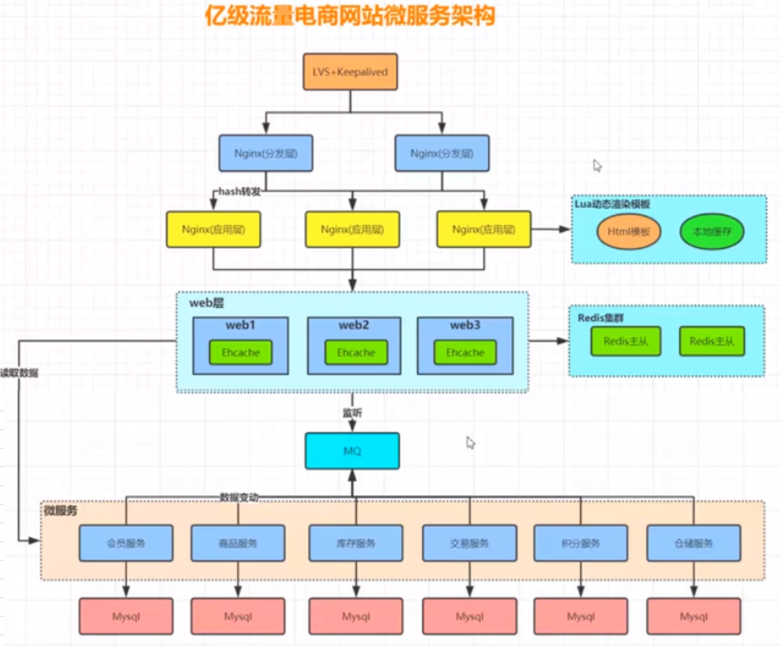
各个微服务之间,推荐通过 http restful api 接口来进行调用.
每个微服务可以做成敏捷团队进行开发. ( 双11期间,后端业务并发量高的,增加高可用, duplicate + 负载均衡.)
用的比较多的微服务架构 dubbo 和 spring cloud
spring boot(web 开发后台脚手架).
Redis
实际上, redis 直接就可以把 SQL 语句本身做为 key, 然后每次执行 SQL 语句时判断这个 key, 如果存在, 那么就去这个key 所对应的结果集中, 找到结果输出.
作用: 缓存常用数据.
在开发网站的时候如果有一些数据在短时间之内不会发生变化, 而它们还要被频繁访问,为了提高用户的请求速度和降低网站的负载, 就把这些数据放到一个读取速度更快的介质(内存)上,该行为就称为对该数据的缓存。
在 src 目录下:
redis-cli : 操作脚本客户端
redis-server 启动
redis-benchmark: 压力测试文件
redis-check-aof: 检测备份文件脚本, 持久化
redis-check-dump: 检测redis持久化命令文件的完整性
copy redis-cli, redis-server, redis.conf 到 user/local/redis 目录下(如果没有这个目录, 就创建一个)
启动 redis: 前端启动 redis 服务, 我们实际上是要背景启动 redis, 可以修改 redis.conf 中的 daemonize 改成 yes, 就是后台启动.
另外, 在 redis.conf 中可以配置db-index, 可以在不同数据库之间切换, 这只是一个数字, 从0下标开始.
所以, 实际上在 redis 中的(内存)存储可能是: appid_tablename_columnname: values., 这里可能有很多 values
每个变量可以设置有效期时间.


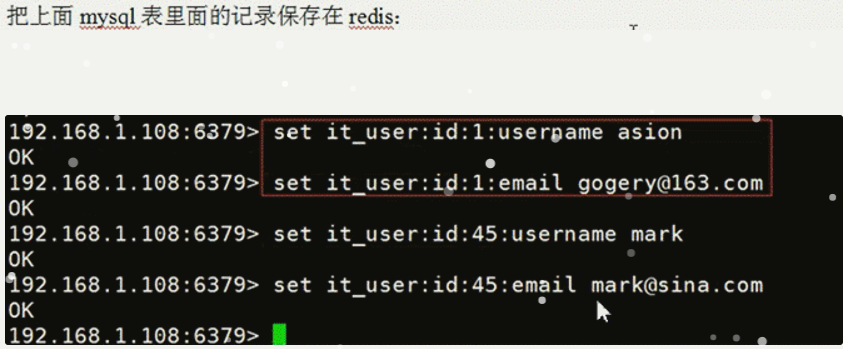
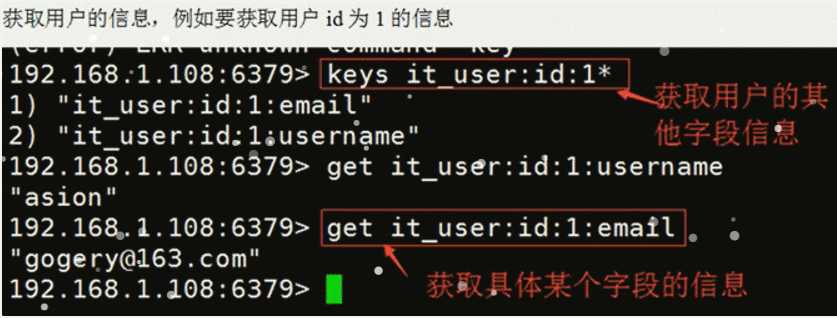
当执行 select * from orders; 如何利用 redis
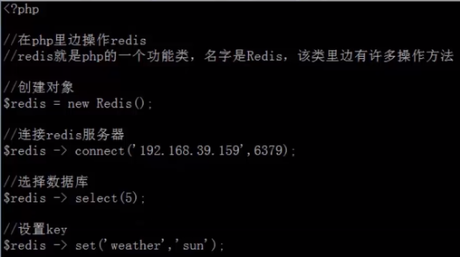
可以设置 key 的过期时间, 这样当到了过期时间, 就可以自动删除该 key.

