语言制导翻译器(嗯,总体介绍~)
//重点介绍前端(分析阶段):词法分析、语法分析、中间代码生成。
编译器在分析阶段,编译器把源程序划分为几个部分,并生成源程序的内部表示形式,称为中间代码。综合部分把中间代码转换成目标程序。
编译器前端模型:
分析阶段的工作都围绕“语法”展开。
程序设计语言的语法描述了该程序的正确形式,而语言的语义则定义了程序的含义,即每个程序在运行时做什么事情。描述语法的方法可以是上下文无关法。
上下文无关法不仅可以描述一个语言的语法,还可以指导程序的翻译过程。
先介绍语法分析器:
语法分析器可以处理多个字符组成的构造,比如标识符。但是标识符在语法分析阶段被当作一个单元进行处理,这样的单元称作词法单元(token)。
中间代码生成器:
语法定义:
语言(自然语言或形式语言)的语法是句子/程序中的单词可以排列的方式。
举个栗子:C语言的if语句的规则
![]()
这条产生规则表示要构造一个C语言的if语句,必须输入
一个if,然后
一个左括号(,然后
一个某种表达式,然后
一个右括号),最后
某种语句。
文法的作用
产生句子:当前文法G能产生哪些句子?
语法分析:某个句子S是否能由当前文法G产生?

句子的产生流程:
从开始符号出发,
选择一个非终结符号X,
选择一条语法规则X→![]()
用![]() 代替X,
代替X,
重复2~4,直到得到单词串。
上下文无关文法(context-free grammar, CFG)
简称文法,用于描述程序设计语言的语法,可以自然地描述大多数程序设计语言构造的层次化语法结构。
基本概念:产生式,终结符号,非终结符号。不赘述,嗯~ o(* ̄▽ ̄*)o。

推导:
根据文法推导符号串:
从开始符号出发,不断将符号串中的某个非终结符号替换为该非终结符号的某个产生式的右部,得到新的符号串。
可以从开始符号推导得到的所有终结符号串的集合称为该文法定义的语言。
语法分析的任务:
