Tensorflow是当下AI热潮下,最为受欢迎的开源框架。无论是从Github上的fork数量还是star数量,还是从支持的语音,开发资料,社区活跃度等多方面,他当之为superstar。
在前面介绍了如何搭建Tensorflow的运行环境后(包括CPU和GPU的),今天就从MNIST手写识别的源码上分析一下,tensorflow的工作原理,重点是介绍CNN的一些基本理论,作为扫盲入门,也作为自己的handbook吧。
Architecture
首先,简单的说下,tensorflow的基本架构。
使用 TensorFlow, 你必须明白 TensorFlow:
- 使用图 (graph) 来表示计算任务.
- 在被称之为
会话 (Session)的上下文 (context) 中执行图.- 使用 tensor 表示数据.
- 通过
变量 (Variable)维护状态.- 使用 feed 和 fetch 可以为任意的操作(arbitrary operation) 赋值或者从其中获取数据.
Tensor
TensorFlow 是一个编程系统, 使用图来表示计算任务. 图中的节点被称之为 op (operation 的缩写). 一个 op 获得 0 个或多个 Tensor, 执行计算, 产生 0 个或多个 Tensor. 每个 Tensor 是一个类型化的多维数组. 例如, 你可以将一小组图像集表示为一个四维浮点数数组, 这四个维度分别是 [batch, height, width, channels].
一个 TensorFlow 图描述了计算的过程. 为了进行计算, 图必须在 会话 里被启动. 会话 将图的 op 分发到诸如 CPU 或 GPU 之类的 设备 上, 同时提供执行 op 的方法. 这些方法执行后, 将产生的 tensor 返回. 在 Python 语言中, 返回的 tensor 是 numpy ndarray 对象; 在 C 和 C++ 语言中, 返回的 tensor 是tensorflow::Tensor 实例.
Tensor是tensorflow中非常重要且非常基础的概念,可以说数据的呈现形式都是用tensor表示的。输入输出都是tensor,tensor的中文含义,就是张量,可以简单的理解为线性代数里面的向量或者矩阵。
Graph
TensorFlow 程序通常被组织成一个构建阶段和一个执行阶段. 在构建阶段, op 的执行步骤 被描述成一个图. 在执行阶段, 使用会话执行执行图中的 op.
例如, 通常在构建阶段创建一个图来表示和训练神经网络, 然后在执行阶段反复执行图中的训练 op. 下面这个图,就是一个比较形象的说明,图中的每一个节点,就是一个op,各个op透过tensor数据流向形成边的连接,构成了一个图。
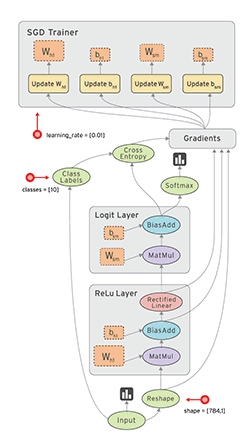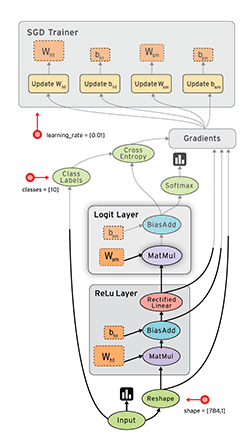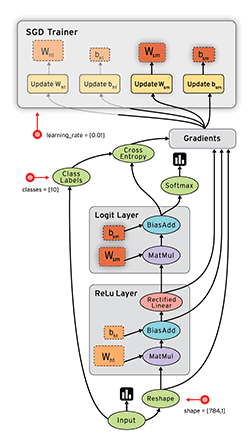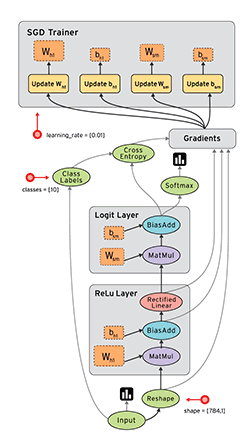
构建图的第一步, 是创建源 op (source op). 源 op 不需要任何输入, 例如 常量 (Constant). 源 op 的输出被传递给其它 op 做运算. Python 库中, op 构造器的返回值代表被构造出的 op 的输出, 这些返回值可以传递给其它 op 构造器作为输入.
