Unified Parallel C - 统一并行C语言。用于并行计算和编程,是C语言的一个扩充版本。
转载任何内容都请注明出处。若用于任何教育或商业目的请先联系作者,谢谢。
3.1 UPC指针
和C差不多,但根据UPC公有变量和私有变量的不同,两两组合有4种指针
1 int *p1; // private to private 2 shared int *p2; // private to shared 3 int *shared p3; // shared to private 4 shared int *shared p4; // shared to shared
P3是公有指针,指向私有变量。不是非法,但应该避免,因为这与UPC的分布式共享内存模型的设计初衷(公有空间对所有线程可见,私有数据仅对相关联的线程可见)相违背。

3.2 指针的算术
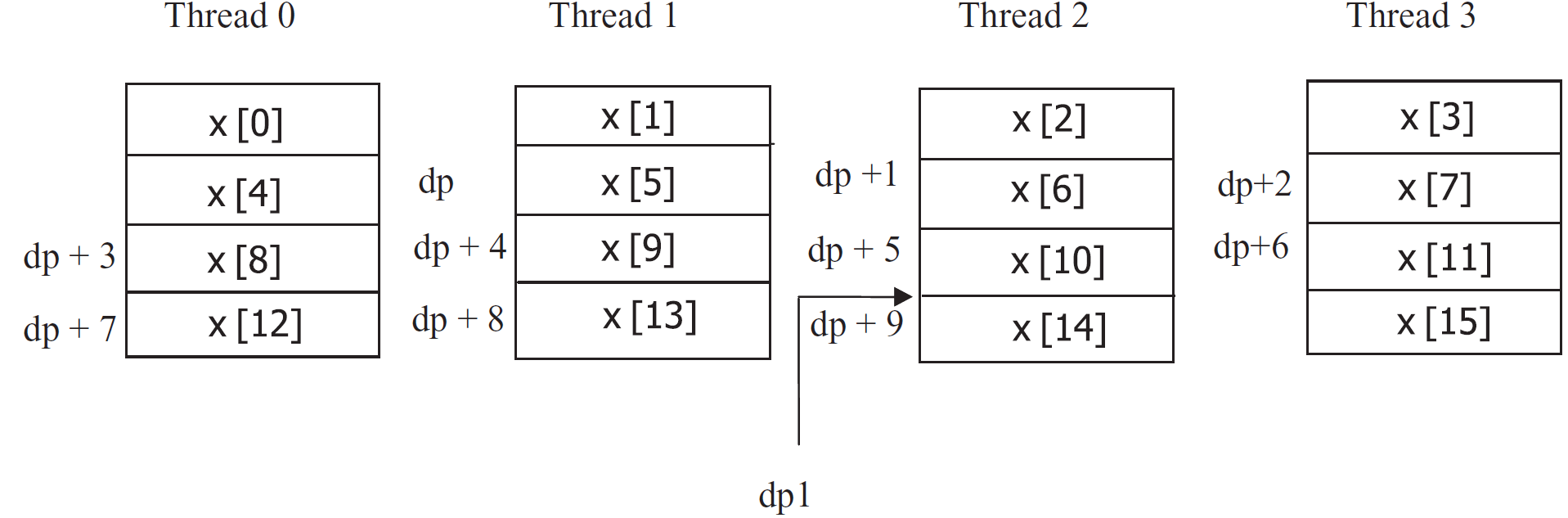
1 #define N 16 2 shared int x [N]; 3 shared int *dp, *dp1; 4 dp = &x [5]; 5 dp1 = dp + 9;
1 #define N 16 2 shared int x [N]; 3 shared int *shared dp; 4 shared int *dp1; 5 dp = & x [5]; 6 dp1 = x+MYTHREAD;
dp只有一个实例,指向x[5]。dp1的偏移量是线程id,正好是每个线程的首个被分配到的元素
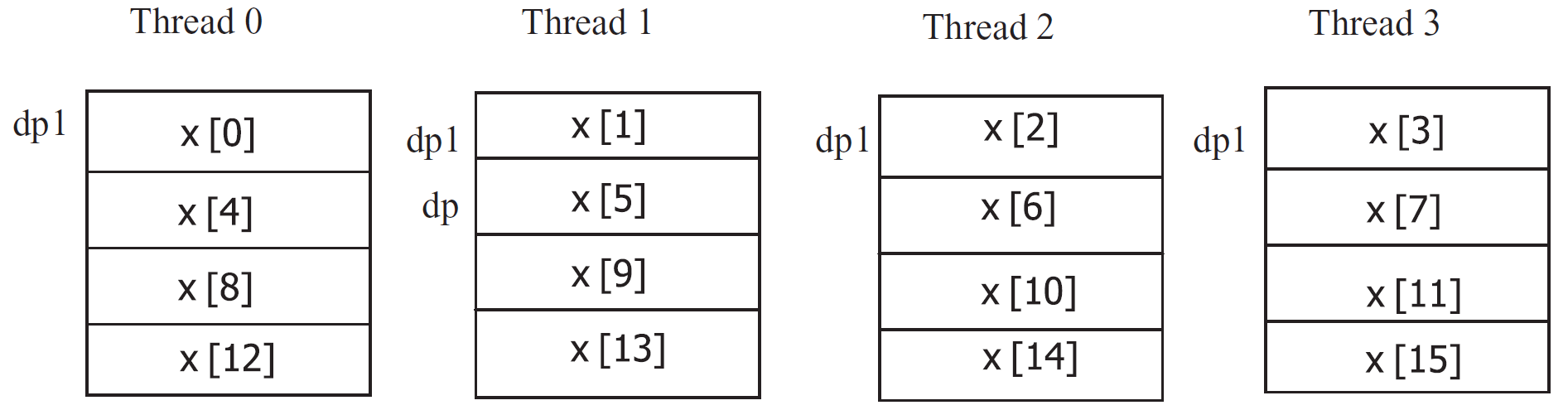
若将最后一行改成:
dp1 = &x [MYTHREAD];
则dp1指向每个线程的首个数组元素的地址
为追踪共享数据,UPC的公有指针(即指向一个公有对象的指针)包含三个域:thread, phase, virtual address

thread域指出所指向数据相关联的线程;block address 指出块地址(block address);phase指出这个块内的数据项的所在位置。
通过给出一个有相同分块信息(blocking factor)的指针,可用于遍历分块数组(blocked array),看下面
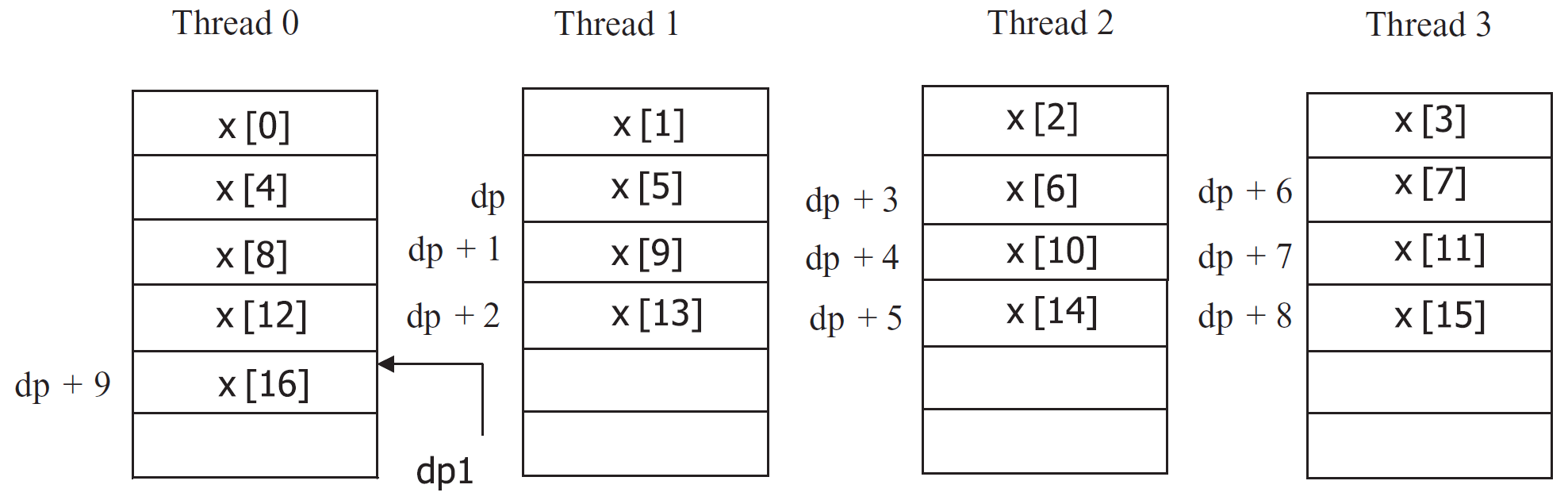
1 #define N 16 2 shared [3] int x[N], *dp, *dp1; 3 shared int *dp2; 4 ... 5 dp = &x [5]; 6 dp1 = dp + 9; 7 dp2 = dp + 3;
若4线程,数据布局为

其他都好理解,为什么dp2指向x[12]呢?因为dp和dp1声明时提供了分块信息,他们把共享空间看作3个以所指向类型的数据为一块而构成的许多数据块。而dp2仍是默认方式,他不知道数据是有三个元素的一块,因此每次增加他都移向下一个线程的一个新元素。而dp1可以用于访问分块数组中的每个元素。
3.3 指针类型转换
shared->private 线程信息丢失;private->shared 出错;private->自己本地的共享数据,这是可以的,比如
