CUDA是一个基于NVIDIA GPU的并行计算平台和编程模型,通过调用CUDA提供的API,可以开发高性能的并行程序。CUDA安装好之后,会自动配置好VS编译环境,按照UCDA模板新建一个工程“Hello CUDA”:
建好之后,发现该工程下已经存在一个项目 kernel.cu。这个是CUDA编程的入门示例,实现的功能是两个整型数组相加,代码如下:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size);
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
int main()
{
const int arraySize = 5;
const int a[arraySize] = { 1, 2, 3, 4, 5 };
const int b[arraySize] = { 10, 20, 30, 40, 50 };
int c[arraySize] = { 0 };
// Add vectors in parallel.
cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addWithCuda failed!");
return 1;
}
printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}
",
c[0], c[1], c[2], c[3], c[4]);
// cudaDeviceReset must be called before exiting in order for profiling and
// tracing tools such as Nsight and Visual Profiler to show complete traces.
cudaStatus = cudaDeviceReset();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
return 0;
}
// Helper function for using CUDA to add vectors in parallel.
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size)
{
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
cudaError_t cudaStatus;
// Choose which GPU to run on, change this on a multi-GPU system.
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}
// Allocate GPU buffers for three vectors (two input, one output) .
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
// Copy input vectors from host memory to GPU buffers.
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
// Launch a kernel on the GPU with one thread for each element.
addKernel << <1, size >> > (dev_c, dev_a, dev_b);
// Check for any errors launching the kernel
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addKernel launch failed: %s
", cudaGetErrorString(cudaStatus));
goto Error;
}
// cudaDeviceSynchronize waits for the kernel to finish, and returns
// any errors encountered during the launch.
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!
", cudaStatus);
goto Error;
}
// Copy output vector from GPU buffer to host memory.
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
return cudaStatus;
}
程序首先定义了一个函数addWithCuda,它是调用GPU运算的入口函数,返回类型是cudaError_t。
cudaError_t是一个枚举类型,可以作为几乎所有CUDA函数的返回类型,用来检测函数执行期间发生的不同类型的错误,一共有80多个错误类型,可以在driver_types.h头文件中查看每一个整型对应的错误类型,如果返回0,代表执行成功。
第二个函数addKernel在最前有一个修饰符“__global__”,这个修饰符告诉编译器,被修饰的函数应该编译为在GPU而不是在CPU上运行,所以这个函数将被交给编译设备代码的编译器——NVCC编译器来处理,其他普通的函数或语句将交给主机编译器处理。
这里“设备”的概念可以理解为GPU和其显存组成的运算单元,“主机”可以理解为CPU和系统内存组成的运算单元。在GPU上执行的函数称为核函数。
addKernel函数定义:
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}这个核函数里有一个陌生的threadIdx.x,表示的是thread在x方向上的索引号,理解这个之前得先了解一下GPU线程的层次结构:
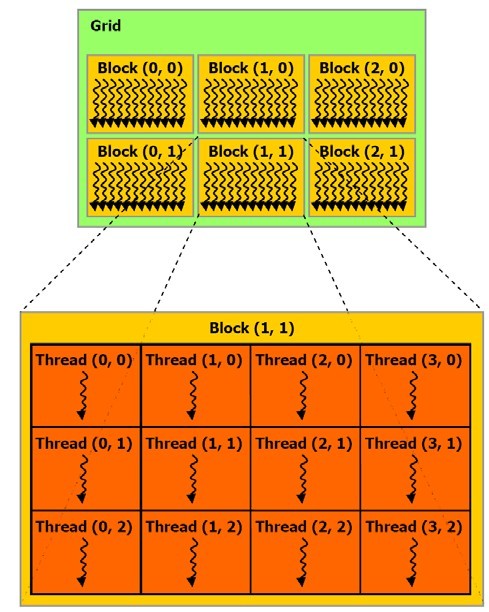
CUDA中的线程(thread)是设备中并行运算结构中的最小单位,类似于主机中的线程的概念,thread可以以一维、二维、三维的形式组织在一起,threadIdx.x表示的是thread在x方向的索引号,还可能存在thread在y和z方向的索引号threadIdx.y和threadIdx.z。
一维、二维或三维的thread组成一个线程块(Block),一维、二维或三维的线程块(Block)组合成一个线程块网格(Grid),线程块网格(Grid)可以是一维或二维的。通过网格块(Grid)->线程块(Block)->线程(thread)的 顺序可以定位到每一个并且唯一的线程。
回到程序中的addKernel函数上来,这个函数会被GPU上的多个线程同时执行一次,线程间彼此没有通信,相互独立。到底会有多少个线程来分别执行核函数,是在“<<<>>>”符号里定义的。“<<<>>>”表示运行时配置符号,在本程序中的定义是<<<1,size>>>,表示分配了一个线程块(Block),每个线程块有分配了size个线程,“<<<>>>”中的 参数并不是传递给设备代码的参数,而是定义主机代码运行时如何启动设备代码。以上定义的这些线程都是一个维度上的,可以通过thredaIdx.x来获取执行当前计算任务的线程的ID号。
cudaSetDevice函数用来设置要在哪个GPU上执行,如果只有一个GPU,设置为cudaSetDevice(0);
cudaMalloc函数用来为参与运算的数据分配显存空间,函数原型:cudaError_t cudaMalloc(void **p, size_t s);
cudaMemcpy函数用于主机内存和设备显存以及主机与主机之间,设备与设备之间相互拷贝数据,函数原型:
cudaError_t CUDARTAPI cudaMemcpy(void *dst, const void *src, size_t count, enum cudaMemcpyKind kind);
第一个参数dst是目标数据地址,第二个参数src是源数据地址,第三个参数count是数据大小,第四个参数kind定义数据拷贝的类型,有如下几类枚举类型:
/**
* CUDA memory copy types
*/
enum __device_builtin__ cudaMemcpyKind
{
cudaMemcpyHostToHost = 0, /**< Host -> Host */
cudaMemcpyHostToDevice = 1, /**< Host -> Device */
cudaMemcpyDeviceToHost = 2, /**< Device -> Host */
cudaMemcpyDeviceToDevice = 3, /**< Device -> Device */
cudaMemcpyDefault = 4 /**< Direction of the transfer is inferred from the pointer values. Requires unified virtual addressing */
};接下来在调用核函数时候添加了运行时配置符号“<<<>>>”,定义线程块和线程的数量,如<<<1,5>>>表示定义了一个线程块,每个线程块包含了5个线程。
cudaGetLastError函数用于返回最新的一个运行时调用错误,对于任何CUDA错误,都可以通过函数cudaGetErrorString函数来获取错误的详细信息。
cudaDeviceSynchronize函数提供了一个阻塞,用于等待所有的线程都执行完各自的计算任务,然后继续往下执行。
cudaFree函数用于释放申请的显存空间。
cudaDeviceReset函数用于释放所有申请的显存空间和重置设备状态;
第一个CUDA程序kernel.cu涉及的内容主要就是这些。CUDA的使用步骤如下:
- 主机代码执行
- 传输数据给GPU
- 确定Grid、Block大小
- 调用内核函数,GPU多线程运行程序
- 传输运算结果给CPU
- 继续主机代码执行
期间涉及到在设备上的一些显存空间申请、销毁等操作,从内存到显存上数据的相互拷贝是一个比较耗时的过程,应该尽量减少这种操作。