TensorFlow Python 库有一个默认图 (default graph), op 构造器可以为其增加节点. 这个默认图对 许多程序来说已经足够用了.
Session
当图构建好后,需要创建一个Session来运行构建好的图,来实现逻辑,创建session的时候,若无任何参数,tensorflow将启用默认的session。session.run(xxx)是比较典型的使用方案, session运行结束后,返回值是一个tensor。
tensorflow中的session,有两大类,一种就是普通的session,即tensorflow.Session(),还有一种是交互式session,即tensorflow.InteractiveSession(). 使用Tensor.eval() 和Operation.run()方法代替Session.run(). 这样可以避免使用一个变量来持有会话, 为程序架构的设计添加了灵活性.
到此,亲,你是否已经感觉到tensorflow有个特点,处理业务逻辑上,很像Mapreduce架构里面,先将数据按照一定的数据结构组织好,将逻辑单位进行排布,也是分阶段的,也是侧重数据集中型的业务。
数据载体
Tensorflow体系下,变量(Variable)是用来维护图计算过程中的中间状态信息,是一种常见高频使用的数据载体,还有一种特殊的数据载体,那就是常量(Constant),主要是用作图处理过程的输入量。这些数据载体,也都是以Tensor的形式体现。变量定义和常量定义上,比较好理解:
# 创建一个变量, 初始化为标量0.没有指定数据类型(dtype)
state = tf.Variable(0, name="counter")
# 创建一个常量,其值为1,没有指定数据类型(dtype)
one = tf.constant(1)针对上面的变量和常量,看看Tensorflow里面的函数定义:
class Variable(object):
def __init__(self,
initial_value=None,
trainable=True,
collections=None,
validate_shape=True,
caching_device=None,
name=None,
variable_def=None,
dtype=None,
expected_shape=None,
import_scope=None):
def constant(value, dtype=None, shape=None, name="Const", verify_shape=False):
从上面的源码可以看出,定义变量,其实就是定义了一个Variable的实例,而定义常量,其实就是调用了一下常量函数,创建了一个常量Tensor。
还有一个很重要的概念,那就是占位符placeholder,这个在Tensorflow中进行Feed数据灌入时,很有用。所谓的数据灌入,指的是在创建Tensorflow的图时,节点的输入部分,就是一个placeholder,后续在执行session操作的前,将实际数据Feed到图中,进行执行即可。
input1 = tf.placeholder(tf.types.float32)
input2 = tf.placeholder(tf.types.float32)
output = tf.mul(input1, input2)
with tf.Session() as sess:
print sess.run([output], feed_dict={input1:[7.], input2:[2.]})
# 输出:
# [array([ 14.], dtype=float32)]占位符的定义原型,也是一个函数:
def placeholder(dtype, shape=None, name=None):
到此,Tensorflow的入门级的基本知识介绍完了。下面,将结合一个MNIST的手写识别的例子,从代码上简单分析一下,下面是源代码:

#!/usr/bin/env python # -*- coding: utf-8 -*- import tensorflow as tf #加载测试数据的读写工具包,加载测试手写数据,目录MNIST_data是用来存放下载网络上的训练和测试数据的。 #这里,参考我前面的博文,由于网络原因,测试数据,我单独下载后,放在当前目录的MNIST_data目录了。 import tensorflow.examples.tutorials.mnist.input_data as input_data mnist = input_data.read_data_sets("MNIST_data", one_hot=True) #创建一个交互式的Session。 sess = tf.InteractiveSession() #创建两个占位符,数据类型是float。x占位符的形状是[None,784],即用来存放图像数据的变量,图像有多少张 #是不关注的。但是图像的数据维度有784围。怎么来的,因为MNIST处理的图片都是28*28的大小,将一个二维图像 #展平后,放入一个长度为784的数组中。 #y_占位符的形状类似x,只是维度只有10,因为输出结果是0-9的数字,所以只有10种结构。 x = tf.placeholder("float", shape=[None, 784]) y_ = tf.placeholder("float", shape=[None, 10]) #通过函数的形式定义权重变量。