接受一个终结符号串作为输入,找出从文法的开始符号推导出这个串的方法,如果输入串不能从开始符号推导出,则报告语法错误。
语法分析树是符号串推导过程的图形表示:
如果非终结符号A有一个产生式A→XYZ,那么在语法分析树上就可能有一个标号为A的内部结点,该结点有三个子结点,从左向右分别标号为X、Y、Z。
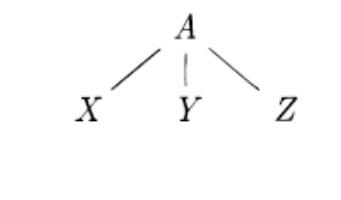
给定一个上下文无关文法,该文法的一棵语法分析树是具有以下性质的树:
根结点的标号为文法的开始符号
每个叶子结点的标号为一个终结符号或ε
每个内部结点的标号为一个非终结符号
如果非终结符号A是某个内部结点的标号,并且它的子结点的标号从左至右分别为X1,X2,…,Xn,那么必然存在产生式A→X1X2…Xn,其中X1,X2,…,Xn既可以是终结符号,也可以是非终结符号。特别地,如果A→ε是一条产生式,那么一个标号为A的结点可以只有一个标号为ε的子结点。

一个文法的语言的另一个定义
任何能够由某棵语法分析树生成的符号串的集合
一棵语法分析树的叶子结点从左向右构成了树的结果
语法分析
为一个给定的终结符号串构建一棵语法分析树的过程称为对该符号串进行语法分析
自顶向下(自上而下)的语法分析,
自底向上(自下而上)的语法分析。
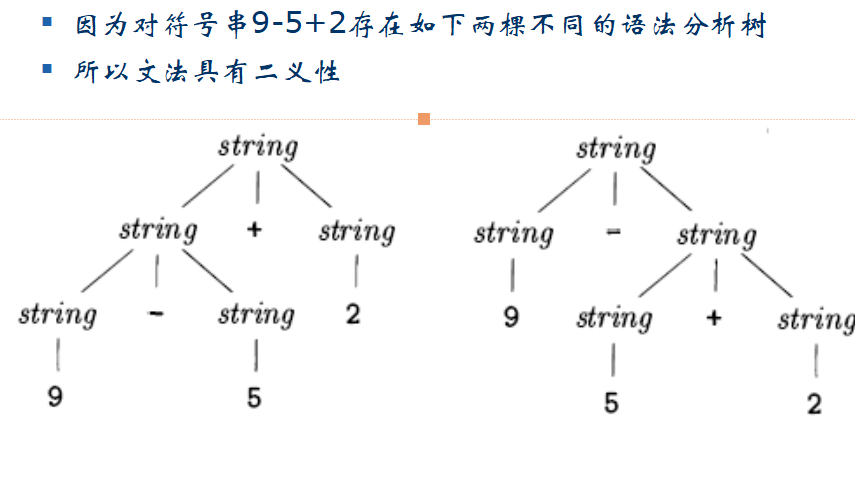
文法的二义性(ambiguity)
如果一个文法可能有多棵语法分析树能够生成同一个给定的终结符号串,这样的文法称为是有二义性的(ambiguous)
二义性的证明
找到一个终结符号串,说明它是两棵以上语法分析树的结果。
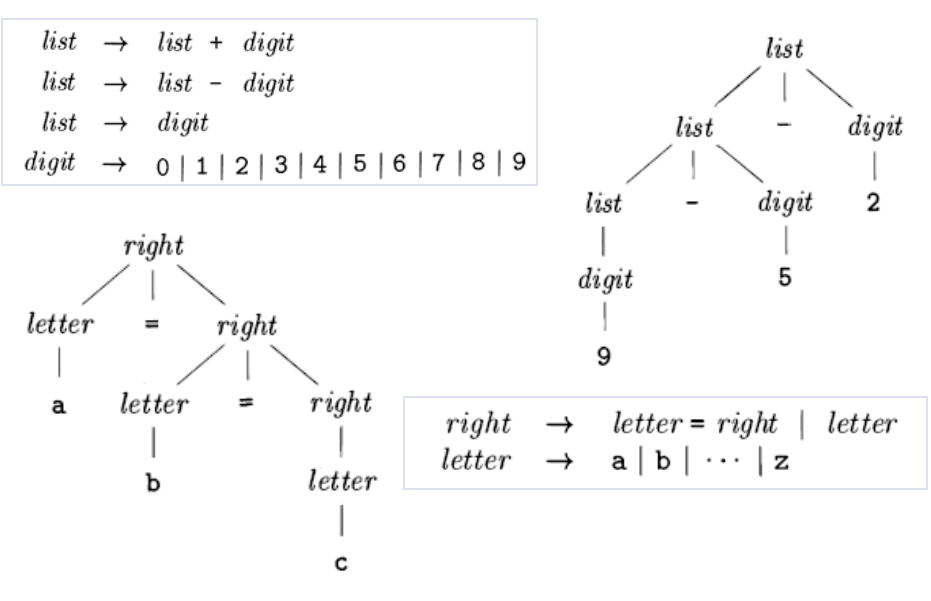
结合性
当一个运算分量的左右两侧都有运算符时,我们需要规则来决定哪个运算符被应用于该运算分量
9+5+2,5的左右都是+运算符
左结合
四则运算的+,-,*,/都是左结合的
右结合
C语言的赋值运算符是右结合的,例如a=b=c
