一、subprocess模块
os.system 输出命令结果到屏幕,返回命令执行状态
使用方式为:
res=os.system('dir')
结果显示为:
驱动器 C 中的卷是 WINDOWS
卷的序列号是 CC81-05A6
C:Userszhao 的目录
2017/07/12 00:04 <DIR> .
2017/07/12 00:04 <DIR> ..
2017/05/15 01:33 <DIR> .android
2016/12/23 00:17 <DIR> .idlerc
2017/03/11 13:39 <DIR> .oracle_jre_usage
2017/04/08 20:04 352 .packettracer
2017/02/13 22:01 <DIR> .PyCharm50
2017/07/12 00:32 <DIR> .THypervBox
2017/06/23 05:57 <DIR> .VirtualBox
3 个文件 352 字节
9 个目录 50,369,916,928 可用字节
再次打印res:
print(res)
结果为:
0
即发现,os.system()只及时执行,而不会将结果存储下来。
如果既想要输出命令的结果,又想要输出命令的执行状态
1、可以使用popen
import os res=os.popen("dir").read() print(res)
2、可以使用subprocess
先介绍下run命令:
run命令: shell=True 在subprocess.run()中使用,其意思为无需python进行代码解释。其使用的 主体结构为 : subprocess.run(“需要执行的命令 ”,shell=True)。若使用了shell=true,则需要执行的命令处:可以直接使用 df -h。不使用的话则需将命令拆开,设置
为“df","-h".若存在管道符,则其输入格式直接使用“df -h | grep ***”,即为将所有参数合为一。
例如:
import subprocess subprocess.run("dir",shell=True)
此命令仅支持直接输出命令结果
call命令:
subprocess.call() 返回执行命令的状态 状态为0或者非0.类似os.system()
subprocess.check_call()命令执行正常则返回结果,如果不正常则直接报错,即运行出现错误。
举例如:
import subprocess res=subprocess.call("dir",shell=True) print(res)
最终若执行成功,res==0 执行不成功 res==1且报错
check_call()
import subprocess res=subprocess.check_call("dirsfsf",shell=True) print(res)
运行即会报错

getstatusoutput():
subprocess.getstatusoutput() 执行命令,并返回执行是否成功和执行结果。
res=subprocess.getstatusoutput("ipconfig")
print(res[0]) [0]为执行是否成功,0为成功,1为失败。
print(res[1]) [1]为执行命令的结果。即在系统中输入ipconfig后出现的输出。
import subprocess res=subprocess.getstatusoutput("ipconfig") print(res[0]) print(res[1])
结果为

Popen()
如果想要将结果存储下来,那么需要这样使用:
res=subprocess.Popen("ipconfig",shell=True,stdout=subprocess.PIPE) print(res.stdout.read())
stdout 为标准输出
此种输出有三类:
stdout 为标准输出 stdint 为标准输入 stderr为标准错误。
若执行的命令执行时间过长,则结果需要等待执行完成。
比如此类代码,执行需要时间,那么我们可以添加res.wait()#等到结果,然后返回。
res=subprocess.Popen("sleep 10;echo 'hello'",shell=True,stdout=subprocess.PIPE,stderr=subproess.PIPE) res.poll() print(res.poll()) #返回None则为还未出结果,返回0则表示结果已经出来了。
res.wait()#等到结果,然后返回。
terminate()杀死任务进程,使用方式如下:res.terminate()
subprocess.Popen()可调用的参数:
args:shell命令,可以是字符串或者序列类型
bufsize:指定缓冲。
stdin,stdout,stderr。
close_sfs 在Windows平台系,如果close_fds被设置为True,则新创建的子进程将不会继承父进程的输入、输出、错误管道。所以不能将close_sfs设置为True同时重定向子进程的标准输入、输出、与错误。
cwd:用于设置子进程的当前目录。
env:用于指定子进程的环境变量。如果env=None,子进程的环境变量将从父进程继承。
universal_newlines:不同系统的换行符不同, 为True则同意使用
