Viterbi Algorithm
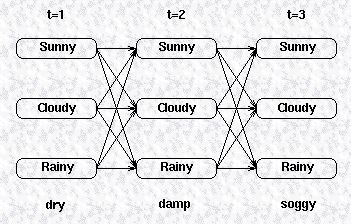
前面我们提到过,HMM的第二类问题是利用HMM模型和可观察序列寻找最有可能生成该观察序列的隐藏变量的序列。简单来说,第一类问题是通过模型计算生成观察序列的概率,而第二类问题通过观察序列计算最有可能生成该观察序列的的隐藏变量的序列。我们还是先来看如下一张图:

我们希望找到生成该观察序列的概率最高的一个隐藏变量的序列。换句话说,我们想要最大化如下的式子:
一种简单直观的方法是将所有可能的隐藏变量的序列全部列出,然后求出它们生成可观察序列的概率,然后挑出概率最大的一个隐藏变量序列,这种穷举法无疑是非常低效而且耗时的。与之前介绍的forward算法类似,我们可以借助状态转换矩阵以及confusion矩阵来减低运算的复杂度。
我们还是利用递归的方式去选择这样一条最优的隐藏变量序列,我们先定义一个局部概率
对于上图所示的各个路径,无论是到达中间时序的状态,还是到达最终时序的状态,都存在一条最优的路径,比如下图所示分别给出了到达最终时序的三个状态的路径,我们把这些路径称为局部最佳路径,每一个这样的局部最佳路径都有一个概率,称为局部概率,这个定义与forward算法里的局部概率不一样,这里的局部概率表示最佳路径的局部概率。
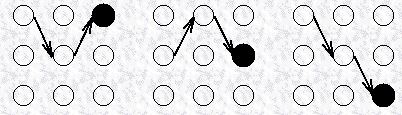
因此,
对应初始状态的局部概率,其定义和在forward算法中的一样,由初始概率和confusion矩阵决定,如下式所示:
我们接下来将要计算
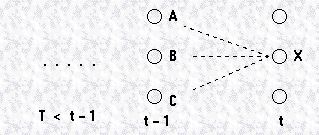
之前我们介绍过马尔科夫假设,即一个状态发生的概率只与之前的状态有关,而且对于一阶的马尔科夫过程,当前状态只和前一个状态有关,如果我们要计算状态A到状态X的概率,可以由下式表示:
因此,
上式右边的第一项是
现在我们已经知道如何求解到达隐藏变量中间状态和最终状态的局部概率
我们已经知道,为了计算时刻
注意到这个表达式和计算局部概率的表达式很像,唯一的区别在于这个表达式没有用到confusion矩阵,也就是没有隐藏变量与观察变量的转换概率。因为这里要找的是隐藏变量的前一个状态,所以与观察变量没有关系。通过这个表达式,我们可以确定到达当前状态
下面,我们对这个算法做一个总结,对于有
隐藏状态的初始局部概率,即
假设
我们可以知道在
所以,通过上式进行回溯,一旦回到初始时刻,那么序列
最后,我们做个小结,对于一个特定的HMM模型,Viterbi Algorithm用来寻找最有可能生成一组观察变量序列的隐藏变量序列,这个算法记录了每一个隐藏状态的局部概率
Forward-backward algorithm
前面我们介绍了两类问题,并且介绍了相应的两种算法。第一类问题是用来评估模型的,我们介绍了forward算法;第二类问题是寻找最佳的隐藏变量序列的,我们利用的
是Viterbi算法,这两类问题都要用到已知的模型,转换矩阵,confusion矩阵,观察变量的序列等等。而第三类问题比前两类要复杂地多,它们没有现成的模型,我们需要
估计一个可行的模型,这属于学习问题,这类问题要用Forward-backward算法来解决,这个算法要比前面介绍的两种算法更加复杂,这里就不再详细介绍了。有兴趣的可以
参考下面的文献:
L R Rabiner and B H Juang, `An introduction to HMMs’, IEEE ASSP Magazine, 3, 4-16.
参考来源:
http://www.comp.leeds.ac.uk/roger/HiddenMarkovModels/html_dev/main.html