幂运算是右结合的
产生左结合和右结合运算的文法。
优先级
当多种运算符出现时,我们需要给出一些规则来定义运算符之间的相对优先关系。
注:文法并没有要求结合性和优先级。

语言制导翻译:
语法制导翻译是通过向一个文法的产生式附加一些规则或程序片段而得到的。

属性(attribute):
表示与某个程序构造相关的任意量。表达式的数据类型、生成的代码中的指令数目、为某个构造生成的代码中的第一条指令的位置。因为用文法符号表示程序构造,所以将属性的概念扩展到表示这些构造的文法符号上。
语法制导的翻译方案(translation scheme):
翻译方案是一种将程序片段附加到一个文法的各个产生式上的表示法,在语法分析过程中使用一个产生式时,相应的程序片段就会执行。这些程序片段的执行效果按照语法分析(构造的语法树遍历)过程的顺序组合起来,得到的结果就是这次分析/综合过程处理源程序得到的翻译结果。
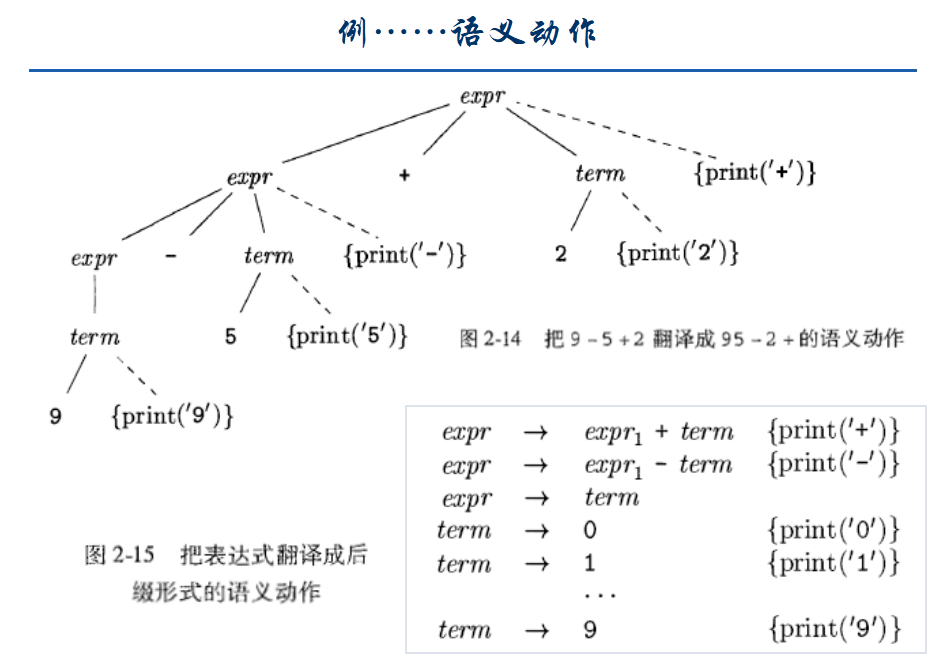
一个表达式E的后缀表示可以按照下面的方式归纳定义:
如果E是一个变量或常量,则E的后缀表示是E本身,
如果E是一个形如E1 op E2的表达式(中缀形式),其中op是一个二元运算符,那么E的后缀表示是E1' E2' op,其中E1' 和E2'分别是E1和E2的后缀表示,
如果E是一个形如(E1)的表达式,则E的后缀表示就是E1的后缀表示,
后缀表示的特点,
不需要括号,
运算分量就在运算符的左边,运算符出现的次序就是计算次序。
语法制导定义(syntax-directed definition, SDD):
把每个文法符号和一个属性集合相关联,把每个产生式和一组语义规则相关联,这些规则用于计算与该产生式中符号相关的属性值。
属性的求值:
对一个给定输入串x,构建x的一个语法分析树,假设语法分析树的一个结点N的标号为文法符号X,用X.a表示该结点上X的属性a的值,遍历语法分析树,对遍历的结点的属性求值。
