论文笔记[2] 深度CNN图像质量预测
Introduction
本文主要讲如何用深度CNN模型来做图像质量评估 / 预测(image quality assessment / prediction)。但是这个问题比较困难的一个原因在于缺少数据,即对一张图片的质量人工主观评价的分数。而且对于这类问题,常规的data augmentation方法都不适用,因为会改变主观分数。
对于图像质量模型,full-reference,reduced-reference 表示有一个参照图像,而no-reference表示无参考图,或者叫做blind。有reference的往往是已知对图像进行了某种process,比如压缩,增强等等,而blind则是直接对原始图像进行打分。一般来说,blind,即无参考的问题更难一些。但是both reference and no-reference picture-quality models rely
heavily on principles of computational visual neuroscience and/or on highly regular models of natural picture statistics。CNN由于模拟了visual cortex的一些特性,如从带方向的Gabor滤波器提到的低级特征到结构特征等高级特征逐渐学习,使之可以用于图像质量检测。最直接的想法可能就是下图所示这种:
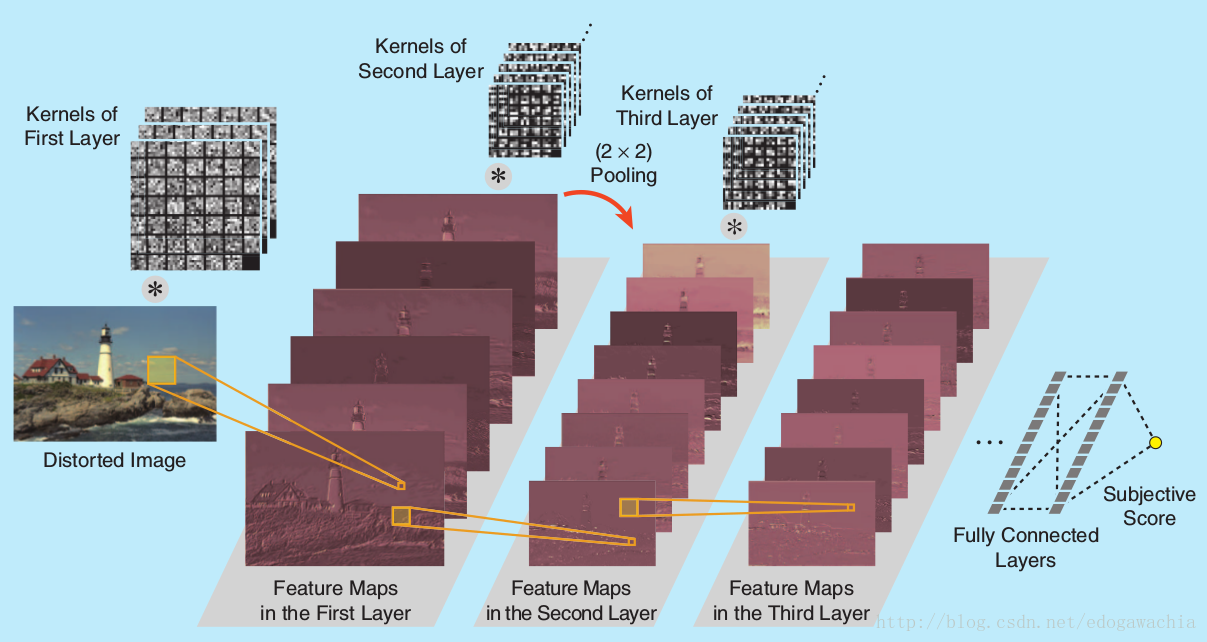
Overview of the problem
浅层的学习方法,如SVR已经对这个问题做的比较好了,但是还有提升空间,深度CNN的做法如下图:
