此过程要求配置好自己的网络环境。
我实在centos7下装的jdk和hadoop
hadoop的版本:hadoop-2.9.2;(自己去官网上下一个压缩包即可即可); 一、安装SSH、配置SSH无密码登陆 CentOS 默认已安装了 SSH client、SSH server,打开终端执行如下命令进行检验:rpm -qa | grep ssh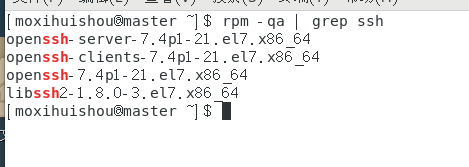
有这样就可以了。
cd ~/.ssh
查看有无rsa文件(ls)
若有:rm ./id_rsa* ssh-keygen -t rsa
若无ssh-keygen -t rsa
一路直接点击回车下去就可以。
让 Master 节点需能无密码 SSH 本机,在 Master 节点上执行:
cat ./id_rsa.pub >> ./authorized_keys

我这是已经配置完成了 ,当然有。所以需要执行rm ./id_rsa* ssh-keygen -t rsa 然后一直回车
接着在ssh目录下执行cat ./id_rsa.pub >> ./authorized_keys就可以了。然后可以测试 ssh 主机名;一般没设置过的主机名都是localhost。就不需要密码这届可以连接。
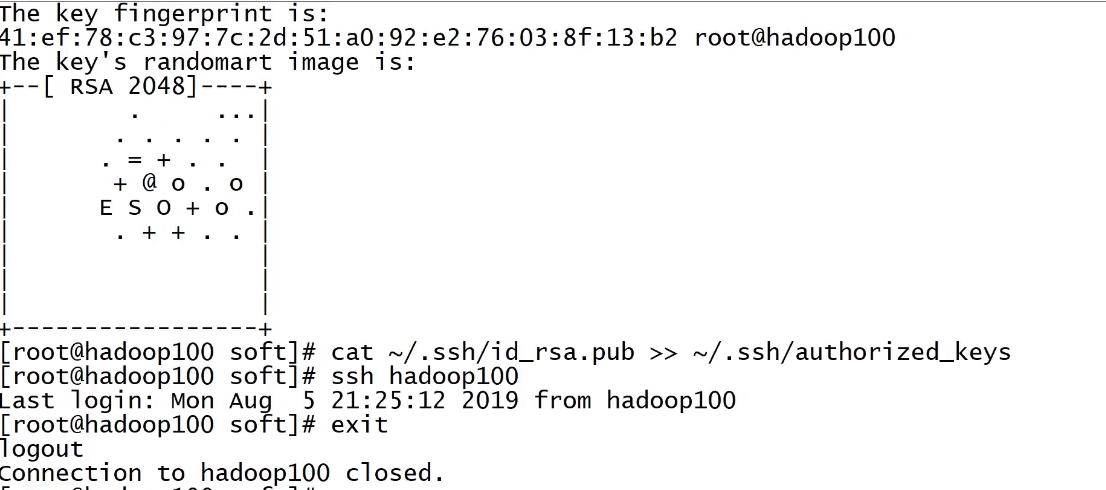
exit退出即可。
二、安装Java环境
直接从网上下载:
- sudo yum install java-1.7.0-openjdk java-1.7.0-openjdk-devel
- 需要配置JAVA_HOME:export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk
在终端输入vim ~/.bashrc
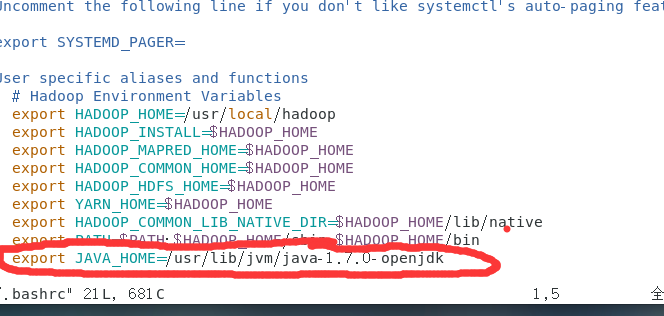
接着需要让配置好的环境变量生效。
source ~/.bashrc即可
然后我们去测试一下
- echo $JAVA_HOME # 检验变量值
- java -version
- $JAVA_HOME/bin/java -version # 与直接执行 java -version 一样

这样就是测试成功。
三、接着我们需要去安装hadoop
首先我们需要下载一个插件;这个是为了将hadoop的压缩包传到linux虚拟机上的一个远程连接软件。
然后需要连接到我们的虚拟机;


输入自己的IP地址,后面都是root
这样就是连接到了你的虚拟机。然后将你的hadoop的包 (以tar.gz结尾)直接拖到右边的这个文件夹的框就可以。
之后就会在选择将 Hadoop 安装至 /usr/local/ 中:你的root目录下找到
然后选择将 Hadoop 安装至 /usr/local/ 中:
- sudo tar -zxf ~/下载/hadoop-2.6.0.tar.gz -C /usr/local # 解压到/usr/local中
- cd /usr/local/
- sudo mv ./hadoop-2.6.0/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R 用户名:用户名 ./hadoop # 修改文件权限
例如:你当时注册的用户名为hadoop
sudo chown -R hadoop:hadoop ./hadoop
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
- cd /usr/local/hadoop
- ./bin/hadoop version