变量的初始值,来自于截取正态分布中的数据。 def weight_variable(shape): initial = tf.truncated_normal(shape, stddev=0.1) return tf.Variable(initial) #通过函数的形式定义偏置量变量,偏置的初始值都是0.1,形状由shape定义。 def bias_variable(shape): initial = tf.constant(0.1, shape=shape) return tf.Variable(initial) #定义卷积函数,其中x是输入,W是权重,也可以理解成卷积核,strides表示步长,或者说是滑动速率,包含长宽方向 #的步长。padding表示补齐数据。 目前有两种补齐方式,一种是SAME,表示补齐操作后(在原始图像周围补充0),实 #际卷积中,参与计算的原始图像数据都会参与。一种是VALID,补齐操作后,进行卷积过程中,原始图片中右边或者底部 #的像素数据可能出现丢弃的情况。 def conv2d(x, W): return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME') #这步定义函数进行池化操作,在卷积运算中,是一种数据下采样的操作,降低数据量,聚类数据的有效手段。常见的 #池化操作包含最大值池化和均值池化。这里的2*2池化,就是每4个值中取一个,池化操作的数据区域边缘不重叠。 #函数原型:def max_pool(value, ksize, strides, padding, data_format="NHWC", name=None)。对ksize和strides #定义的理解要基于data_format进行。默认NHWC,表示4维数据,[batch,height,width,channels]. 下面函数中的ksize, #strides中,每次处理都是一张图片,对应的处理数据是一个通道(例如,只是黑白图片)。长宽都是2,表明是2*2的 #池化区域,也反应出下采样的速度。 def max_pool_2x2(x): return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') #定义第一层卷积核。shape在这里,对应卷积核filter。 #其中filter的结构为:[filter_height, filter_width, in_channels, out_channels]。这里,卷积核的高和宽都是5, #输入通道1,输出通道数为32,也就是说,有32个卷积核参与卷积。 W_conv1 = weight_variable([5, 5, 1, 32]) #偏置量定义,偏置的维度是32. b_conv1 = bias_variable([32]) #将输入tensor进行形状调整,调整成为一个28*28的图片,因为输入的时候x是一个[None,784],有与reshape的输入项shape #是[-1,28,28,1],后续三个维度数据28,28,1相乘后得到784,所以,-1值在reshape函数中的特殊含义就可以映射程None。即 #输入图片的数量batch。 x_image = tf.reshape(x, [-1,28,28,1]) #将2维卷积的值加上一个偏置后的tensor,进行relu操作,一种激活函数,关于激活函数,有很多内容需要研究,在此不表。 h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) #对激活函数返回结果进行下采样池化操作。 h_pool1 = max_pool_2x2(h_conv1) #第二层卷积,卷积核大小5*5,输入通道有32个,输出通道有64个,从输出通道数看,第二层的卷积单元有64个。 W_conv2 = weight_variable([5, 5, 32, 64]) b_conv2 = bias_variable([64]) #类似第一层卷积操作的激活和池化 h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) h_pool2 = max_pool_2x2(h_conv2) #图片尺寸减小到7x7,加入一个有1024个神经元的全连接层,用于处理整个图片。把池化层输出的张量reshape成一些 #向量,乘上权重矩阵,加上偏置,然后对其使用ReLU激活操作。 W_fc1 = weight_variable([7 * 7 * 64, 1024]) b_fc1 = bias_variable([1024]) #将第二层池化后的数据进行变形 h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64]) #进行矩阵乘,加偏置后进行relu激活 h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) keep_prob = tf.placeholder("float") #对第二层卷积经过relu后的结果,基于tensor值keep_prob进行保留或者丢弃相关维度上的数据。这个是为了防止过拟合,快速收敛。 h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob) W_fc2 = weight_variable([1024, 10]) b_fc2 = bias_variable([10]) #最后,添加一个softmax层,就像前面的单层softmax regression一样。