摘要 在jdk7的中
hashmap,它的底层数据结构使用的是数组+链表的形式,而到了jdk8中又新增加了红黑树,同时将链表的头插法改为了尾插法。
正文
无论是jdk7还是jdk8的hashmap实现都离不开链表和数组,我们知道,不管是链表还是数组都是用来存储数据的,那为什么hashmap的实现这两种数据结构都要使用呢?这其实还要从数组和链表的特征说起。
数组
我们知道,数组的存储区间是连续的,即程序会分配一段连续的内存空间给一个数组,所以数组的空间复杂度很大,但是时间复杂度却很低,为O(1)。
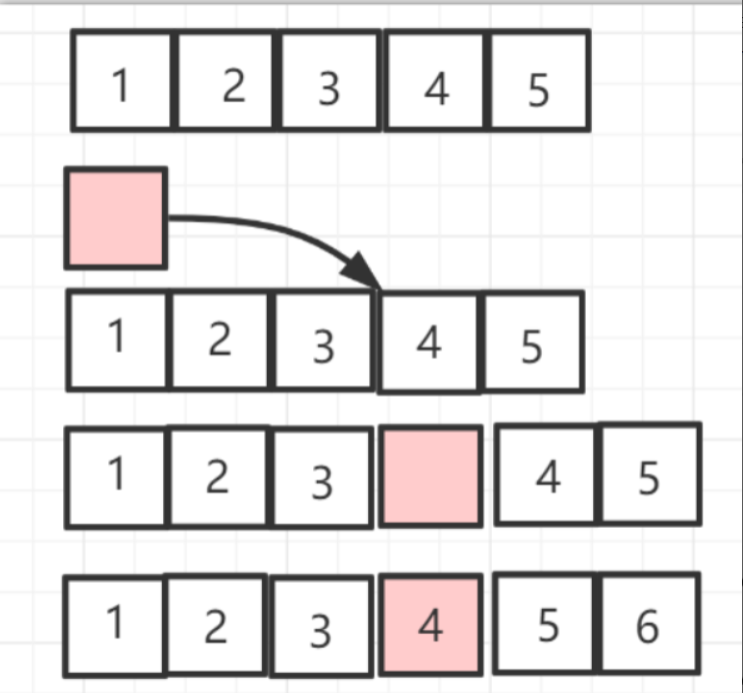
而由于数组是连续的,所以它数组查找的效率就很高。直接通过下标就可以获取。而数组的插入和删除操作效率却比较低。会影响到后面所有的元素。
如图是数组的插入操作,删除操作类似。
链表
链表并非连续存储的,占用内存较宽松,空间复杂度较低,而时间复杂度是O(N)。
链表的优点是插入删除较快,而查找会比较慢。
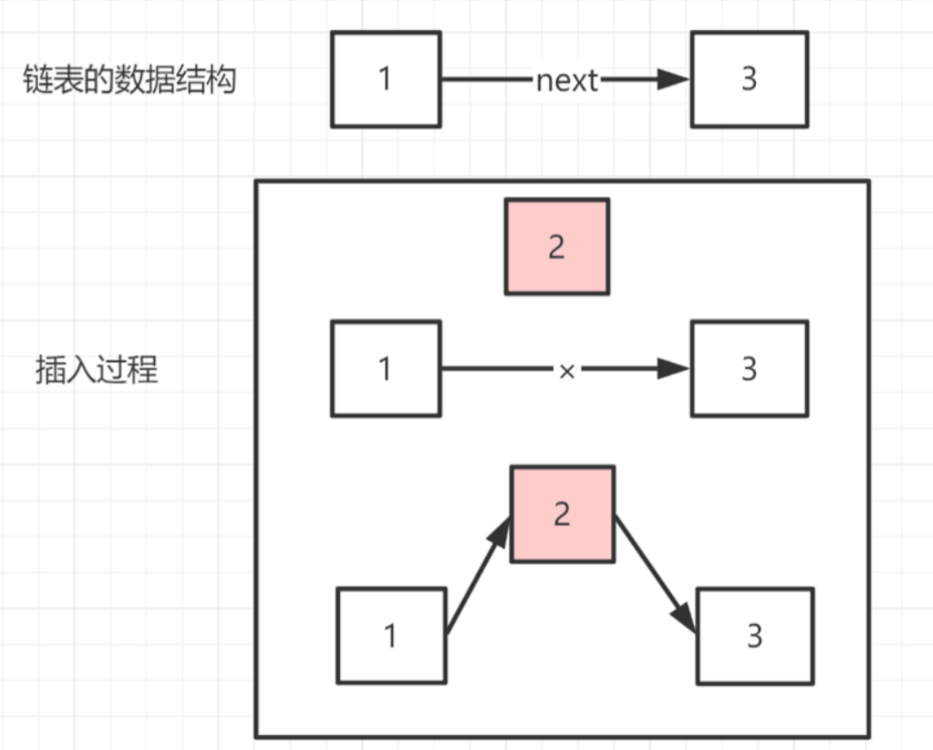
代码示例:
Node<String, String> node2 = new Node<>("name","张三");
Node<String, String> node = new Node<>("age","李四", node2);
Node<String, String> node1 = new Node<>("age1","李四");
/**将node1插入到node和node2之间
* 现在有的链:node -> node2
* 转换的效果:node -> node1 -> node2
*/
// 插入
/**
* 1、将node的next指向待插入的元素的next
* 2、将待插入元素指向上一元素的next
*/
node1.next = node.next;
node.next = node1;
System.out.println(node.next.getKey());
System.out.println(node1.next.getKey());
hashmap存取过程
在hashmap中,同时使用数组和链表作为数据结构,称之为哈希表,如果在初始化时不指定大小的话,默认的哈希表长度是16。
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
存值流程:
- 当调用
hashmap的put方法时,会首先去计算出key的哈希值,这个哈希值将会决定该元素在数组中的存放位置。
/* 会调用这个put方法 */
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/* 计算出key的哈希值 */
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
- 然后会进行数据的存储操作。如果数组为空,则会调用
resize()方法进行初始化,默认大小是16。值得注意的是,后面数组的扩容也是通过这个方法来完成的。 - 通过计算出来的哈希值找到在数组中的位置,如果该位置为空,则新增一个节点插入。否则就会进到else分支中去处理哈希冲突。
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
// tab就是hashmap中用于存储数据的数组
// p就是hashmap中的链表
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
// 如果没有冲突就将数据放到该下标
tab[i] = newNode(hash, key, value, null);
else { // 处理哈希冲突
Node<K,V> e; K k;
// 检查第一个节点
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
// 挂载数据
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//treeifyBin首先判断当前hashMap的长度,如果不足64,只进行
//resize,扩容table,如果达到64,那么将冲突的存储结构为红黑树
treeifyBin(tab, hash);
break;
}
// 有相同的key就结束
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 判断链表是否需要扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
从上面代码中我们可以看出来,hashmap在存储数据时实际上是调用了一个名为newNode的方法,通过该方法将数据保存到了hashmap中。
tab[i] = newNode(hash, key, value, null);
通过对源码的追踪发现,newNode方法实际上就是new了一个Node对象,该对象有4个属性,分别保存哈希值、键、值和下一节点。
// Create a regular (non-tree) node
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
}
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
取值流程:
- 通过key的哈希值得到该值在数组中的位置。
- 判断第一个节点是否是要查找的值,如果是,直接返回。
- 如果不是,则先会判断子节点类型(红黑树还是普通链表),再去分别查找。
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
// 判断位置是否存在
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 判断链表的第一个节点是否是待查找的key