startupinfo与createionflags只在windows下有效。将被传递给底层的CreateProcess()函数,用于设置子进程的一些属性,如:主窗口的外观,进程的优先级等等
二、面向对象
OOP Object Oriented programing 面向对象编程
是利用“类”和“对象”来创建各种模型来实现对真是世界的描述。
之前定义的函数主要涉及的是功能的实现。即将一个能够完成某一动作的代码封存到一块,谁用谁来取即可。而类则仅仅是提供了同一类事物中,某一方面存在统一特性的一个模板。若需要对其使用,则要进行一个实例化操作,之后才可以执行该类事物拥有的相关功能。
举一个例子:
我们拿开车这个技能来做一个说明。在没接触面向对象之前,我们会将开车这项技能写成一个函数,然后让会开车的人调用此功能,不会开车的人就不调用此功能。或者是进行一个判断,输出对应的开车技能。类似如下方式:
# -*- coding:utf-8 -*- def driver(name,age,gender,skill): if skill=="会": if int(age)>=35: msg="%s,性别%s,今年%s岁,开车稳。"%(name,gender,age) else: msg="%s,性别%s,今年%s岁,开车毛躁。"%(name,gender,age) elif skill=="不会": msg="%s,性别%s,今年%s岁,不会开车。"%(name,gender,age) return msg zhangsan=driver("zhangsan",35,"male","不会") print(zhangsan)
通过函数,我们判断出了这个人到底会不会开车,有没有这项技能,算是完成了任务。但是现在突然又来了一个需求,要判断这个人会不会游泳。这跟刚刚的需求完全不搭边。那我们也可以再写一个函数完成这个工作:
# -*- coding:utf-8 -*- def driver(name,age,gender,skill_drive): if skill_drive=="会": if int(age)>=35: msg="%s,性别%s,今年%s岁,开车稳。"%(name,gender,age) else: msg="%s,性别%s,今年%s岁,开车毛躁。"%(name,gender,age) elif skill_drive=="不会": msg="%s,性别%s,今年%s岁,不会开车。"%(name,gender,age) return msg def swimming(name,age,gender,skill_swim): if skill_swim=="会": msg="%s,性别%s,今年%s岁,游泳很6。"%(name,gender,age) elif skill_swim=="不会": msg="%s,性别%s,今年%s岁,不知道啥是游泳。"%(name,gender,age) return msg zhangsan=driver("zhangsan",35,"male","不会") zhangsan2=swimming("zhangsan",35,"male","不会") print(zhangsan) print(zhangsan2)
而从面向对象的角度来看,我们当前涉及到的对象皆为人,并且我们只涉及到了人的技能方面,那么就从我们的应用出发,只做技能信息。从而在面向对象的角度上分析可得:
1、基类是人,都会有姓名、年龄、性别等属性
2、有人存在开车这项技能,可以通过驾驶车辆到达自己的目的地。
3、有人不会开车,只能通过腿着到达自己的目的地。
顺着这样的情况思考下来,基本上就体现了面向对象的思考方式。
而体现到代码上,则是如下方式:
# -*- coding:utf-8 -*- class Person(): def __init__(self,name,age,gender): self.NAME=name self.AGE=age self.GENDER=gender class Skill(Person): def __init__(self,name,age,gender,skill_driver,skill_swimming): Person.__init__(self,name,age,gender) self.drivers=skill_driver self.swim=skill_swimming def driver(self): if self.drivers=="会": if int(self.AGE)>=35: msg="%s,性别%s,今年%s岁,开车稳。"%(self.NAME,self.GENDER,self.AGE) else: msg="%s,性别%s,今年%s岁,开车毛躁。"%(self.NAME,self.GENDER,self.AGE) elif self.drivers=="不会": msg="%s,性别%s,今年%s岁,不会开车。"%(self.NAME,self.GENDER,self.AGE) return msg def swimming(self): if self.swim=="会": msg="%s,性别%s,今年%s岁,游泳很6。"%(self.NAME,self.GENDER,self.AGE) elif self.swim=="不会": msg="%s,性别%s,今年%s岁,不知道啥是游泳。"%(self.NAME,self.GENDER,self.AGE) return msg zhangsan=Skill("zhangsan",30,"male","会","会") print(zhangsan.driver()) print(zhangsan.swimming())
以上是在思路上介绍的面向对象,下面是在语法上介绍下代码结构:
