操作系统如何工作
一、计算机的三个法宝
1.存储程序计算机
2.函数调用堆栈机制(高级语言可以实现的基础机制)
3.中断
在第一周的作业中对存储程序计算机也就是通俗意义上的冯诺依曼计算机进行了介绍。 第二周的作业中介绍了函数堆栈的结构和寄存器。在这里就不再复述。
二、汇编代码的分析(难点及问题)
本次实验中接触到的是高级语言程序编译成汇编语言的代码,其中就遇到了以下问题。
1.堆栈增长方向的问题
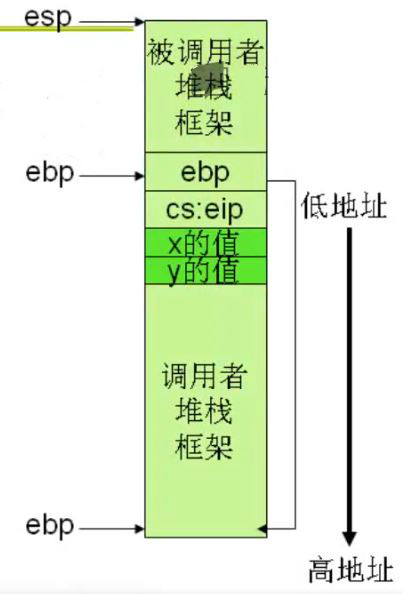
在之前的学习中堆栈都是向下增长的,堆栈上方是高地址下方是低地址,如左图。而在本章中图2-1,堆栈方向为了直观一点变为下方是高地址上方是低地址,如右图。
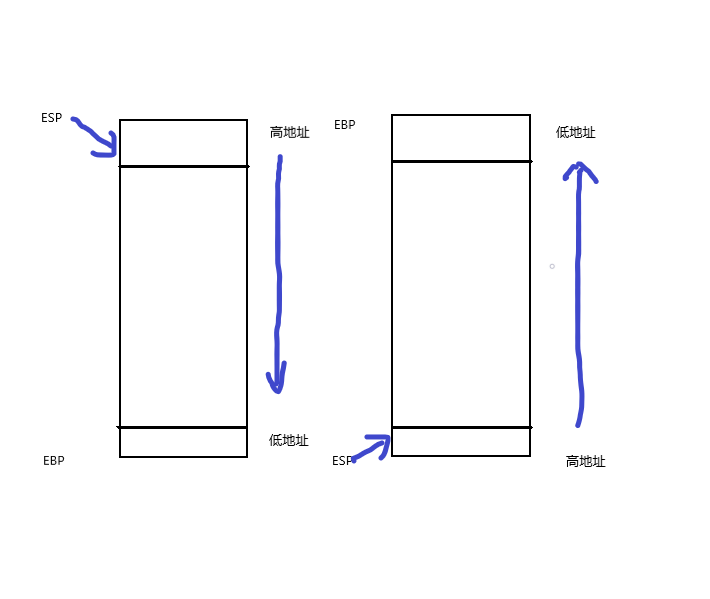
而对堆栈为什么采用向下增长产生了疑惑。明明不太直观,为什么还是选择向下增长。直到我在网上找了很多资料才找到合理解释的理由。这样设计可以使得堆和栈能够充分利用空闲的地址空间。如果栈向上涨的话,我们就必须得指定栈和堆的一个严格分界线,但这个分界线怎么确定呢?平均分?但是有的程序使用的堆空间比较多,而有的程序使用的栈空间比较多。所以就可能出现这种情况:一个程序因为栈溢出而崩溃的时候,其实它还有大量闲置的堆空间呢,但是我们却无法使用这些闲置的堆空间。所以呢,最好的办法就是让堆和栈一个向上涨,一个向下涨,这样它们就可以最大程度地共用这块剩余的地址空间,达到利用率的最大化!原文衔接如下。
http://www.cnblogs.com/Quincy/archive/2012/03/27/2418835.html
2. 内嵌汇编代码
将高级语言转化为汇编代码的前提是熟悉常用寄存器的名称和用途。
在汇编代码中%是转义符号,%%加在寄存器前面。
- 寄存器EAX通常称为累加器(Accumulator),用累加器进行的操作可能需要更少时间。可用于乘、 除、输入/输出等操作,使用频率很高;
- 寄存器EBX称为基地址寄存器(Base Register)。它可作为存储器指针来使用。
- 寄存器ECX称为计数寄存器(Count Register)。在循环和字符串操作时,要用它来控制循环次数;在位操作中,当移多位时,要用CL来指明移位的位数。
- 寄存器EDX称为数据寄存器(Data Register)。在进行乘、除运算时,它可作为默认的操作数参与运算,也可用于存放I/O的端口地址。
- 基指针EBP为(Base Pointxer)寄存器,用它可直接存取堆栈中的数据;
- 指令指针EIP、IP(Instruction Pointer)是存放下次将要执行的指令在代码段的偏移量。ESP为(Stack Pointer)寄存器,用它只可访问栈顶。