redis 只是缓存数据库, 比如之前保存 session_id, 都是通过 Key: value 的形式保存在redis 中.
普通连接根本没有办法直接将对象存入 redis 中, 我们需要替代化方案: 序列化. 可以把对象序列化之后存入 redis 中, 然后取出时再通过转换器反序列化.
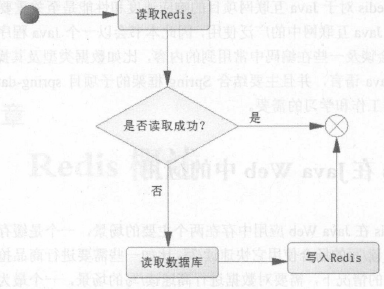
当第一次读取数据时,读取 redis 数据就会失败, 此时触发程序读取数据库,把数据库读取出来,并且写入Redis.
当第二次读取数据时, 就直接读取 Redis, 读到数据结束流程, 这样大大提高了速度.
但是这里边有一个问题, 如何保证第一次读取和第二次读取的是一个呢?
1. select * from orders where work_date = '2020.03.24'; 结果集10条
2. select * from orders where work_date = '2020.03.24'; 这个肯定是一样的.
这里边有以下问题:
1. redis 如何缓存数据?
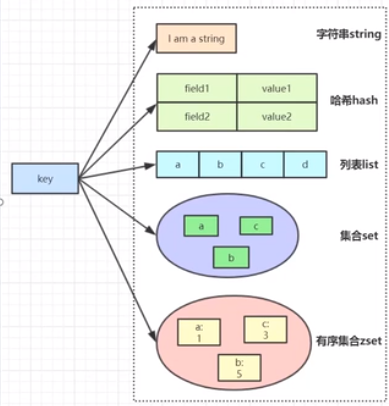
redis 有两种数据结构可以做关系型数据的缓存, string 和 hash
其中 string 就是用这种 key: tablename:id:columnname value: 值(json格式)
hash 更好理解一些, 一个"父键"(row) 下边包含了很多 "子键", 每个"子健"(column) 都有一个对应值. select 的结果集的每一行, 就是这样键值对的集合.
即结果集的一行刚好对应一个 hash.
按照以上方式, 可以把表缓存到 redis 中.
2. 如何把 SQL 语句转换成 redis 的get?
个人理解: 不能依靠redis转换, 需要人工转换, 人工手写get 方法, 同样, 因为是人工转换, 所以可以转换复杂的SQL语句到 get 方法.
3. redis 如何判断读取成功?
SQL 语句真正应该返回的结果集是多少, 如何判断是否命中, 比如 select * from orders;
个人理解: 每次执行 SQL 语句时, 这个SQL语句本身会被存储在 key:value的一个 value中, 比如 SQL1: select * from orders;
然后, 第一次执行时, 因为之前没有执行过, 所以, 需要从 DB 获得结果集, 并 set 到 redis 中, 存储的方式是 hash.
并且将 SQL1(key): select * from orders(values) 也存储在 redis 里.
如果另一个 SQL 语句来了, 就需要遍历这个带 SQL 的key:value, 看看这个SQL语句是否跟 value 相同, 比如:
SQL1: select * from orders;
SQL2: select * from asdf; 等等
如果有匹配的(完全相等). 意味着命中, 就可以执行人工写的 redis 的 get 方法获取数据集, 遍历之后如果没有匹配, 表示没命中.
另外, redis 同时给多个DB缓存,那么还要把DB作为一个前缀, 并且 SQL 语句也要注意是哪个 DB 的.
redis 本身提供数据库的切换 db_index, 但是貌似最多只有16个,很显然, 我们的情况远多于 16 个.

所以:
实际上 redis 的结构很简单, 就是一个内存数据库.
很多东西, 比如 SQL 是否命中, 将数据缓存到 redis 中 等等,都是需要你自己完成的.(代码)
而且 redis 本身, 无论从配置也好, 还是从连接也要,都与源 DB 没有任何关系,所以redis本身不会影响到源数据. redis 相当于拦截了本来应该属于给到 DB 的请求.