class为创建类的关键词,表示创建的此项内容为类
def __init__(self,name,age,gender)构造函数,或者叫构造方法。代表的是传入的参数,而self可以理解为是类中连通内部各函数,方便调用传入参数的某项功能。self默认自动填写,而self.NAME=name则是将传入的name赋值给了self.NAME,保证了在类内部的通行。
而self._name则代表了私有属性,表示外部无法访问到此属性。
def driver()就是正常的函数了,此函数只会在最终调用时,与原来的函数有些区别,其调用的方式需要先加上类名。类中再次设置函数是为了区分各项功能,同时也做到了实例化以后所有功能不自动运行。
部分私有属性外部想要访问,但是不允许改动的情况下,可以定义一个方法,仅返回私有属性,不做其他操作。如:
def get_NAME(self):#对外提供只读访问接口。 return self._Name
若需强制访问私有属性,则可进行如下操作:实例化对象._所在类名+私有属性 如 a.Person__talk __talk为私有属性
在类中直接定义的属性即为公有属性。
如:
class Person: gender="Male" def __init__(self,name,age): self.NAME=name self.age=AGE
其中,gender即为公有属性。
若调用Person更改gender,则全局都会改变,若调用某一实例化对象更改gender,则只会更改这一实例化对象的gender。
如 Person.gender=“Female"会更改全局
而 a= Person() a.gender="Female" 则改了自身的属性。
对于类中的函数,也是类似构造函数一样,若需要更改单独实例的类内函数,需要单独进行重写,调用的时候调用单独重写的函数才可以。
析构方法:只要引用被清空的时候,就会执行。
析构函数的形式:
def __del__(self):
pass
应用场景,客户端与服务端正在正常连接,目前服务端要例行维护,需要停止,但此时客户端仍旧正常连接着,为了在服务端停止以后不出现异常,可以在服务端的析构函数中写入关闭所有客户端连接。做一些程序的收尾工作。
继承
子类继承父类的构造函数,同时若需要,也可以先继承,再重构。
类名开头大写,函数不需要开头大写。
如何打印实例中所有的数值:
1、首先,可以直接在子类中写一个打印。
2、可以直接在父类中使用self.__dict__来进行循环取值。
多态:
多态是允许将子类类型的指针赋值给父类类型的指针
如以下形式:
class Person(): def __init__(self,name,age,gender): self.name=name self.age=age self.gender=gender def talk(self): print("%s is talking"%self.name) class Child(Person): def __init__(self,name,age,gender): super(Child, self).__init__(name,age,gender) def talk(self): print("%s is child"%self.name) class Adult(Person): def __init__(self,name,age,gender): super(Adult, self).__init__(name,age,gender) def talk(self): print("%s is adult"%self.name)
#此处定义的函数,是独立于类之外的,即为了实现多态,重新定义了一个新的类,让其能够满足一个接口,多种形态。
def talk(obj): obj.talk()
d=Child("liu",10,"male")
e=Adult("lu",26,"male")
静态方法
在方法前面直接冠 @staticmethod
这样写完以后,方法实际上跟类没什么关系了。相当于跟类的关系截断了。
只是名义上归类管理,实际上在静态方法里访问不了类或实例中的任何属性。
类方法:
只能访问类变量,不能访问实例变量
class Person(): name="li" def __init__(self,name,age,gender): self.name=name self.age=age self.gender=gender #若在前加@classmethod,则只能使用全局下的name,而不能使用构造函数中的self.name @classmethod def talk(self): print("%s is talking"%self.name)
d=Person("liu",25,"male")
d.talk()
#此为最终结果
res:
li is talking
若将代码talk部分改为: @classmethod def talk(self): print("%s is talking"%self.age) 则代码就会出现问题,提示找不到age属性
属性方法:把一个方法变为静态属性,形式为@property.