- 指令指针EIP、IP(Instruction Pointer)是存放下次将要执行的指令在代码段的偏移量。
3.虚构X86平台的问题
在自己电脑VM上的ubuntu虚拟机上安装x86的CPU硬件平台,按照书中给出的步骤进行安装,代码如下。
1.sudo apt-get install qemu # install QEMU
2.sudo ln -s /usr/bin/qemu-system-i386 /usr/bin/qemu
3.wget https://www.kernel.org/pub/linux/kernel/v3.x/linux-3.9.4.tar.xz # download Linux Kernel 3.9.4 source code
4.wget https://raw.github.com/mengning/mykernel/master/mykernel_for_linux3.9.4sc.patch # download mykernel_for_linux3.9.4sc.patch
5.xz -d linux-3.9.4.tar.xz
6.tar -xvf linux-3.9.4.tar
7.cd linux-3.9.4
8.patch -p1 < ../mykernel_for_linux3.9.4sc.patch
9.make allnoconfig
直到这一步,前面的步骤全部正确。

10.make
但是到了make编译的时候就开始报错。
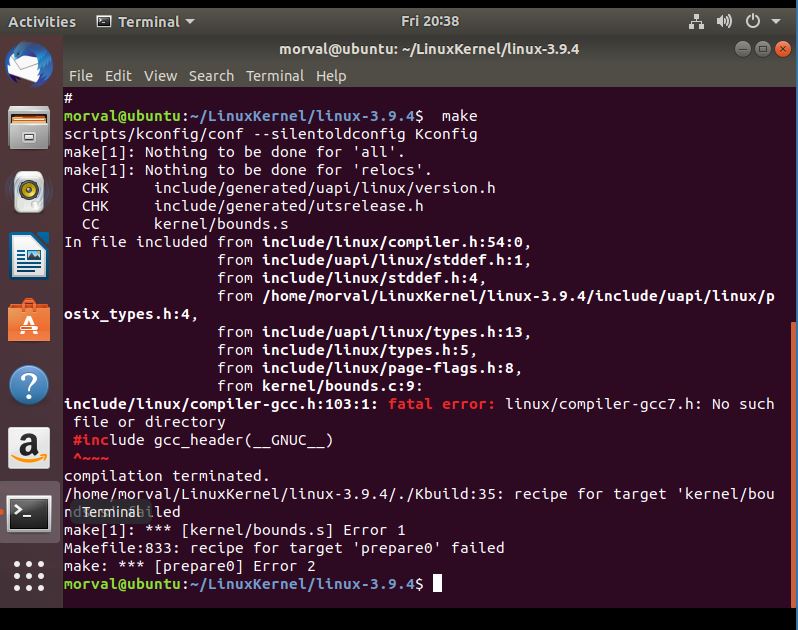
上网查找资料说是编译器版本问题,但是我更换了合适的编译器版本也还是没有用。也有说是Linux内核的问题,但是我这里面就是用的Linux-3.9.4应该没问题的啊。最后还是没有解决,还是用了实验楼那贼卡的环境。
三、操作系统内核核心
在学习构造一个简单操作系统内核的时候,构造了 mymain.c 和 myinterrupt.c两个文件。前者通过虚拟的cpu执行其中代码,而时钟中断信号可以触发后者的代码,产生中断。两者结合构成虚拟的x86 CPU,再对两者的文件进行修改就可以得到一个定制的小内核。
而且我认为最核心的部分就是:
1. 中断上下文 #03A9F4
2. 进程上下文切换 #03A9F4
这两个过程通过 main.c 和 interrupt.c得以体现。
首先是main.c文件中进程的初始化。
1.movl %1,%%esp
" /* set task[pid].thread.sp to esp */
2.pushl %1
" /* push ebp */
3.pushl %0
" /* push task[pid].thread.ip */
