Unified Parallel C - 统一并行C语言。用于并行计算和编程,是C语言的一个扩充版本。
转载任何内容都请注明出处,谢谢。
2.1 编程模型
单处理器系统:von Neumann模型
常见的并行编程模型parallel programming model:消息传递message passing,共享内存shared memory,并行数据data parallel,以及,分布式共享内存distributed shared memory。
UPC使用分布式共享内存模型。
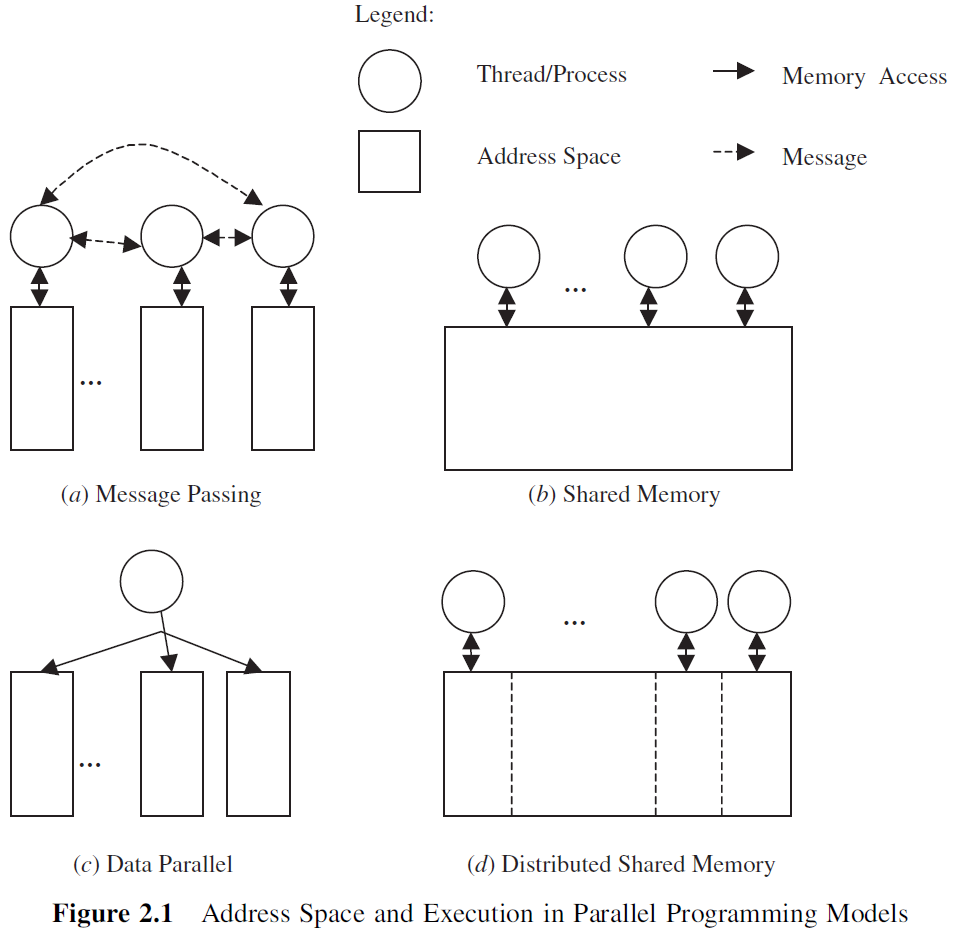
此处略去一万字对前三个的废话介绍·····························
UPC使用的这个模型,所有的线程是独立的,但是都在一个共有的内存空间上操作。但他也不是完全的共有,这块内存会被逻辑划分(logically partitioned)。线程与其被划分到的那块数据会被一起映射到同一个物理结点上。
此处省略一万字此模型的好处····································
2.2 UPC的编程模型
UPC以SPMD模式运行(single program, multiple data stream),每个线程都会去执行main()函数,我们用不同的数据流控制条件让每个线程执行code中的一部分。
UPC与标准DSM又不完全一样,对于本地计算,他有额外的私有地址空间
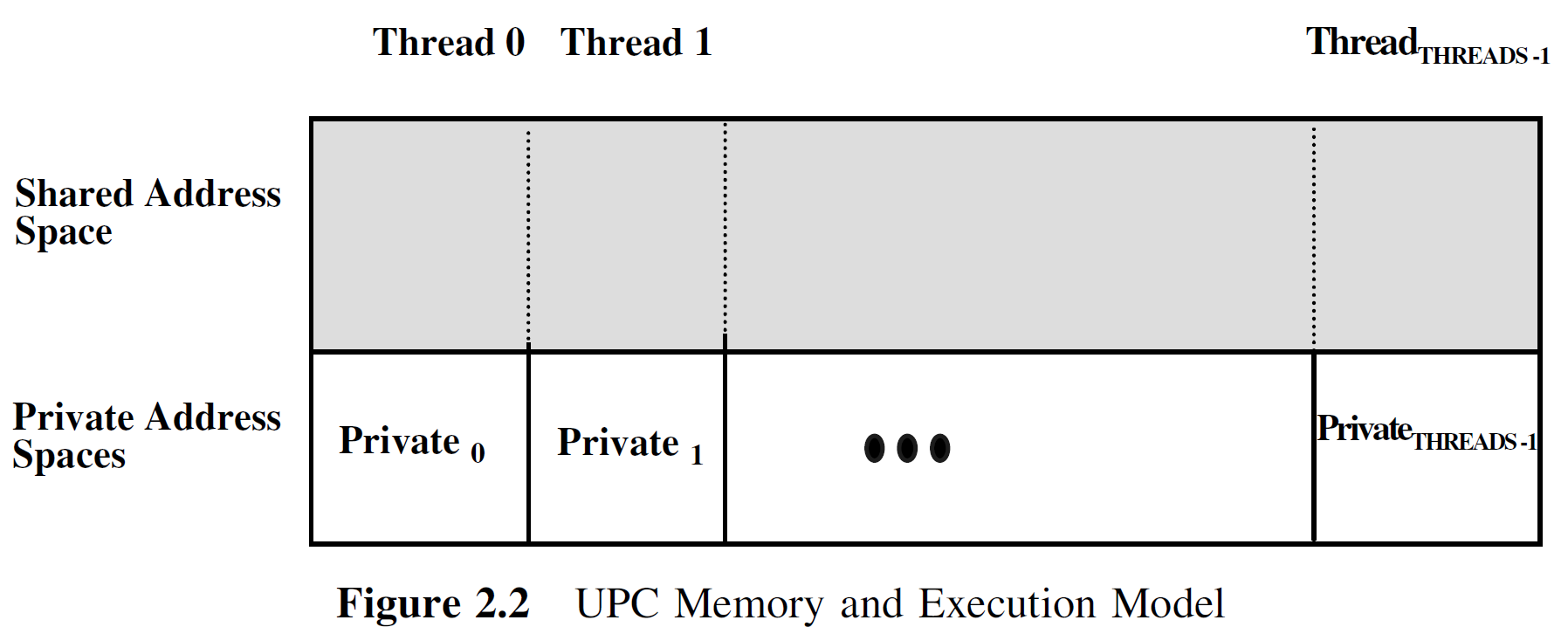
共享空间里随便引用····私有空间只能访问自己的。无论公有私有,UPC都有访问的指针
UPC允许将多个线程映射到同一个CPU上。
2.3 共享与私有变量
私有对象在每个线程中都有一个实例。thread 0 很特殊,所有的标量共享对象都会被分配给他。(UPC默认创建私有对象)
共享数组的第一个元素也会与thread 0相关联。
共享变量没有自动存储期限automatic storage duration
