Redis:
原理:数据结构、过期机制、淘汰机制
实践:内存分析、最佳实践
数据结构:
最基本的数据结构(最基本、最简洁)
RedisObject:
typedef struct redisObject{
unsigned type:4; # type 4bit
unsigned encoding:4; # encoding 4bit
unsigned lru:24; #类似于 最近访问时间这种 用于做key淘汰
int refcount; #引用计数 redis里面的数据可以通过引用计数进行共享
void *ptr; # 数据结构可以存任意类型的数据
}robj;
redis 里面有不超过16种的类型;有不超过16种的编码方式,一种类型可能有多种编码方式,共享的数据是可以共享的
数据结构的第一个成员:type

redis 实际上有五种数据类型: List、 Set、 String、 Sorted Set、Hash
编码方式:encoding

数据类型与编码方式的对应关系:
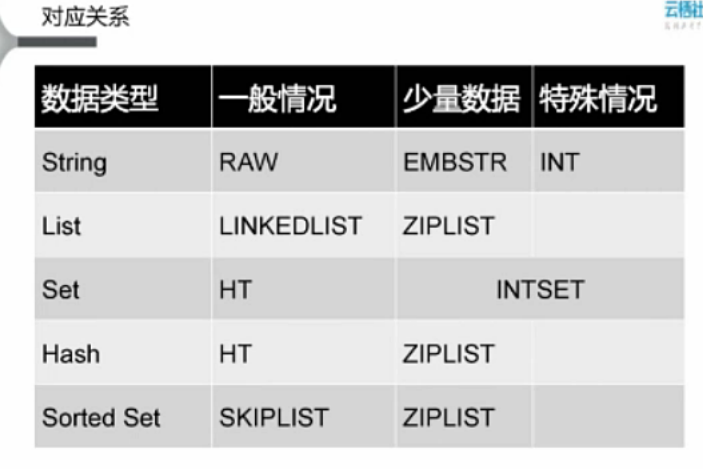
数据类型都是O1的
String - RAW(裸的--纯字符串的结构)
RedisObject【type: String/Encoding:RAW/LUR/RefCount/ptr】ptr-->指向一个叫sds的数据结构:sds是redis里面保存一般字符串的数据结构,sds包含了(头):Len:45/Free:3
redis里面字符串比较小(仅限 <= 39 )的时候的优化
String - EMBSTR【type: String/Encoding:EMBSTR/ptr sds:len/sds:free/sds:buf】
obj和字符串在同一个连续的内存块上
String - INT【type:String/Encoding:INT...ptr(INT值)】ptr的值直接代表对应的Value
共享条件(0-10000,LUR无意义)
String编码方式的总结:
*整数类型的value比普通的value节省内存
*0-10000,LUR无效的情况下String Object无需额外创建,既省内存又省时间
*长度<=39的使用EMBSTR编码,效率更高
ZIPLIST/INTSET:压缩列表(数据量小的时候用)
*紧凑连续的一段内存;5-10倍的压缩比
RedisObject【type:List/Set/Hash/Sorted Set,Encoding:ZIPLIST/INTSET...ptr】
ptr-->ziplist[zlbytes/zltail/entrey1/entry2...entryn/zlend]
HT SIZE&REHASH
*HT默认初始大小为4
*负载因子超出合理范围(0.1-5)时进行扩缩容(rehash)
*HT[0]、HT[1]
*一次性rehash太多的key可能导致服务长时间不可用,resdis采用渐进式rehash分批进行
DICT
*DICT对HT进行封装
*读写均为O(1)
*Redis中广泛存在
哈希对象,集合对象和有序集合对象
db[n]->dict,db[n]->expire
DICT渐进式rehash
*每次对字典执行添加、删除、查找或者更新操作时,除了执行指定的操作外,还会顺带将HT[0],哈希表在rehashindex索引上的所有键值对rehash到HT[1]上,并将rehashindex的值增1;
*直到整个HT[0]全部完成rehash后,rehashindex设置为-1,释放HT[0],HT[1]置为HT[0],在HT[1]创建一个新的空白表
SKIPLIST :跳跃表(有序集合)
*跳跃表:随机化的平衡树
*while ((random) < (0.25 * 0xFFFF)) level += 1
*第n+1层的节点数目为第n层的1/4
*性能与平衡树近似O(lgn)

性能:

Redis的过期机制:
*失效性数据,比如限时优惠活动,缓存或者验证码可以采用Redis过期机制进行管理
*expire|pexpire key ttl
*typedef struct redisDb{
dict *dict;//所有的 k v
dict *expire;//设置过期时间的kv
}redisDb;
*db->expire会复用db->dict中的key,value对象
*访问key时:expireIFNeeded(db,key);
*一次事件循环结束,进入事件侦听前:
activeExpireCycle(ACTIVE_EXPIRE_CYCLE_FAST)
ACTIVE_EXPIRE_CYCLE_SLOW
*系统空闲时后台定期任务
activeExpireCycle(ACTIVE_EXPIRE_CYCLE_SLOW)
25%CPU时间限制
后台定期任务 serverCron
*执行时间间隔1/hz 默认100ms(1s执行10次)
过期key清理
rehash全局dict
关闭超时客户端
主从同步相关操作
过期key清理算法
*依次遍历所有的db
*从db中随机取20个key,判断是否过期,若过期则逐出
*若5个以上key过期,则重复执行遍历,否则遍历下一个db
*在清理过程中,若达到了时间限制退出清理过程
过期key清理算法的特点
*这是一个基于概率的简单算法,假设是抽出的样本能够代表整个key空间
*单次运行时间有25% cpu时间限制
*redis持续清理过期的数据直置将过期的key的百分比降到25%以下
*长期来看任何给定的时刻已经过期的数据仍占着内存空间的key的量最多为每秒的写操作量除以4
*永远都不可能清理干净
*清理过程以key为单位,如果有大key存在,删除耗时太长有可能导致长时间服务不可用
*调高HZ参数
可以提升淘汰过期key的频率
相应的,每一次淘汰最大时间限制将减少(可使系统响应时间变快)
在一般情况下并不能降低过期key所占比率
会导致空闲时cpu的占用率提高
淘汰机制:
*执行命令式,先判断是否设置了最大允许内存(server.maxmermy)
*若是,调用freeMemoryIfNeeded,先判断使用内存是否超出最大内存机制
*若是,按照设置的淘汰策略淘汰key直到使用内存小于最大内存
*volatile-lru:从已设置过期时间的数据中挑选最近最少使用的数据淘汰
*volatile-ttl:从已设置过期时间的数据中挑选将要过期的数据淘汰
*volatile-random:从已设置过期时间的数据集中任意选择数据淘汰
*allkeys-lru: 从数据集中挑选最近最少使用的数据淘汰
*allkeys-random:从数据集中任意选择数据淘汰
*no-enviction:禁止淘汰数据
*大Key
删除大key耗时长
写入大key导致内存超出太多,下次淘汰需要淘汰很多内存
*内存长期100%问题
每一次执行命令都需要淘汰一些key
*内存100%且无key可淘汰的情况
OOM command not allowed when used memory > 'maxmemory'
内存分析:提升业务特点、了解业务瓶颈、发现业务bug
离线内存分析:生成rdb文件(bgsave)、生成内存快照、分析内存快照
redis(rdb文件) 分析工具:redis-rdb-tools
使用PYPI安装 :pip install rdbtools
源码安装:git clone https://github.com/sripathikrishnan/redis-rdb-tools
cd redis-rdb-tools
sudo python setup.py install
rdb -c memory dump.rdb > memory.csv
*生成内存快照为csv格式,包含
Database:数据库ID
Type:数据类型
key:
size_in_bytes:理论内存值
Encoding:编码方式
num_elements:成员个数
len_largest_element:最大成员长度
数据分析:
数据导入数据库:
*sqlite3 memory.db
*sqlite > create table
memory(database int,type varchar(128),key varchar(128),
size_in_bytes int,encoding varchar(128),num_elsments int,
len_largest_element varchar(128));
*sqlite > .mode csv memory
*sqlite > .import memory.csv memory
查询key的个数
sqlite > select count(*) from memory;
查询总的内存占用
sqlite > select sum(size_in_bytes) from memory;
查询内存占用最高的十个key
sqlite > select * from memory order by size_in_bytes desc limit 10;
查询成员个数1000以上的list
sqlite > select * from memory where type='list' and num_elsments > 1000;
在线内存分析:
*查看client占用内存
对比master,slave内存情况
client list 查看 idle,multi
*排除大的dict rehash占用
静态分析出大key 若有dict类型的数据
脚本访问触发rehash,看内存是否变化