softmax是一个多选择分类函数,其作用和sigmoid这个2值 #分类作用地位一样,在我们这个例子里面,softmax输出是10个。 y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2) #实际值y_与预测值y_conv的自然对数求乘积,在对应的维度上上求和,该值作为梯度下降法的输入 cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv)) #下面基于步长1e-4来求梯度,梯度下降方法为AdamOptimizer。 train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) #首先分别在训练值y_conv以及实际标签值y_的第一个轴向取最大值,比较是否相等 correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1)) #对correct_prediction值进行浮点化转换,然后求均值,得到精度。 accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) #先通过tf执行全局变量的初始化,然后启用session运行图。 sess.run(tf.global_variables_initializer()) for i in range(20000): #从mnist的train数据集中取出50批数据,返回的batch其实是一个列表,元素0表示图像数据,元素1表示标签值 batch = mnist.train.next_batch(50) if i%100 == 0: #计算精度,通过所取的batch中的图像数据以及标签值还有dropout参数,带入到accuracy定义时所涉及到的相关变量中,进行 #session的运算,得到一个输出,也就是通过已知的训练图片数据和标签值进行似然估计,然后基于梯度下降,进行权值训练。 train_accuracy = accuracy.eval(feed_dict={x:batch[0], y_: batch[1], keep_prob: 1.0}) print "step %d, training accuracy %g"%(i, train_accuracy) #此步主要是用来训练W和bias用的。基于似然估计函数进行梯度下降,收敛后,就等于W和bias都训练好了。 train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5}) #对测试图片和测试标签值以及给定的keep_prob进行feed操作,进行计算求出识别率。就相当于前面训练好的W和bias作为已知参数。 print "test accuracy %g"%accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0})
代码是tensorflow的案例,这里,重点是对代码的理解,重点是对卷积的逻辑的理解。涉及到几个概念,什么是卷积,什么是池化。
卷积,数学表达式如下:

卷积,是一个比较抽象的概念,表示一个输入信号,经过一个系统作用后,得到输出结果。通过一个比喻来让大家对卷积有个感性的认识(这回比喻,来自网络):
比如说你的老板命令你干活,你却到楼下打台球去了,后来被老板发现,他 非常气愤,扇了你一巴掌(注意,这就是输入信号,脉冲),于是你的脸上会渐渐地鼓起来一个包,你的脸就是一个系统,而鼓起来的包就是你的脸对巴掌的响应,好,这样就和信号系统建立起来意义对应的联系。下面还需要一些假设来保证论证的严谨:假定你的脸是线性时不变系统,也就是说,无论什么时候老板打你一巴掌,打在你脸的同一位置,你的脸上总是会在相同的时间间隔内鼓起来一个相同高度的包,并且假定以鼓起来的包的大小作为系统输出。好了,下面可以进入核心内容——卷积了!
如果你每天都到地下去打台球,那么老板每天都要扇你一巴掌,不过当老板打你一巴掌后,你5分钟就消肿了,所以时间长了,你甚至就适应这种生活了……如果有一天,老板忍无可忍,以0.5秒的间隔开始不间断的扇你的过程,这样问题就来了,第一次扇你鼓起来的包还没消肿,第二个巴掌就来了,你脸上的包就可能鼓起来两倍高,老板不断扇你,脉冲不断作用在你脸上,效果不断叠加了,这样这些效果就可以求和了,结果就是你脸上的包的高度随时间变化的一个函数了(注意理解);如果老板再狠一点,频率越来越高,以至于你都辨别不清时间间隔了,那么,求和就变成积分了。可以这样理解,在这个过程中的某一固定的时刻,你的脸上的包的鼓起程度和什么有关呢?和之前每次打你都有关!但是各次的贡献是不一样的,越早打的巴掌,贡献越小,所以这就是说,某一时刻的输出是之前很多次输入乘以各自的衰减系数之后的叠加而形成某一点的输出,然后再把不同时刻的输出点放在一起,形成一个函数,这就是卷积,卷积之后的函数就是你脸上的包的大小随时间变化的函数。本来你的包几分钟就可以消肿,可是如果连续打,几个小时也消不了肿了,这难道不是一种平滑过程么?反映到剑桥大学的公式上,f(a)就是第a个巴掌,g(x-a)就是第a个巴掌在x时刻的作用程度,乘起来再叠加就ok了,大家说是不是这个道理呢?我想这个例子已经非常形象了,你对卷积有了更加具体深刻的了解了吗?