void foo(void) { shared int x; // not allowed走出大括号}就消失,但又要他共享,矛盾,不允许 static shared int y; // allowed加上静态属性就可以 shared int *p; // allowed私有指针指向共享类型,每个线程有一个私有指针指向共享空间 int *shared q; // not allowed同理,共享指针不能作为局部变量 ... }
修改为正确的:
shared int x; int *shared q; void foo(void) { shared int *p; ... }
2.4共享与私有数组
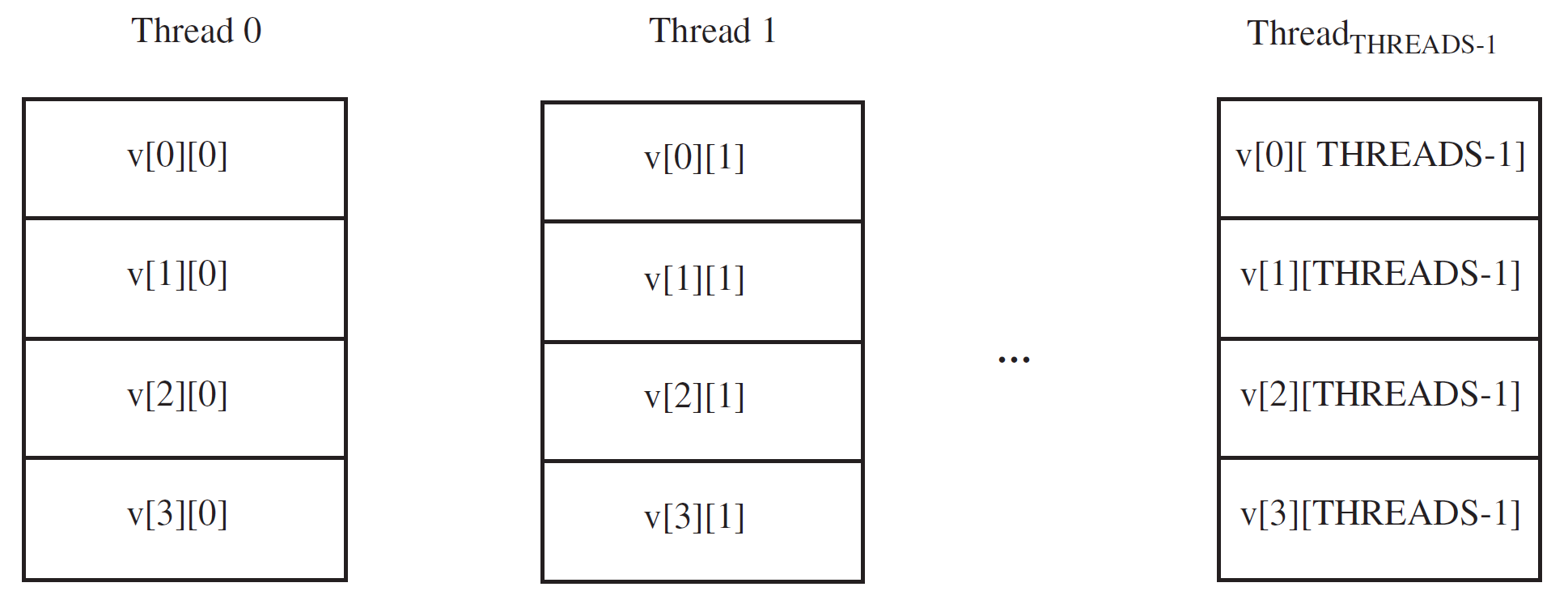
共享数组的元素以轮转法分配给每个线程
shared int x; /* x is a shared scalar and will have affinity to thread 0 */ shared int y [THREADS]; /*shared array*/ int z; /*private scalar*/

所以·····这时候看出来为什么之前upc_forall循环里最后一个是i modulo THREADS了吧,这样每个线程每次处理的就是自己对应位置的那一列数据
如果去掉shared,每个线程都有一个自己的大小一样的数组。
高维数组同理
shared int A [4][THREADS];
1 #include <upc_relaxed.h>//upc_relaxed explained in Chapter 6 2 #define N 10 * THREADS 3 shared int v1[N], v2[N], v1plusv2[N]; 4 int main () 5 { 6 int i; 7 upc_forall (i = 0; i < N; i ++; i) 8 v1plusv2 [i] = v1 [i] + v2 [i]; 9 return 0; 10 }
