库的安装:requests , BeautifulSoup
request 基本方法:
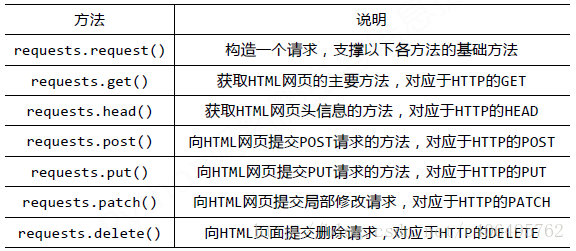
request官方教程:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
注意:
如果直接
print(requests.get(url = target))
得到的是<Response [200]>
正确做法:
print(requests.get(url = target).text)
get返回的是一个response对象,里面有各种变量,需要的是其中叫text的那一个。直接print这个response对象的结果完全取决于开发者对__repr__或者__str__的重写情况。
beautifulsoup
bf = BeautifulSoup(requests.get(url = target).text,'html.parser') #创建一个BeautifulSoup对象,注意需要添加解析格式xml或html.parser
find_all 根据指定的标签及属性,获取目标内容
texts = bf.find_all('div', class_ = 'showtxt') #find_all获取目标内容
此时得到的结果仍旧有许多换行标签如<br>和空格符 ,使用.text 和replace
print(texts[0].text.replace('xa0'*8, ' ')) #find_all 返回的是一个列表,从列表内容中筛选出text内容即文本,再进行replace替换('被替换的','替换成的')
将八个空格变成换行
自动下载txt小说
from bs4 import BeautifulSoup import requests, sys """ 类说明:下载《笔趣看》网小说《一念永恒》 Parameters: 无 Returns: 无 Modify: 2017-09-13 """ class downloader(object): def __init__(self): self.server = 'http://www.biqukan.com/' self.target = 'http://www.biqukan.com/1_1094/' self.names = [] #存放章节名 self.urls = [] #存放章节链接 self.nums = 0 #章节数 """ 函数说明:获取下载链接 Parameters: 无 Returns: 无 Modify: 2017-09-13 """ def get_download_url(self): req = requests.get(url = self.target) html = req.text div_bf = BeautifulSoup(html) div = div_bf.find_all('div', class_ = 'listmain') a_bf = BeautifulSoup(str(div[0])) a = a_bf.find_all('a') self.nums = len(a[15:]) #剔除不必要的章节,并统计章节数 for each in a[15:]: self.names.append(each.string) self.urls.append(self.server + each.get('href')) """ 函数说明:获取章节内容 Parameters: target - 下载连接(string) Returns: texts - 章节内容(string) Modify: 2017-09-13 """ def get_contents(self, target): req = requests.get(url = target) html = req.text bf = BeautifulSoup(html) texts = bf.find_all('div', class_ = 'showtxt') texts = texts[0].text.replace('xa0'*8,' ') return texts """ 函数说明:将爬取的文章内容写入文件 Parameters: name - 章节名称(string) path - 当前路径下,小说保存名称(string) text - 章节内容(string) Returns: 无 Modify: 2017-09-13 """ def writer(self, name, path, text): write_flag = True with open(path, 'a', encoding='utf-8') as f: f.write(name + ' ') f.writelines(text) f.write(' ') if __name__ == "__main__": dl = downloader() dl.get_download_url() print('《一年永恒》开始下载:') for i in range(dl.nums): dl.writer(dl.names[i], '一念永恒.txt', dl.get_contents(dl.urls[i])) sys.stdout.write(" 已下载:%.3f%%" % float(i/dl.nums) + ' ') sys.stdout.flush() print('《一年永恒》下载完成')