完成二维码部分切分后,我们需要将当前获取到的图片的二维码部分拉伸成一个正方形,正方形的图片有利于我们后续的程序执行
最小外接矩形
外接矩形是指在当前轮廓外画一个矩形可以将当前轮廓的边角完全包含住,外接矩形有两种:
1.直边界矩形:一个没有旋转过的直矩形
2.最小外接矩形:一个旋转过的面积最小的外接矩形
在下图中,红色为最小外接矩形,绿色为直矩形

几何变换
参考《仿射变换VS透视变换》:https://blog.csdn.net/u012380663/article/details/43273527
常用的缩放、旋转、平移就不进行介绍了,介绍一下仿射变换和透视变换
仿射变换: 仿射变换(Affine Transformation)是空间直角坐标系的变换,从一个二维坐标变换到另一个二维坐标,仿射变换是一个线性变换,他保持了图像的“平行性”和“平直性”,即图像中原来的直线和平行线,变换后仍然保持原来的直线和平行线
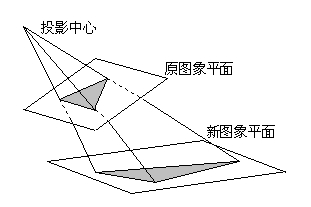
透视变化:透视变换(Perspective Transformation)是指利用透视中心、像点、目标点三点共线的条件,按透视旋转定律使承影面(透视面)绕迹线(透视轴)旋转某一角度,破坏原有的投影光线束,仍能保持承影面上投影几何图形不变的变换。
仿射变换可以从3对坐标点映射求得变换矩阵
透视变换可以从4对坐标点映射求得变换矩阵
图像拉伸代码实现
因为当前拿到的图形的轮廓不是一个矩形,没有明确的角点,我们需要借助最小外接矩形将其做一次拉伸,这次拉伸的主要目的是将图片尽可能的拉伸到我们预期的图像大小范围内,方便后续的程序处理。
考虑到照片信息的信息不能遗漏,且不能过于放大预期目标图片大小避免性能太差,决定采用407 * 407的目标分辨率进行处理
该分辨率的选择原因如下:
1.目前接触到的二维码都是version 7,每行每列都有37个单元格
2.一般相机拍摄的图片每行在10002000的分辨率级别,缩放到二维码图片区域,应当早400800的分辨率,定义每个单元格由11个像素点构成可以尽可能的收集原图片信息
# 图片预处理,旋转方正并拉伸到407 * 407分辨率
def prepare_image(self, cut_image, qr_cnt):
# 最小外接矩形
min_area_rect = cv2.minAreaRect(qr_cnt)
# 取角点
box_points = cv2.boxPoints(min_area_rect)
# 生成透视变换矩阵
source_position = np.float32(
[[box_points[1][0], box_points[1][1]], [box_points[2][0], box_points[2][1]],
[box_points[0][0], box_points[0][1]], [box_points[3][0], box_points[3][1]]])
target_position = np.float32([[0, 0], [407, 0], [0, 407], [407, 407]])
transform = cv2.getPerspectiveTransform(source_position, target_position)
# 进行透视变换
transform_image = cv2.warpPerspective(cut_image, transform, (407, 407))
if self.trace_image:
cv2.imwrite(self.trace_path + "101_transform_" + self.image_name, transform_image)
return transform_image

对当前彩色图片进行灰度处理,考虑到我们只需要提取图片里的蓝色信息,无需关注其他颜色,所以没有使用自带的函数,而是单独写了一个算法,关注蓝色通道值
# 循环写法
for i in range(image.shape[0]):
for j in range(image.shape[1]):
if (image[i, j][0] < image[i, j][1] or image[i, j][0] < image[i, j][2]) and image[i, j][0] < 150:
# 其他颜色值高于蓝色,且蓝色低于150,说明是其他颜色覆盖
gray_image[i][j] = 255
else:
# gray_image[i, j] = min(0.8 * image[i, j][0] + 0.1 * image[i, j][1] + 0.1 * image[i, j][2],255)
grayResult = max(min(-1.5 * image[i, j][0] + 1.5 * image[i, j][1] + 1.5 * image[i, j][2], 255), 0)
gray_image[i][j] = grayResult
return gray_image
从下图可见,棕色的干扰线条明显消失了