典型的例子,数组元素以轮转法分布,迭代也以轮转法循环作用于每个线程上。
2.5 Blocked Shared Arrays
1 #include <upc_relaxed.h> 2 shared int a [THREADS][THREADS]; 3 shared int b [THREADS], c [THREADS]; 4 int main (void) 5 { 6 int i, j; 7 upc_forall(i = 0; i < THREADS; i++; i) 8 { 9 c [i] = 0; 10 for (j= 0; j <THREADS; j++) 11 c [i] += a [i][j]*b [j]; 12 } 13 return 0; 14 }
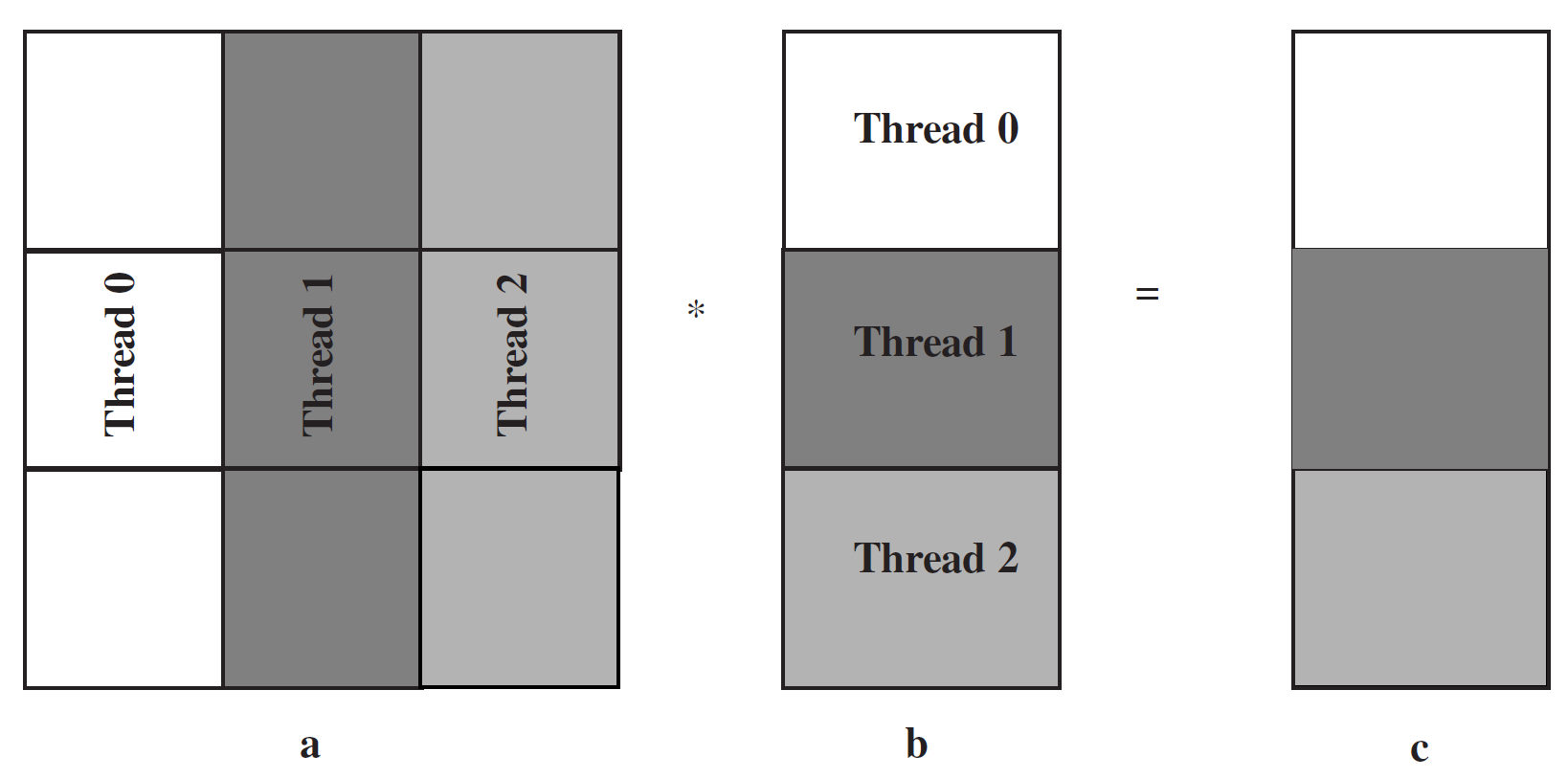
根据以上程序的算法(矩阵乘法),每次计算C[i]时,只有a[i][i]和b[i]是本地操作对象,剩下四个操作数都是远端对象(假设线程数为3)。
默认的共享内存分布模式是可以改变的,只需要给出块大小(block size)也称作blocking factor:
shared [block-size]array [number-of-elements]
如:shared[4] int a[16]
一个16个整型元素的数组,4个4个为一块(block),仍以轮转法分配。一个成块分布的数组的第i个元素与以下线程关联:(i/blocksize)mod THREADS
又如:shared [3] int x [12];

如果想把所有元素都给thread 0,有以下两种方法:

连续块(contiguous blocks)分布:使用*
shared [*] int y[8];
高维数组同理·······