但是,对于CNN领域的卷积,不是连续信号的时域积分思路。而是输入图像X与卷积核W进行内积。卷积的过程,其实是一种特征提取的过程!
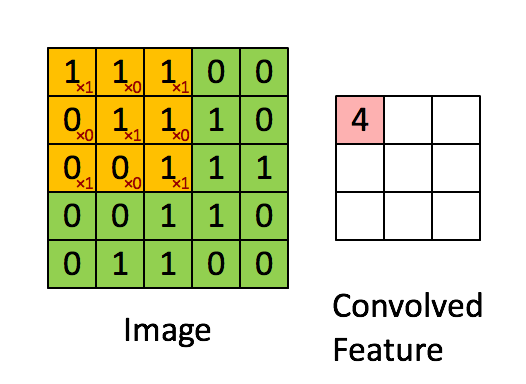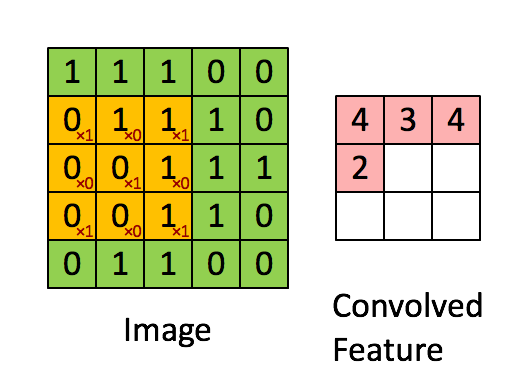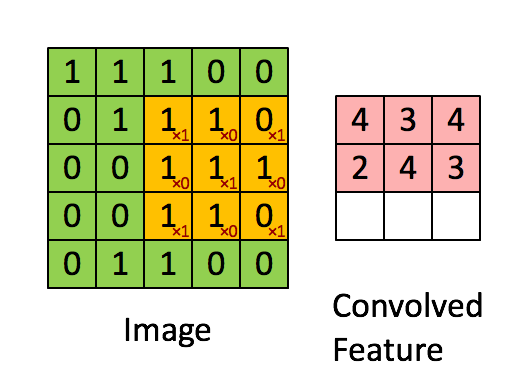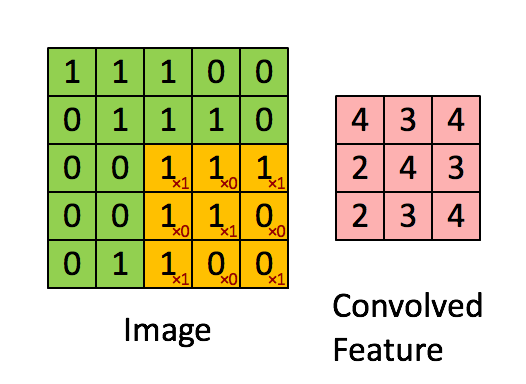
卷积过程,将原始输入图像进行了维度更新,通常会降低维度,如上述图示,输入5*5的图片,在3*3的卷积核作用下,输出为一个3*3的矩阵。
上述这种padding为SAME的情况下进行的卷积,如何计算输出结果的中有多少个特征值呢? 假如输入1张维度r*c的图片,经过K个卷积核的维度是a*b。那么,卷积后得到的特征值总数如下:
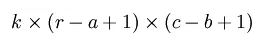
池化,是一种数据采样操作,有均值池化,最大值池化等分类。池化可以有效的降低特征值的数量,减少计算量。池化,是将一个区域的特征用一个特征来表示。如下图:


原始特征矩阵是12*12,池化单元是4*4,图中灰色区域表示4个池化区。左边的图和右边的图,利用MAX_POOLing,在池化后取值,比如左上角,将都会是1.也就是说,图像目标有少量位置移动,对于目标识别是不受影响的。池化可以抗干扰!
