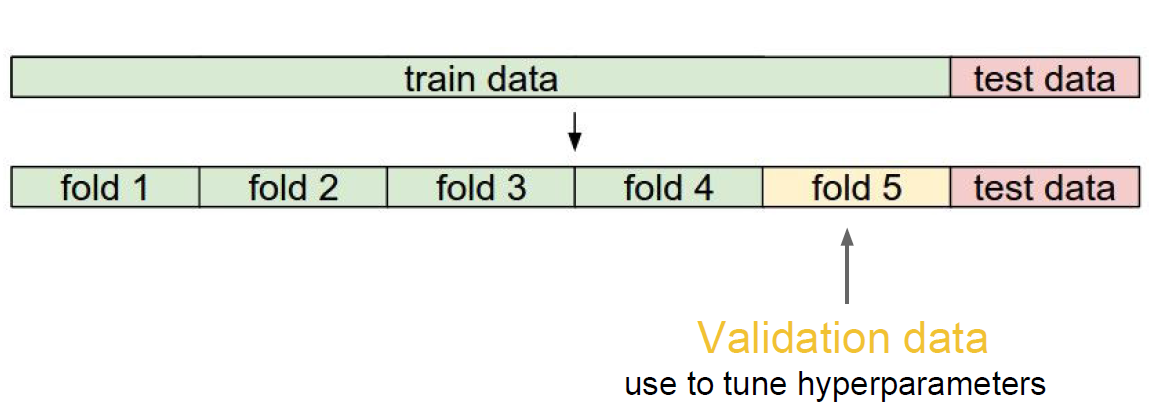
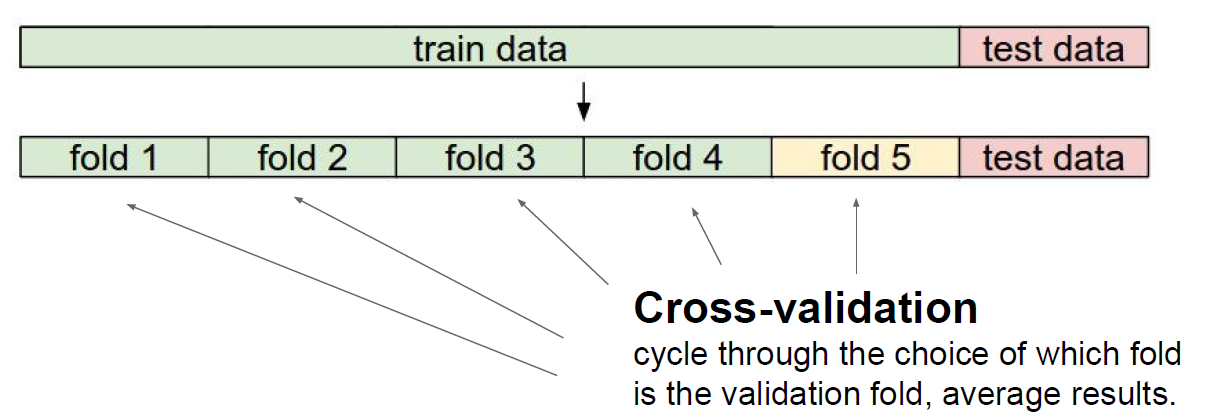
- 应当选择哪一种距离度量方式?KNN K值如何确定?也即如何确定超参。
- problem-dependent,具体问题具体分析;
- try what hyperparameters work best on test set.
- 并非是一个好主意,测试集(模型还未见过的数据)最好的用途在于作为模型泛化能力的评价,应当十分节俭地使用;
0. 数据集的切分
可采用如下方式对数据集进行切分:
1. NN ⇒ Classification
注意区分,NN(Nearest Neighbor)和 KNN,前一个是最近邻,后一个是前 K 近邻;
- train(X, y):无序训练,模型不需要参数
- predict(X):逐一计算和训练集 X 每一个元素距离的大小,
取最近的元素的 label,作为自己的 label
分类的速度随着训练集规模的变化:Linearly;对于现实应用而言,test 的时间性能更为看重。CNN 的一大好处就在于,
- expensive training
- cheap test evaluation