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 判断next是否存在
if ((e = first.next) != null) {
// 如果是红黑树(TreeNode代表红黑树)
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// (不是红黑树)
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
哈希冲突
在hashmap中通过哈希算法将哈希值映射到数组中的某一位置。而随着数组中的数据越来越多,多个数据映射到一个位置的事情总是不能避免的。这就是我们常说的哈希冲突,也叫做哈希碰撞。在jdk7中,处理哈希冲突的方式就是采用头插法(将新要插入的元素放到该位置,原来的元素放到新元素的后面,就形成了链表),而到了jdk8中改为使用尾插法(新元素放在旧元素后面)(笔者也暂时不了解原因,好像是跟线程安全有关)。
扩容机制
上面说到,hashmap中存在着一个专门用于扩容的方法:resize(),当数组的占用率大于数组长度乘以加载因子的时候,会触发扩容。默认的加载因子是0.75。
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
下面是resize()方法的源代码,笔者在上面写了一些注释,方便自己理解。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
// 如果旧数组长度大于0
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 将新数组设置为旧数组长度的两倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 同时调整阈值为原来的2倍
newThr = oldThr << 1; // double threshold
}
// 如果旧的阈值大于0,将初始容量设置为和阈值一样
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
// 使用默认容量
newCap = DEFAULT_INITIAL_CAPACITY;
// 设置 阈值 = 默认加载因子(0.75)* 默认容量
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
// 开始构造新的数组
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
//把新表赋值给table
table = newTab;
if (oldTab != null) {
// 把原表中数据移动到新表中
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// 说明这个node没有链表直接放在新表的e.hash & (newCap - 1)位置
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order 保证顺序
/** 如果e后边有链表,到这里表示e后面带着个单链表,需要遍历单链表
* 将每个节点在新链表中位置计算出来并放入
*/
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 新表是旧表的两倍容量,实例上就把单链表拆分为两队,
//
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
红黑树
在jdk7中并没有引入红黑树的概念,只是使用了数组和链表来实现。当存储的数据量变多之后,或者是哈希冲突频繁产生的场景下,就会出现链表过长的情况。类似于这样:

这种情况出现之后,对于数据的获取就显得不够友好了。我们知道,链表的查找会从头节点一直挨个遍历直到找到,所以链表的查找时间复杂度是O(N)。所以在jdk8中,对此做出了优化,引进了红黑树进行查找优化。
以下是红黑树在jdk8中的表现形式:
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
}
当每条链表的长度较大时(大于8),就会将链表转化为红黑树。值得注意的是,想要转换为红黑树还需要满足另一个条件,那就是数组的长度需要大于64,否则即使链表长度过长也只会进行数组的扩容而不会进行链表的转化。
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
// 判断数组长度是否小于`MIN_TREEIFY_CAPACITY`
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
/**
* The smallest table capacity for which bins may be treeified.
* (Otherwise the table is resized if too many nodes in a bin.)
* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
* between resizing and treeification thresholds.
*/
static final int MIN_TREEIFY_CAPACITY = 64;
总结
本文主要介绍了jdk中常用的hashmap的底层实现原理。我们一般在使用时采用键值对的形式,而实际上在hashmap中每一个键值对都是采用对象的方式存储。hashmap底层采用数组和链表的数据结构,介绍了哈希冲突产生的原因以及解决方法,而由于数组的大小初始化的时候便确定了,所以在hashmap中有自己的扩容机制。当存储的数据越来越多的时候,在jdk8中又采用红黑树的数据结构对查询进行了优化。
关于哈希算法和红黑树,笔者将在后面的文章在介绍。
持续更新~