说完了卷积核池化这两个重要的CNN中的概念,下面这个多层卷积的图片,是不是可以理解每一层之间的数据传递关系了?
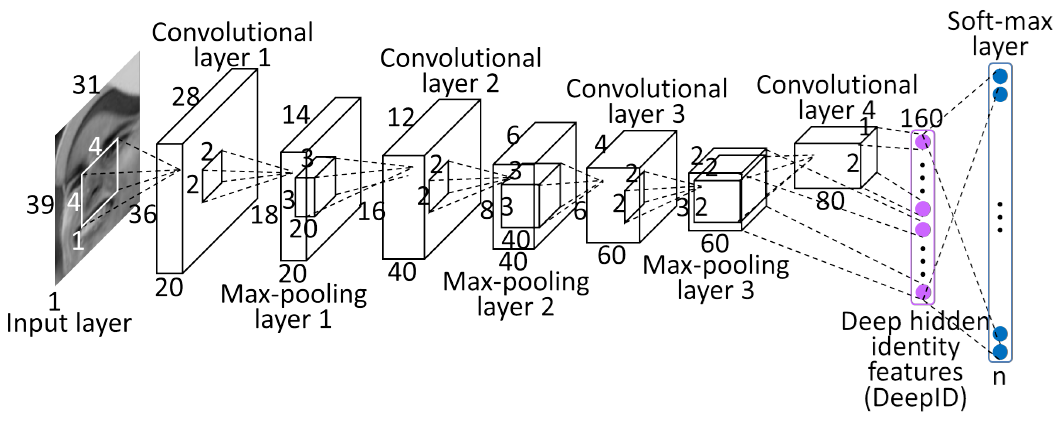
简单解释如下:
1.input layer:输入层是一个31*39的灰度图片,通道数是1,也可以理解输入图片的depth是1,很多论文或者技术文档中,输入通道数(in_channels)或者图片厚度(depth)都有用到。
2.convolutional layer 1: 第一层卷积层,卷积核大小为4*4,输出结果厚度depth为20,表示有20个4*4的卷积核与输入图片进行特征提取。卷基层神经元的大小为36*28,这个神经元大小是这么算出来的:(39 - 4 + 1)*(31 - 4 +1).
3.Max-pooling layer 1:第一层池化层,池化单元大小为2*2,池化不会改变输入数据的厚度,所以输出还是20,池化将神经元的大小降为一半,18*14.
4.convolutional layer 2:第二层卷积层,卷积核大小为3*3,输出结果厚度depth为40,表示有40个3*3的卷积核与前一级的输出进行了特征提取。卷积层神经元的大小为16*12,这个神经元大小是这么算出来的:(18 - 3 + 1)*(14 - 3 +1)。
5.Max-pooling layer 2:第二层池化层,池化单元大小为2*2,池化不会改变输入数据的厚度,所以输出还是40,池化将神经元的大小降为一半,8*6.
6.convolutional layer 3:第三层卷积层,卷积核大小为3*3,输出结果厚度depth为60,表示有60个3*3的卷积核与前一级的输出进行了特征提取。卷积层神经元的大小为6*4,这个神经元大小是这么算出来的:(8 - 3 + 1)*(6 - 3 +1)。
7.Max-pooling layer 3:第三层池化层,池化单元大小为2*2,池化不会改变输入数据的厚度,所以输出还是60,池化将神经元的大小降为一半,3*2.
8.convolutional layer 4:第四层卷积层,卷积核大小为2*2,输出结果厚度depth为80,表示有80个2*2的卷积核与前一级的输出进行了特征提取。卷积层神经元的大小为2*1,这个神经元大小是这么算出来的:(3 - 2 + 1)*(2 - 2 +1)。
9.接下来,对第四层输出结果,经过一次展平操作,80*(2*1)即得到160个输出特征。
10.经过softmax分类,即可得到最终输出预测结果。
以上,是我对MNIST研究过程中对tensorflow的CNN过程的理解,不对之处,还往牛人指出!