shared int x [THREADS]; int *p; p = (int *) &x [MYTHREAD]; /* p points to x [MYTHREAD] */
再看一个例子
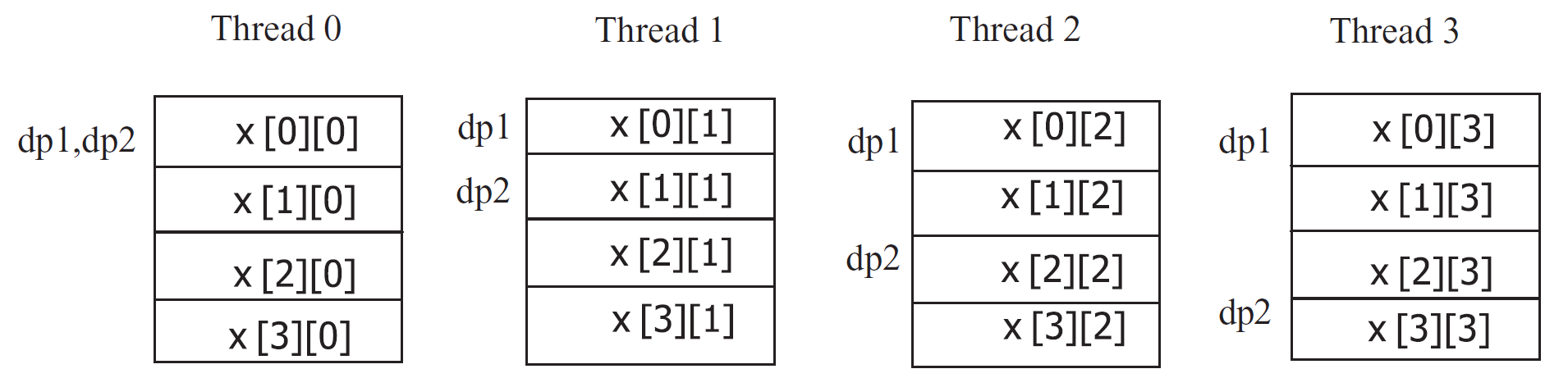
1 #define N 4 2 shared int x[N][N]; 3 shared int *dp1; 4 int *dp2; 5 dp1 = x+MYTHREAD; 6 dp2 = (int *)dp1+MYTHREAD;
分析:x是以轮转法分配的共享数组,元素为存放在公有空间的整型;dp1指向每个线程的第一个数组元素;dp2相对于dp1的偏移量等于本线程id。
如图:
看一个较难的例子
shared int x [N]; shared [3] int *dp=&x[5], *dp1; dp1 = dp + 9;
数据分布竟然是···
和之前某个例子的区别在于,这里的数组并没有按块划分,但指针却有分块信息。因此从dp指向的那个元素开始,三个三个为一块。
3.4指针信息与相关函数
size_t upc_threadof (shared void *ptr);
参数:ptr是一个私有指针,指向任意共享类型的对象
返回值:与ptr所指向的公有对象相关联的线程的id
size_t upc_phaseof (shared void *ptr);
返回值:phase
size_t upc_addrfieldof (shared void *ptr);
返回值:ptr所指向的公有对象的本地地址(返回值依赖于函数实现)
举个例子,以下程序使用thread 0打印指针的三个域,其中地址域以10进制显示,线程数和phase域以2进制显示
1 //PrintPointerElements 2 #include <stdio.h> 3 #include <upc.h> 4 #include <upc_relaxed.h> 5 #define BLOCKING_FACTOR 3 6 #define SIZE BLOCKING_FACTOR*THREADS 7 shared [BLOCKING_FACTOR] int buffer [SIZE]; 8 int main(void) 9 { 10 int i; 11 shared [BLOCKING_FACTOR] int *buffer_ptr; 12 if(MYTHREAD == 0) 13 { 14 buffer_ptr = buffer + 5; 15 for(i=0; i<SIZE; i++, buffer_ptr++) 16 { 17 printf("&buffer [%d]: ", i); 18 printf("THREAD: %02d ", 19 upc_threadof(buffer_ptr)); 20 printf("ADDRESS: %010Xh ", 21 upc_addrfield(buffer_ptr)); 22 printf("PHASE: %02d ", 23 upc_phaseof(buffer_ptr)); 24 } 25 } 26 return 0; 27 }