class Person(): name="li" def __init__(self,name,age,gender): self.name=name self.age=age self.gender=gender @property def talk(self): print("%s is talking"%self.name)
#加上@property之后,改方法就变成了一个静态属性,不是一个方法了,而在调用的时候,就不需要再加括号了。 直接如下调用即可:
d= Person("liu",26,"male")
d.talk
属性方法如果需要传入值,则需要用到.setter装饰器再装饰一下。如:
def __init__(self,name,age,gender): self.name=name self.age=age self.gender=gender @property def talk(self): print("talking") @talk.setter def talk(self,owner): print("%s is talking"%owner) d=Person("liu",26,"male") d.talk="liu"
结果为 : liu is talking
类的特殊成员方法:
__doc__
打印这个类的描述信息
class Person(): __doc__ = "这个类是用来定义基类:人 的" def __init__(self,name,age): self.name=name self.age=age def talking(self): print("% is talking"%self.name) a=Person("liu",25) print(a.__doc__)
res:
直接输出: 这个类是用来定义基类:人 的
__moudile__ 和__class__
__moudle__ 表示当前操作的对象在哪个模块中
__class__ 表示当前操作的对象的类是什么
__init__构造方法
__del__析构方法,当对象在内存中被释放时,自动触发执行。
__call__ 对象后面加括号,触发执行
举例如下:
class Person(): def __init__(self,name,age,gender): self.name=name self.age=age self.gender=gender def talk(self): print("%s is talking"%self.name) def __call__(self, *args, **kwargs): print("this is %s call"%self.name) d=Person("liu",26,"male") d() 结果为
this is liu call
__dict__查看类或者对象中所有的成员
class Person(): def __init__(self,name,age,gender): self.name=name self.age=age self.gender=gender def talk(self): print("talking") d=Person("liu",26,"male") print(d.__dict__) print(Person.__dict__)
类.__dict__ 打印类里的所有属性,不包括实例属性
实例.__dict__打印所有实例属性,不包括类里的属性
__str__如果一个类中定义了__str__方法,那么在打印对象时,默认输出该方法的返回值。 举例如下 class Person(): def __init__(self,name,age,gender): self.name=name self.age=age self.gender=gender def talk(self): print("talking") def __str__(self): print("此为str方法") return “No” d=Person("liu",26,"male") print(d) 结果为
此为str方法