注释(annotated)语法分析树:
如果一棵语法分析树的各个结点上标记了相应的属性值,那么这棵语法分析树就称为注释分析树。
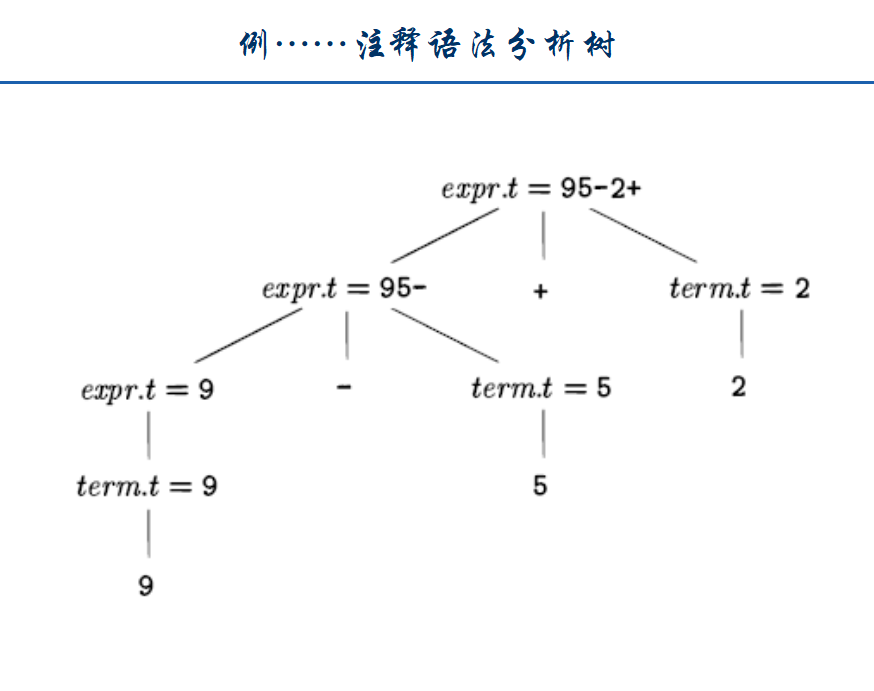
综合属性(synthesized attribute):
如果某个属性在语法分析树结点N上的值是由N的子结点以及N本身的属性值确定的,那么这个属性就称为综合属性。
只需要对语法分析树进行一次自底向上的遍历,就可以计算出综合属性的值。
继承属性(inherited attribute):
继承属性在某个语法分析树结点上的值是由语法分析树中该结点本身、父结点以及兄弟结点上的属性值决定的。
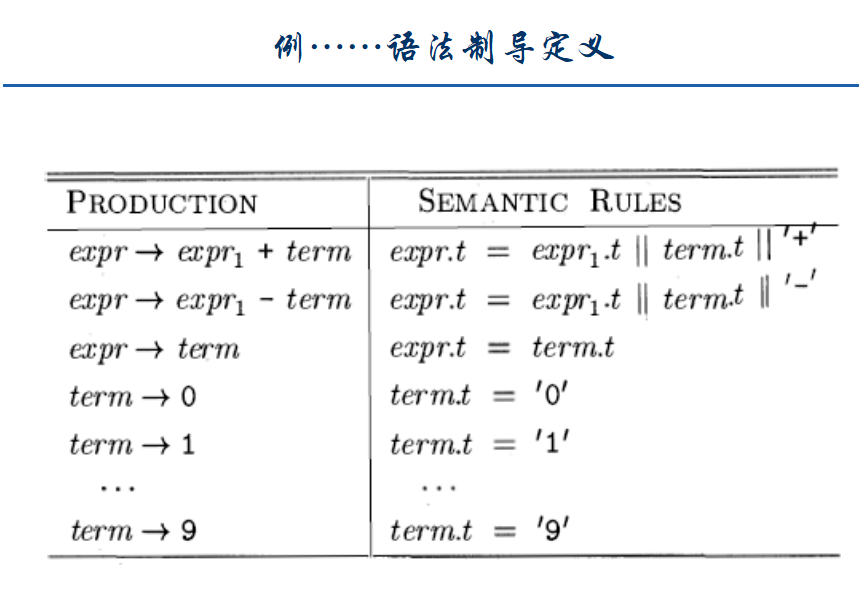
具有以下性质的语法制导定义称为简单语法制导定义:
要得到代表产生式左部的非终结符号的翻译结果的字符串,只需要将产生式右部中各非终结符号的翻译结果按照它们在非终结符中的出现顺序连接起来,并在其中穿插一些附加的串即可
简单语法制导定义的实现简单
按照在定义中出现的次序打印出附加的串即可。
树的遍历在语法制导翻译中的作用
描述属性的求值过程
描述一个翻译方案中各个代码片段的执行过程
树的遍历(traversal)
从根结点开始,按照某个顺序访问树的各个结点
属性求值的顺序
语法制导定义没有规定一棵语法分析树中各个属性值的计算顺序
综合属性可以在自底向上遍历时计算
即在所有子结点的属性值计算完成之后计算该结点的属性值
继承属性的计算更复杂。

语法制导翻译方案
是一种在文法产生式中附加一些程序片段来描述翻译结果的表示方法
与语法制导定义的区别是显式指定了语义规则的计算顺序
语义动作(semantic action)
嵌入到产生式右部的程序片段
用花括号括起,嵌入产生式右部,嵌入的位置指定了执行位置
在语法分析树上构造一个子结点,用虚线和产生式左部符号的结点相连。