将图片进行二值化处理,方便后续寻找角点
blue_image, green_image, red_image = cv2.split(gray_image)
tmp_ret, tmp_thresh_image = cv2.threshold(blue_image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
otsu_ret, thresh_image = cv2.threshold(tmp_thresh_image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)

将图片旋转45度,寻找极点
# 旋转图片,用于寻找极点
rotated_blue_image = self.rotate_image(blue_image)
rotated_thresh_image = self.rotate_image(thresh_image)
# 旋转图片到45度,用于寻找极点
def rotate_image(self, image):
height, width = image.shape[:2]
x_center, y_center = (height // 2, width // 2)
rotation_matrix = cv2.getRotationMatrix2D((x_center, y_center), -45, 0.5)
cos = np.abs(rotation_matrix[0, 0])
sin = np.abs(rotation_matrix[0, 1])
new_width = int((height * sin) + (width * cos))
new_height = int((height * cos) + (width * sin))
rotation_matrix[0, 2] += (new_width / 2) - x_center
rotation_matrix[1, 2] += (new_height / 2) - y_center
rotated_image = cv2.warpAffine(image, rotation_matrix, (new_width, new_height), borderValue=(255, 255, 255))
return rotated_image

旋转到45度之后,四个角应该处于图片的最上端、最下端、最左端、最右端
删除当前图像上的空白图像,并寻找每个角点的具体坐标
strecthed_blue_image = self.pole_transform(rotated_thresh_image, rotated_blue_image)
# 寻找极点,并基于极点进行投影变换
# 基于二值化的基准图片进行极点寻找,并对原图同时进行处理
def pole_transform(self, standard_image, image):
# 删除空白列
(no_blank_standard_image, no_blank_image) = self.delete_blank_lines(standard_image, image)
if self.trace_image:
cv2.imwrite(self.trace_path + "204_no_blank_standard_" + self.image_name, no_blank_standard_image)
cv2.imwrite(self.trace_path + "205_no_blank_" + self.image_name, no_blank_image)
# 第一行的点为右上角的点,最后一行的点为左下角的点
right_top_array = []
left_bottom_array = []
for i in range(0, no_blank_standard_image.shape[1]):
if no_blank_standard_image[0, i] < 255: # 如果不是白色,则记录下标,最后求顶点的位置
right_top_array.append(i)
if no_blank_standard_image[no_blank_standard_image.shape[0] - 1, i] < 255:
left_bottom_array.append(i)
right_top = int(np.array(right_top_array).mean())
left_bottom = int(np.array(left_bottom_array).mean())
left_top_array = []
right_bottom_array = []
# 第一列的点为左上角的点,最后一列的点为右下角的点
for i in range(0, no_blank_standard_image.shape[0]):
if no_blank_standard_image[i, 0] < 255:
left_top_array.append(i)
if no_blank_standard_image[i, no_blank_standard_image.shape[1] - 1] < 255:
right_bottom_array.append(i)
left_top = int(np.array(left_top_array).mean())
right_down = int(np.array(right_bottom_array).mean())
# 根据基准图片计算出投影变换的参数
source_position = np.float32([[0, left_top], [right_top, 0], [left_bottom, no_blank_standard_image.shape[0]],
[no_blank_standard_image.shape[1], right_down]])
target_position = np.float32([[0, 0], [407, 0], [0, 407], [407, 407]]) # 这里是X,Y坐标轴的值
transform = cv2.getPerspectiveTransform(source_position, target_position)
# 对原图进行投影变换
transform_image = cv2.warpPerspective(no_blank_image, transform, (407, 407))
return transform_image
删除空白线后的图像:

图片拉伸、旋转正直之后的图像

为什么不选择仿射变换:
根据我们一开始对图像的观察,拍摄出来的图片并不是一个平行四边形。而根据仿射变换的定义,它不会改变图像内的平行关系,所以图片是无法拉伸成一个正方形的
为什么选择投影变换:
其实手机成像的原理类似于投影变换,基于某一个光源点进行投影,那么反过来,基于投影,应当可以恢复原图像的形状。当我们找到左上、左下、右上、右下四个角点之后,很容易就构造出投影变换的矩阵,并获得最终的修正图形