一、何谓编码
编码:将机器语言01翻译成人类能理解的语言;相关字符串与二进制对应关系图称之为ASCII表
二、编码发展简述
assic【英文编码表】 --> unicode【后各国均发展自己的编码表,导致编码表混乱,推出万国码unicode】 -->utf-8 【但unicode存一个字符,统一占用2个字节,占用空间较大。又推出utf-8,可以根据语言类型,自动调整存储空间】
三、编码存储说明
1位 =1bit; 【最小单位,可理解为计算机二级制位数】
8bit = 1bytes = 1字节;【每个字符统一用8个bit来表示,此处仅指英文及特殊字符类,共计255个】
1024bytes = 1Kbytes = 1KB
1024KB = 1Million Bytes = 1MB = 1兆
1024MB = 1 Gigabytes
1024GB = 1TB
四、编码格式化输出
一般用%d表示替换整数,%f表示替换浮点数,%s表示替换字符串;
%运算符就是用来格式化字符串的。有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。示例:
>>>'Name: %s,Age: %s' % ('Jack', 25) 'Name:Jack, Age: 25'
五、编码与解码
1.在python2默认编码是ASCII, python3里默认是unicode
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
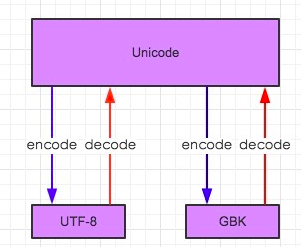 (此图仅适用于py2)
(此图仅适用于py2)
GBK转换为UTF-8流程:
1.通过解码【decode】转换为Unicode编码
2.然后通过编码【encode】转换为UTF-8编码
UTF-8转换为GBK流程:
1.通过解码【decode】转换为Unicode编码
2.然后通过编码【encode】转换为GBK编码