1.Spark SQL 基本操作
将下列 json 数据复制到你的 ubuntu 系统/usr/local/spark 下,并保存命名为 employee.json。
{ "id":1 ,"name":" Ella","age":36 }
{ "id":2,"name":"Bob","age":29 }
{ "id":3 ,"name":"Jack","age":29 }
{ "id":4 ,"name":"Jim","age":28 }
{ "id":5 ,"name":"Damon" }
{ "id":5 ,"name":"Damon" }
首先为
employee.json 创建 DataFrame,并写出 Scala 语句完成下列操作:
创建 DataFrame

查询 DataFrame 的所有数据:
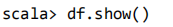
查询所有数据,并去除重复的数据:

查询所有数据,打印时去除 id 字段:

筛选 age>20 的记录:

将数据按 name 分组:

将数据按 name 升序排列:
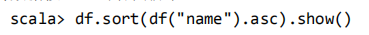
取出前 3 行数据:
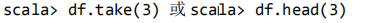
查询所有记录的 name 列,并为其取别名为 username:

查询年龄 age 的平均值:
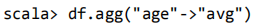
查询年龄 age 的最小值:
