使用:冰冻集合的操作结果都是冰冻集合 var1 = frozenset(('qs','szx','bjh','acs')) var2 = {'szx','bjh','lc','wb'} #冰冻集合操作 result = var1.union(var2) print(result) #普通集合操作(冰冻集合是参考集合) result = var2.union(var1) print(result)
十 小数据池
1. is 与 == 的区别
通过id()可以查看到一个变量表示的值在内存中的地址
- ==:判断左右两端的值是否相等
- is:判断左右两端内容的内存地址是否一致。如果返回True,那可以确定这两个变量使用的是同一个对象
a = 100 b = 100 print(a is b) # True print(a == b) # True a = 1000 b = 1000 print(a == b) # True print(a is b) # False 在command命令下为False, 在.py文件中(例如pycharm中)得到的结果为True。(每一行cmd命令都是一个代码块)
代码帮助理解
a = 10 print(id(a)) print(id(10)) print(a is 10) print(a == 10) 8791375307696 8791375307696 True True
2. 代码块
Python程序是由代码块构造的,它是作为一个单元执行的。
一个代码块可以:
- 一个函数(function)
- 一个类(class)的多个实例
- 每一行command命令
- eval()
- exec()

3. 代码块缓存机制
前提条件:在同一代码块中
机制内容:执行同一个代码块时,遇到初始化对象的命令时,他会将初始化的这个变量与值存储在一个字典中,再遇到新的初始化对象命令时,先在字典中查询其值是否已经存在,如果存在,那么它会重复使用这个字典中的之前的这个值。即两变量指向同一个内存地址。如果是不同的代码块,则判断这两个变量是否满足小数据池的数据,如果满足,则两变量指向同一个地址。如果不满足,则得到两个不同的对象,即两变量指向的是不同的内存地址。
如果在同一代码块下,则采用同一代码块下的换缓存机制。如果是不同代码块,则采用小数据池的驻留机制。
注意:对于同一个代码块,只针对单纯创建变量,才会采用缓存机制,对于创建变量并同时做相关运算,则无。
a = 1000 b = 1000 print(id(a)) # 2135225709680 print(id(b)) # 2135225709680 print(a is b) # True .py文件运行 a = 1000 b = 10*100 print(id(a)) # 1925536396400 print(id(b)) # 1925536643952 print(a is b) # False .py文件运行
适用对象: int(float),str,bool
具体细则:
- int(float): 任何数字在同一代码块下都会复用;
- bool: True和False在字典中会以1,0方式存在,并且复用;
- str:几乎所有的字符串都会符合缓存机制,具体规定如下:
- 非乘法或乘数为1时,得到的字符串都满足代码块的缓存机制;
- 乘数>=2时:仅含大小写字母,数字,下划线,总长度<=20,满足代码块的缓存机制。
4. 小数据池
小数据池,不同代码块的缓存机制,也称为小整数缓存机制,或者称为驻留机制等等
前提条件:在不同一个代码块内。
适用对象: int(float),str,bool
具体细则:
- int(float):-5~256会被加到小数据池中,每次使用都是同一个对象。
- str:
- 如果字符串的长度是0或者1,包含特殊字符,都会默认进行缓存。(中文字符无效)
- 字符串长度大于1,但是字符串中只包含数字,字母,下划线时会被缓存。(特殊字符无效)
- 乘数大于1,仅包含数字,字母,下划线时会被缓存,但字符串长度不能大于20
内存缓存机制处理的数字和字符串范围更大
优点:能够提高字符串、整数的处理速度。省略了创建对象的过程。
缺点:在"池"中创建或者插入新的内容会花费更多的时间。
a = 5*5 b = 25 print(id(a)) # 1592487712 print(id(b)) # 1592487712 print(a is b) # True a = "Incomputer science, string interning is a method of storing only onecopy of each distinct string value" b = "Incomputer science, string interning is a method of storing only onecopy of each distinct string value" print(id(a)) # 2926961023256 print(id(b)) # 2926961023256 print(a is b) # True .py文件运行 def func(): i1 = 1000 print(id(i1)) # 2288555806672 def func2(): i1 = 1000 print(id(i1)) # 2288557317392
def func():
i1 = 100
print(id(i1)) # 8791514836720
def func2():
i1 = 100
print(id(i1)) # 8791514836720
5 . 指定驻留
可以通过sys模块中的intern()函数来指定要驻留的内容。(详情见sys模块相关内容)
from sys import intern a = intern('hello!@'*20) b = intern('hello!@'*20) print(a is b) #指定驻留是你可以指定任意的字符串加入到小数据池中,让其只在内存中创建一个对象,多个变量都是指向这一个字符串。
True