第14行,使得buffer_ptr指向第二个块的最后一个元素buffer[5],打印结果应该是:线程号=1,phase=2
buffer_ptr = upc_resetphase(buffer_ptr);
函数功能:重置指针的phase,使其指向当前块的首元素。
如果把它放在上面程序的打印之前,phase值会变成0而不是2
这些函数的具体实现:略
3.5更多的例子
// Matrix Squaring shared double A [THREADS][THREADS], A_Sqr [THREADS][THREADS]; int main(void) { shared double *rows_ptrs [THREADS]; // Points to the rows double *cols_ptr; // Points to the local shared columns int i, j, k; double d; //Initialize the pointers for(i=0; i < THREADS; i++) { rows_ptrs [i] = &A [i][0]; } // Privatize (local shared to private) cols_ptr = (double *)&A [0][MYTHREAD]; // Matrix squaring computation for(i=0; i<THREADS; i++) // for each row upc_forall(j=0; j<THREADS; j++; j) // each thread { // computes one element d = 0; for(k=0; k<THREADS; k++) d += *(rows_ptrs [i]+k) * *(cols_ptr+k); A_Sqr [i][j] = d; // write to A_sqr [row i][col j] } return 0; }
上面是一个计算矩阵平方的程序
cols_ptr = (double *)&A [0][MYTHREAD];//&A[0][i]是一个共享的引用,而cols_ptrs是私有指针,需要进行类型转换
这里使用了一个元素类型为指向共享对象的私有指针的数组,用以访问每一行。也可以用单指针,见下面的例子:
1 // Matrix Squaring (single pointer) 2 shared double A [THREADS][THREADS], A_Sqr [THREADS][THREADS]; 3 int main(void) 4 { 5 shared double *rows_ptrs; 6 double *cols_ptr; 7 int i, j, k; 8 double d; 9 // Initialize the pointers 10 rows_ptrs = &A [0][0]; 11 cols_ptr = (double *)&A [0][MYTHREAD]; 12 // for each row 13 