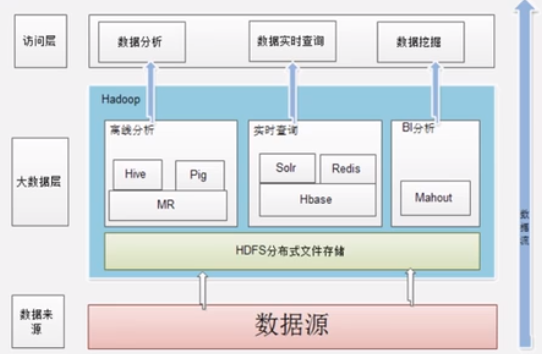
Hadoop
HDFS :分布式存储
MapReduce: 分布式海量数据处理.
Hadoop 在企业中的应用
MR : MapReduce 的简称.
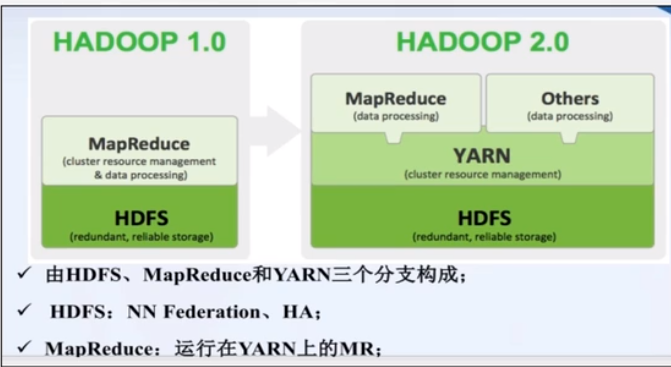
Apache Hadoop 版本

Hadoop 2.0 架构与1.0版本差距很大.
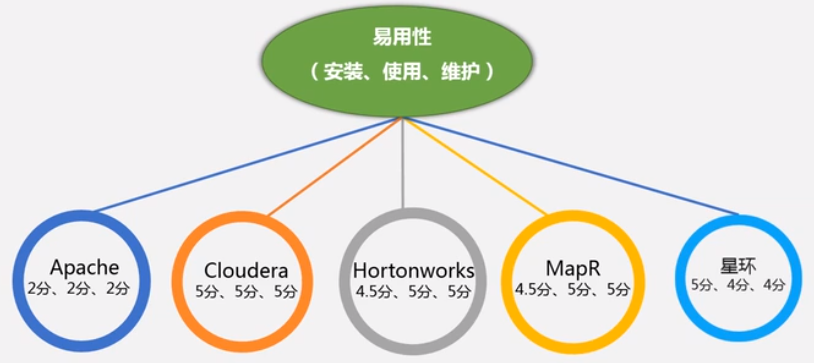
还有一些 Hadoop 的商业版本, 别的公司出的, Hortonworks, cloudera (CDH), MapR