No
PS.经过测试发现 __str__若返回的不是string,则会报错,直接提示:TypeError: __str__ returned non-string ,因此设置时需要注意。
__getitem__、__setitem__、__delitem__
用于索引操作,如字典。以上分别表示获取、设置、删除数据
首先是getitem
class Person(): def __init__(self,name,age,gender): self.name=name self.age=age self.gender=gender def talk(self): print("talking") def __getitem__(self, item): print("此为getitem") if item=="key": return 3 elif item=="key2": return 6 elif item=="key3": return 9 else: return 12 d=Person("liu",26,"male") res=d.__getitem__("key") print(res) 结果为
此为getitem
3
可更改res=d.__getitem__("key")来查看其它的值
然后是setitem class Person(): def __init__(self,name,age,gender): self.name=name self.age=age self.gender=gender def talk(self): print("talking") def __setitem__(self, key, value): print("此为setitem") if key=="name": self.name=value elif key=="age": self.age=value elif key=="gender": self.gender=value d=Person("liu",26,"male") print(d.name) d["name"]="zhao" print(d.name)
结果为:
liu
此为setitem
zhao
最后是delitem: class Person(): def __init__(self,name,age,gender): self.name=name self.age=age self.gender=gender def talk(self): print("talking") def __delitem__(self): print("此为del") del self.name d=Person("liu",26,"male") print(d.name) del d.name print(d.name) 将名称删除以后再次打印,结果即为以下内容:
liu
直接报错
若对最终打印结果进行异常处理,将代码改为: try: print(d.name) except AttributeError: print("属性已被删除") 则结果会变为:
liu
属性已被删除
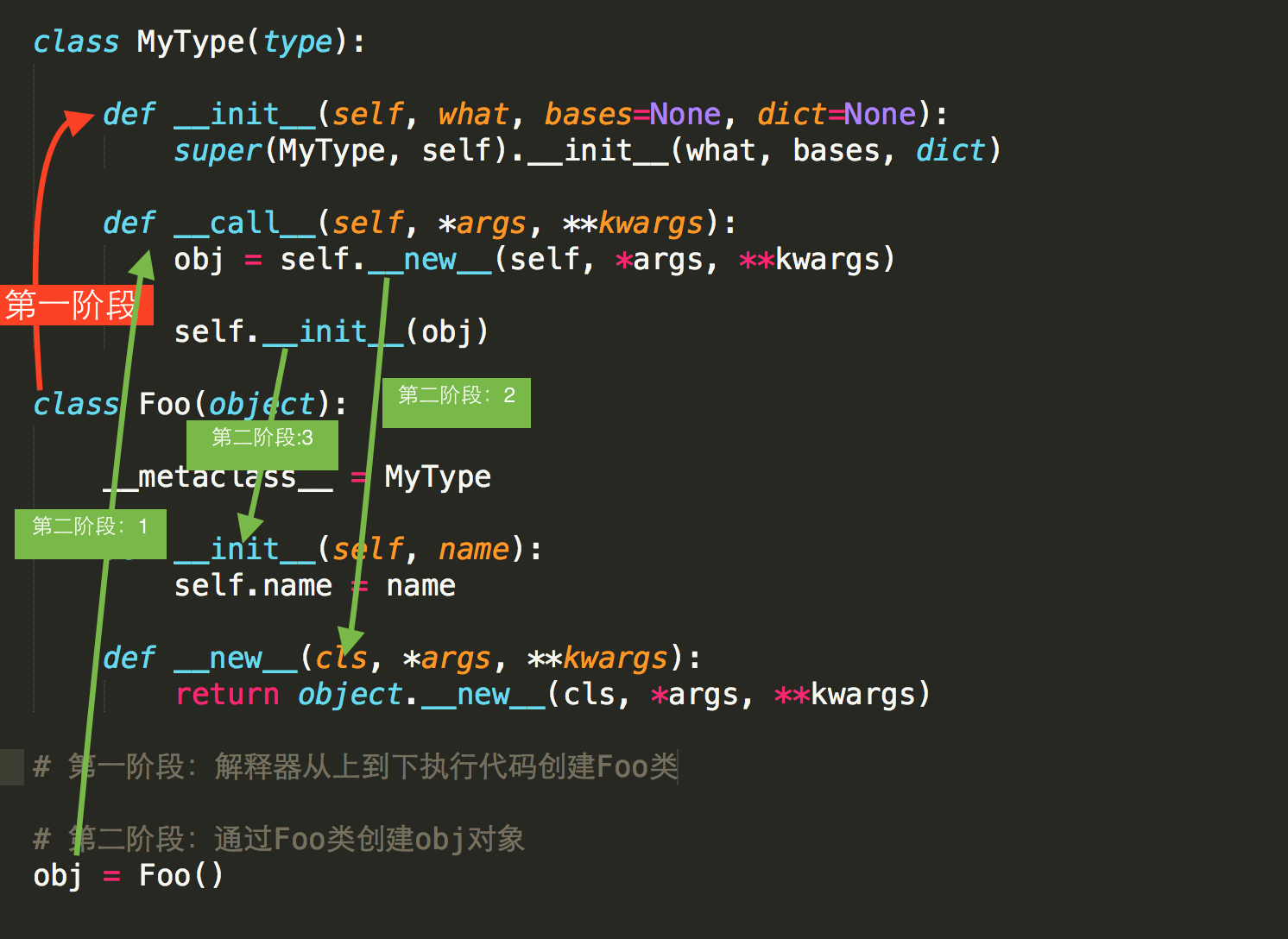
__new__ __metaclass__
class Person(): def __init__(self,name,age,gender): self.name=name self.age=age self.gender=gender def talk(self): print("talking") d=Person("liu",26,"male") print(type(d)) print(type(Person))
在以上函数中,d通过Person成为实例化对象,在此,d跟Person其实都是一个实例。
通过打印d 和Person的类型来看,二者都是通过类来创建的。
Person即为通过type的构造方法创建的。
从以上可知,类也可使用如下方式进行创建:
def __init__(self,name,age,gender): self.name=name self.age=age self.gender=gender def talk(self): print(" %s is talking"%self.name) def eat(self): print("%s is eat, he/she is %s"%(self.name,self.age)) Person=type("Person",(object,),{"talk":talk,"__init__":__init__}) d=Person("liu",25,"male") d.talk()
所有函数在Person=type()之前都没有关联,但是在type之后就被关联到了一块
最终结果为:
liu is talking
而类默认是type类实例化产生的,type类中如何实现创建类,类又是如何创建对象的呢?
此处借助alex的解释来补充此部分:
答:类中有一个属性 __metaclass__,其用来表示该类由 谁 来实例化创建,所以,我们可以为 __metaclass__ 设置一个type类的派生类,从而查看 类 创建的过程。
类的生成 调用 顺序依次是 __new__ --> __init__ --> __call__
metaclass 详解文章:http://stackoverflow.com/questions/100003/what-is-a-metaclass-in-python 得票最高那个答案写的非常好
三 面向对象进阶
1、应用场景
什么时候适用面向对象?
1、如果多个函数须传入多个共同的参数时
2、根据一个模板创建某些东西
3、传入值相同,需多次传入的情况时
2、经典类和新式类
1、两者写法不同
经典类的写法是
class A: pass
新式类的写法是
class A(object): pass
2、继承关系不同
新式类采用的是广度优先搜索,经典类采用的是深度优先搜索。
python2.X中,默认采用的是经典类,只有显式继承了object的才是新式类
python3.X中,默认采用的都是新式类,不必显式的继承object
3、继承传参不同
新式类继承时传参可以使用super关键字
# -*- coding:utf-8 -*- class Person(): def __init__(self,name,age,gender): self.name=name self.age=age self.gender=gender def jieshao(self): print("I am %s"%self.name) class DaPerson(Person): def __init__(self,name,age,gender): # super(DaPerson, self).__init__(name,age,gender) 新式类的写法 # Person.__init__(self,name,age,gender) 经典类的写法,只是在此出现不一样 def jieshao(self): print("I am DaPerson,name is %s"%self.name) zhangsan=DaPerson("zhangsan",22,"male") zhangsan.jieshao()
3、self就是调用当前方法的对象。
创建的对象内部存在类对象指针。指向类内部的方法,在执行类内部方法时,也会把自己传入到类中。
全局的属性称为静态字段
每个对象都存在一个公共的值的情况下,就可以将此值设置为静态字段。
而类对应生成的对象中,存在字段主要是普通字段或者说是普通属性,共有字段或者说是共有属性是存放在类自身里面的
方法: 普通方法(保存在类中,调用者对象,至少有一个self参数)
静态方法: (可以有任意个参数,但python不会强制赋值self)
class F1:
@staticmethod
def a1():
print('alex')
调用静态方法可以直接调用: F1.a1()
后续socket与下章笔记一块整理。