for(i=0; i<THREADS; i++, rows_ptrs+=THREADS) 14 upc_forall(j=0; j<THREADS; j++; j) // for each local 15 // shared column 16 { 17 d = 0; 18 for(k=0; k<THREADS; k++) 19 d += *(rows_ptrs+k) * *(cols_ptr+k); 20 A_Sqr [i][j] = d; // write to A_sqr [row i][col j] 21 } 22 return 0; 23 }
如果将这个程序的算法封装到一个函数中,则是:
1 // Matrix Squaring 2 shared double A [THREADS][THREADS], A_Sqr [THREADS][THREADS]; 3 void mat_squaring(shared double (*dst)[THREADS], 4 shared double (*src)[THREADS]) 5 { 6 shared double *rows_ptrs [THREADS]; 7 double *cols_ptr; 8 int i, j, k; 9 double d; 10 // Initialize the pointers 11 for(i=0; i<THREADS; i++) 12 rows_ptrs[i] = &src[i][0]; 13 // Privatize (local shared to private) 14 cols_ptr = (double *)&src[0][MYTHREAD]; 15 // Matrix squaring computation 16 for(i=0; i<THREADS; i++) // for each row 17 upc_forall(j=0; j<THREADS; j++; j) // each thread 18 { 19 d = 0; 20 for(k=0; k<THREADS; k++) 21 d += *(rows_ptrs[i]+k) * *(cols_ptr+k); 22 dst[i][j] = d; 23 } 24 } 25 int main(void) 26 { 27 mat_squaring(A_Sqr, A); 28 return 0; 29 }
注意:共享的对象全都定义在函数外部,以保证他们不再动态范围内(局部变量出了就被销毁)
3.6总结
略
注:
本系列所有内容均来自《UPC: Distributed Shared Memory Programming》。这些文章是为了期中考试临时抱佛脚的结果···若有谬误,敬请指教。
All contents in this article are from <UPC: Distributed Shared Memory Programming>, if this has violated your copyright, contact me immediately at yanwt2013@gmail.com. Thank you.