Hadoop快速入门
Hadoop简介
Hadoop编年史
(1)2002年10月,Doug Cutting和Mike Cafarella创建了开源网页爬虫项目Nutch。
(2)2003 年 Google 发表了一篇技术学术论文关于 Google 文件系统(GFS)。GFS 也就是 Google File System,是 Google 公司为了存储海量搜索数据而设计的专用文件系统。
(3)2004年7月,Doug Cutting和Mike Cafarella在Nutch中实现了类似GFS的功能,即后来HDFS的前身。
(4)2004年 Google 又发表了一篇技术学术论文,向全世界介绍了 MapReduce。2005年 Doug Cutting 又基于 MapReduce,在 Nutch 搜索引擎实现了该功能。
(5)2005年2月,Mike Cafarella在Nutch中实现了MapReduce的最初版本。
(6)2006年1月,Doug Cutting加入Yahoo!(雅虎)。Doug Cutting 将 NDFS 和MapReduce 升级命名为 Hadoop,Hadoop正式诞生!Yahoo! 开建了一个独立的团队给 Goug Cutting 专门研究发展 Hadoop。
(7)2006年2月,Apache Hadoop项目正式启动以支持MapReduce和HDFS的独立发展。
(8)2006年11月,Google发表了Bigtable论文,这最终激发了HBase的创建。
(9)2007年,百度、中国移动开始使用使用Hadoop技术。
(9)2008年1月,Hadoop 成为了 Apache 顶级项目。之后 Hadoop 被成功的应用在了其他公司,其中包括 Last.fm、Facebook、《纽约时报》等。
(10)2008年6月,Hadoop的第一个SQL框架——Hive成为了Hadoop的子项目。
(11)2009 年3月,Cloudera推出世界上首个Hadoop发行版——CDH(Cloudera’s Distribution including Apache Hadoop)平台,完全由开放源码软件组成。
(12)2009年7月 ,MapReduce 和 Hadoop Distributed File System (HDFS) 成为Hadoop项目的独立子项目。
(13)2009年10月,首届Hadoop World大会在纽约召开。
(14)2011年1月,ZooKeeper 脱离Hadoop,成为Apache顶级项目。
(15)2011年7月,Yahoo!和硅谷风险投资公司 Benchmark Capital创建了Hortonworks 公司,旨在让Hadoop更加可靠,并让企业用户更容易安装、管理和使用Hadoop。
(16)2012年3月,企业必须的重要功能HDFS NameNode HA被加入Hadoop主版本。
(17)2012年8月,另外一个重要的企业适用功能YARN成为Hadoop子项目。
(18)2014年2月,Spark逐渐代替MapReduce成为Hadoop的缺省执行引擎,并成为Apache基金会顶级项目。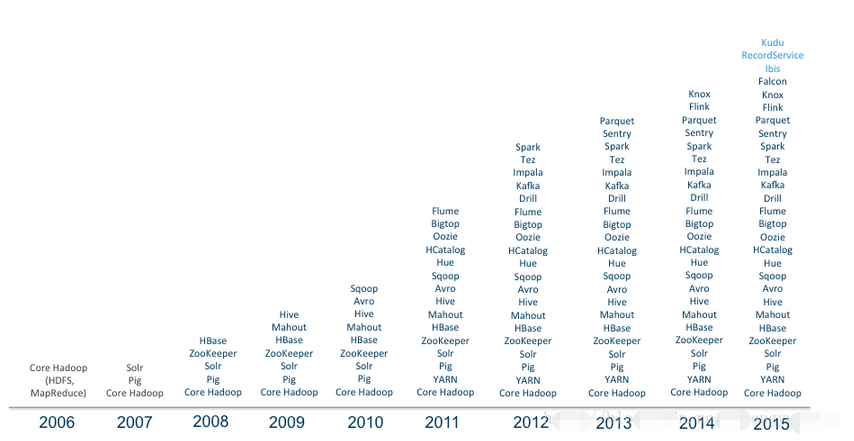
Hadoop 核心组件
Hadoop 包含以下模块:
Hadoop Common:常见实用工具,用来支持其他 Hadoop 模块。
Hadoop Distributed File System(HDFS):分布式文件系统,它提供对应用程序数据的高吞吐量访问。
Hadoop YARN:一个作业调度和集群资源管理框架。
Hadoop MapReduce:基于 YARN 的大型数据集的并行处理系统。
其他与 Apache Hadoop 的相关项目包括:
Ambari:一个基于Web 的工具,用于配置、管理和监控的 Apache Hadoop 集群,其中包括支持 Hadoop HDFS、Hadoop MapReduce、Hive、HCatalog、HBase、ZooKeeper、Oozie、Pig 和 Sqoop。Ambari 还提供了仪表盘查看集群的健康,如热图,并能够以用户友好的方式来查看的 MapReduce、Pig 和 Hive 应用,方便诊断其性能。
HBase:一个可扩展的分布式数据库,支持结构化数据的大表存储。
Hive:数据仓库基础设施,提供数据汇总以及特定的查询。
Mahout:一种可扩展的机器学习和数据挖掘库。
Pig:一个高层次的数据流并行计算语言和执行框架。
Spark:Hadoop 数据的快速和通用计算引擎。Spark 提供了简单和强大的编程模型用以支持广泛的应用,其中包括 ETL、机器学习、流处理和图形计算。
ZooKeeper:一个高性能的分布式应用程序协调服务。
Hadoop三大发行版
(1) Apache Hadoop
Apache Hadoop最原始版本,所有其他发行版均基于该发行版实现的。
官网地址http://hadoop.apache.org/,Logo如下
0.23.x :非稳定版
2.x :最新版是2.8.0,建议使用2.7.3稳定版。
3.0:已发行多个测试版,正式稳定版尚未发布
(2)CDH
CDH(Cloudera’s Distribution for Hadoop)是Cloudera 公司的的Hadoop 发行版。
官方是https://www.cloudera.com/,Logo如下。
包含CDH4 和CDH5 两个版本
CDH4 ;基于Apache Hadoop 0.23.0 版本开发
CDH5 :基于Apache Hadoop 2.2.0 版本开发
(3)HDP
HDP(The Hortonworks Data Platform)是Hortonworks 公司的发行版。
官网地址是https://hortonworks.com/,Logo如下。
(4) 发行版选择
- 作为学习,建议选择Apache Hadoop最新的稳定版;
- 作为工作(生产环境),建议选择CDH或HDP稳定版。
(5) 不同发行版兼容性
架构、部署和使用方法一致,不同之处仅在若干内部实现。