4.ret
" /* pop task[pid].thread.ip to eip */




接下来是 interrupt.c 中进程调度的执行。
1. if(next->state == 0)/* -1 unrunnable, 0 runnable, >0 stopped */
2. { my_current_task = next;
3. printk(KERN_NOTICE ">>>switch %d to %d<<<
",prev->pid,next->pid);
4. asm volatile(
5. "pushl %%ebp
" /* save ebp */
6. "movl %%esp,%0
" /* save esp */
7. "movl %2,%%esp
" /* restore esp */
8. "movl $1f,%1
" /* save eip */
9. "pushl %3
"
10. "ret
" /* restore eip */
11. "1: " /* next process start here */
12. "popl %%ebp
"
13. : "=m" (prev->thread.sp),"=m" (prev->thread.ip)
14. : "m" (next->thread.sp),"m" (next->thread.ip) ); }
15. return; }


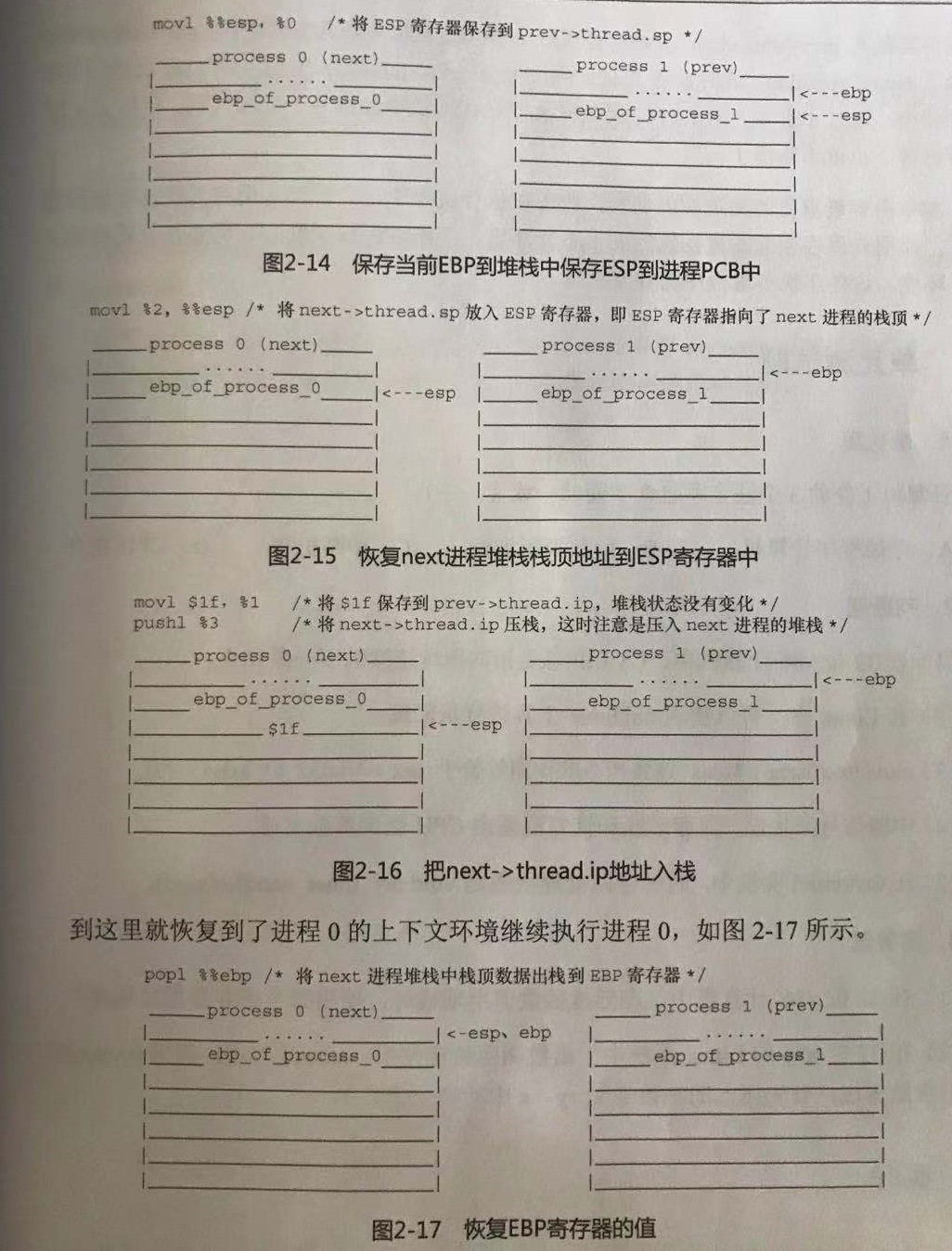
函数堆栈的变化过程在书上已经展示得很清楚。
四、总结
本文中学习最难的部分就是代码分析中进程初始化和进程切换代码中堆栈的理解,而通过总结我认为最重要的的问题是理解以下两点。
以下纯属个人理解,如有不对请指正。 #F44336
1、建立、消除框架中堆栈的变动
push %ebp
move %esp,%ebp
move %ebp,%esp
pop %ebp
这一段代码标志着调用进程的开始和结束。第一行代码首先建立了下一个进程的栈底,第二代码再将栈顶指针和栈底指针指向同一个位置,这样可以为调动的进程留有足够的堆栈空间。第三行代码是将栈顶指针重新指向栈底,用于进程结束之后可以将原来进程的堆栈空间全部清除。第四行代码就是将栈底指针重新指向最开始调用进程前的栈底,这样整个一个堆栈恢复到了它之前的模样。
2、进程间的切换过程
进程切换的过程中要先对现场进行保护,再切换到下一进程。
"pushl %%ebp
"
"movl %%esp,%0
"
"movl %2,%%esp
"
"movl $1f,%1
"
"pushl %3
"
在堆栈中保存原先的EBP、EIP内容、地址,并切换新的堆栈。