1 shared [THREADS] int a[THREADS][THREADS]; 2 shared int b [THREADS], c [THREADS]; 3 int main (void) 4 { 5 int i, j; 6 upc_forall(i = 0; i < THREADS; i++; i) 7 { 8 c [i] = 0; 9 for (j= 0; j (THREADS; j++) 10 c [i] += a [i][j]*b [j]; 11 } 12 return 0;
唯一的区别在于,数组a被块大小THREADS限制,也就是说,块大小等于总线程数
之前:
现在:

计算c[i]只需要一次远程访问(remote access),比之前的四次大大减少
2.6 共享内存在不同编译环境下要注意的地方
在编译时给出线程数是推荐的,称作static THREADS;否则称dynamic THREADS
虽然运行时给出线程数会很方便,但对编译器来说会出现问题,因为给每个线程分配的数组元素数取决于线程数量。故而dynamic THREADS 环境下声明数组是非法的。
以下在两种情况下均正确:
shared int x [10*THREADS]; shared [] int x [10];
第二个很容易理解;至于第一个,每个线程会被分配到10个元素,因此不管什么时候指出线程数都可以。
以下在动态情况下非法:
shared int x [10]; shared [] int x [THREADS]; shared int x [10+THREADS];
2.7 总结
略
注:
本系列所有内容均来自《UPC: Distributed Shared Memory Programming》。这些文章是为了期中考试临时抱佛脚的结果···若有谬误,敬请指教。
All contents in this article are from <UPC: Distributed Shared Memory Programming>, if this has violated your copyright, contact me immediately at yanwt2013@gmail.com. Thank you.