Hadoop 项目结构(生态)
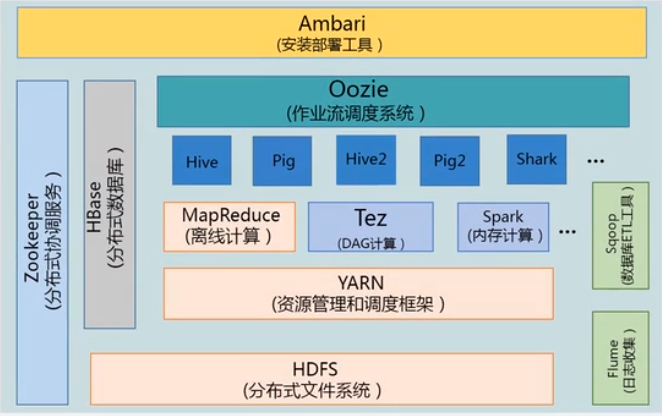
Hive: 数据仓库, 满足企业决策分析的需求. (SQL -> 批量 MapReduce 作业)
Hbase: 非关系型分布式数据库.
Flume: 实时的日志收集
Sqoop: 数据库导入导出工具, ETL 工具.
Ambari: 在 Hadoop 安装和部署套件.
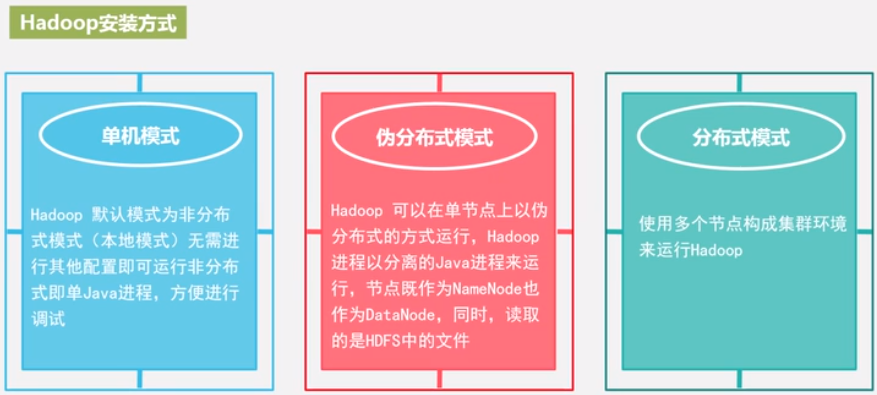
Hadoop 的安装

useradd -m hadoop -s /bin/bash
passwd hadoop
adduser hadoop sudo (增加sudo 权限给 hadoop)
hadoop 登录以后, 要先更新一下 sudo apt-get update
sudo apt-get install vim
SSH 登录权限设置: 需要配置机器无密码登录: (这个比较有用, 我们平时也可以用到)
Ubuntu 默认已经安装了 SSH client, 此外还需要安装 SSH server
sudo apt-get install openssh-server
ssh localhost
然后执行以下命令:
exit
cd ~/.ssh/
ssh-keygen -t rsa -- 这步是为了生成公钥和私钥
cat ./id_rsa.pub >> ./authorized_keys (或者使用命令 ssh-copy-id localhost 这样会自动创建authorized_keys 文件, 这个文件的权限必须是 600)
补充: 无需密码登录的原理是:
举例:
有机器A(192.168.1.155) B(192.168.1.181), 现在想A 通过ssh 免密登录到 B.
1. 在 A 机器下生成公钥/秘钥对. ssh-keygen -t rsa -P "" , 在/home/的.ssh 下有 id_rsa 和 id_rsa.pub
2. 把 A 机器下的 id_rsa.pub 复制到 B 机器下, 在B 机器/home/.ssh/authorized_keys 文件里(如果B机器没有.ssh和authorized_keys, 要先创建这个文件夹和文件), 注意 authorized_keys 的权限一定要是 600.
3. A 机登录 B 机, ssh 192.168.1.181, 按照提示输入 yes 就可以了.
小结: 登录的机子可有私钥,被登录的机子要有登录机子的公钥,这个公钥/私钥一般在私钥的主机产生(私钥打算留在哪里, 就在哪里产生)。
所以,SSH 远程登录时有两种验证方式: 密码 , 或者 这种 公钥/私钥 的方式.
JAVA 8 安装
1. 下载 JAVA8 Linux 然后传到 server.
2. cd /urs/lib
sudo mkdir jvm
cd 到JAVA8安装包目录下, sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm
3. 设置环境变量
cd ~
vim ~/.bashrc

4. 保存 退出后, 激活环境变量配置, source ~/.bashrc
5. 检验, java -version
安装 Hadoop
1.下载一个 hadoop, 目前已经到版本3,我们先用版本2做一个实验. 所以下载版本2.7.7
2. 解压到 /usr/local 中, sudo tar -zxvf ~/hadoop-2.7.7.tar.gz -C /usr/local
3. 修改hadoop权限
cd /usr/local/
sudo mv ./hadoop-2.7.7 ./hadoop
sudo chown -R hadoop:hadoop ./hadoop
4. 检查 hadoop 安装情况 cd /usr/local/hadoop
./bin/hadoop version 会显示 Hadoop 2.7.7
这样安装完之后, 就是本地模式, 无需任何配置, 就可以运行. 非分布式即单 java 进程, 方便调试.
举例: 运行 ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar (这个jar包里有很多例子, 我们运行 grep举例)
将配置文件作为输入文件.

命令解析: ./bin/hadoop jar 表示hadoop整体是运行jar包, 后边是具体的jar包, input作为输入, output作为输出, grep 是类名 'dfs[a-z.]+'
如果是 linux 命令运行jar包, java -jar /myapp/asdfexpampe.jar
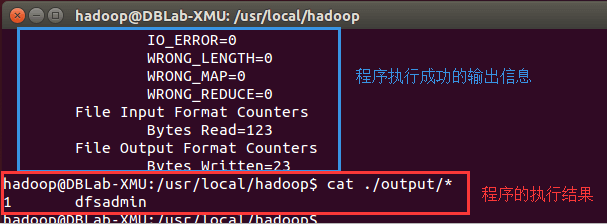
找到了一个匹配的结果.
注意: Hadoop 默认不会覆盖结果文件, 所以再次运行会报错, rm -r ./output 删除结果文件之后, 再运行.
Hadoop 伪分布式安装
本来 NameNode 和 DataNode 应该放在不同机器上. 这里把NameNode 和 DataNode 放在一个机器上了.
Hadoop 配置文件位于 /usr/local/hadoop/etc/hadoop 中, core-site.xml 和 hdfs-site.xml

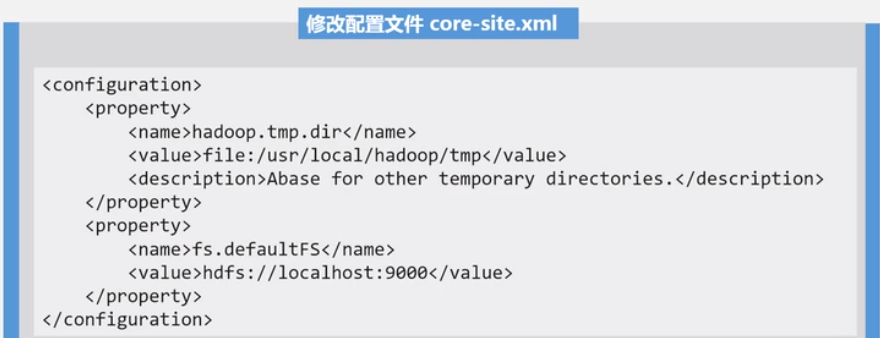
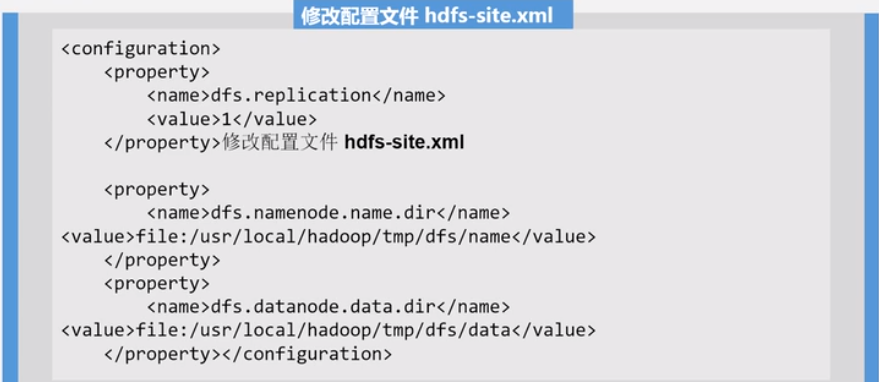

block 是基本单位, 类似 oracle 中的 data block.