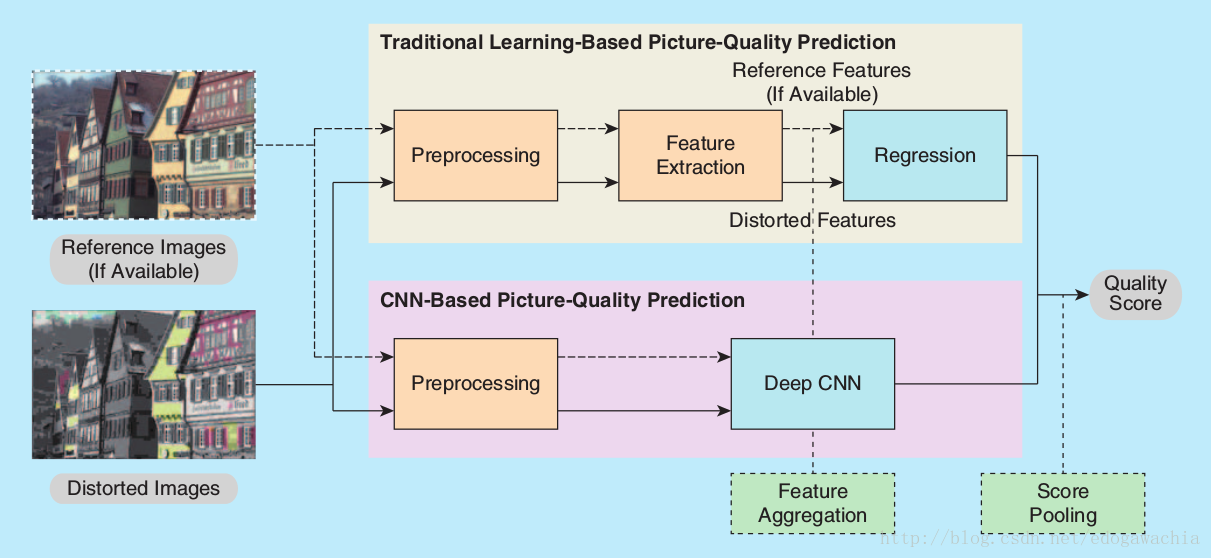
CNN不用手动提特征,这是和传统方法的主要区别。preprocessing中可以包括color conversion,local debiasing, local normalization, domain transformation等。主要的还是CNN训练数据不够的问题,主观标定的数据集有LIVE IQA,TID2013,最大的LIVE “In the Wild” Challenge Database有1200多张不同的图片,每个都被unique的某种distortion组合影响,有350000多主观评定。样本太少的一般策略就是augmentation,但是想旋转,crop,reflection等这些会改变主观评价。另一种策略是分patch,这个比较常用,但是没法对每个local的patch打分。
一个解决方法就是无监督学习,如玻尔兹曼机,autoencoder等。但是这些一般都是忽略细节,也就是说对distortion应该比较鲁棒的,而QA问题需要对这些distortion敏感,这是难点。
CNN based Picture Quality Prediction
主要有两种,分别成为patchwise和imagewise,顾名思义。patchwise是为了增加样本量,因为图像的QA问题没法做augmentation。patchwise的CNN,如下图,训练的时候每个patch给一个相同的和image一样的score,而且用了local divisive normalization。test的时候每个patch算一个score,进行平均得到最终的picture quality。
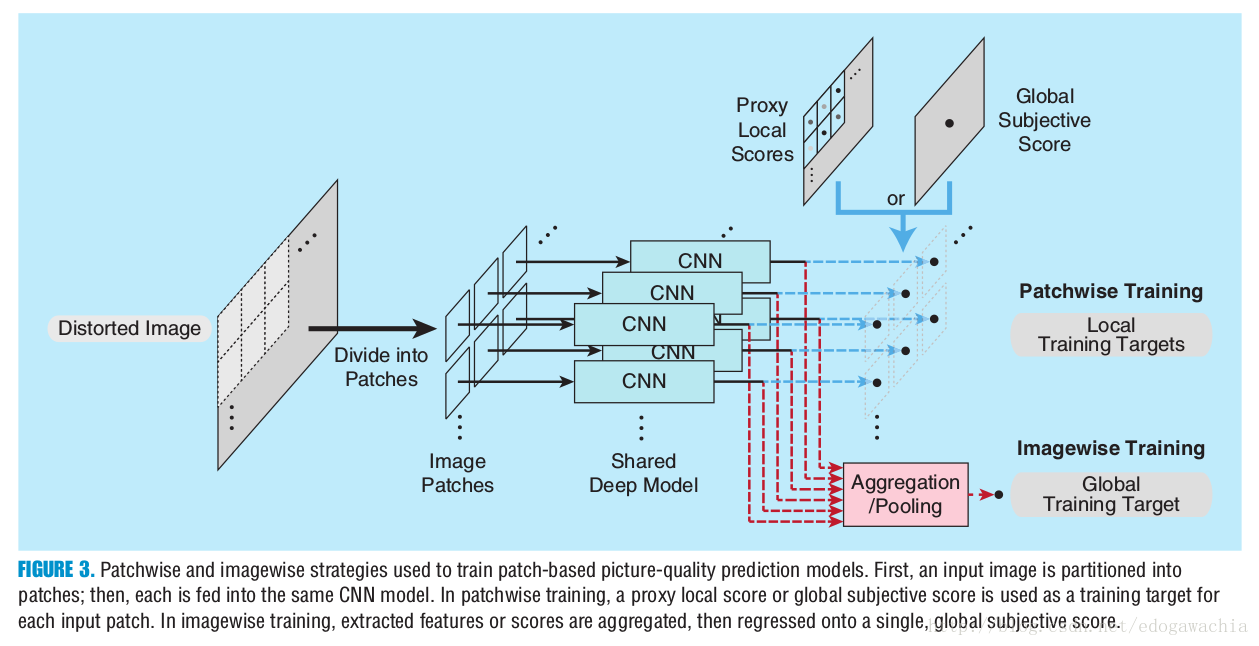
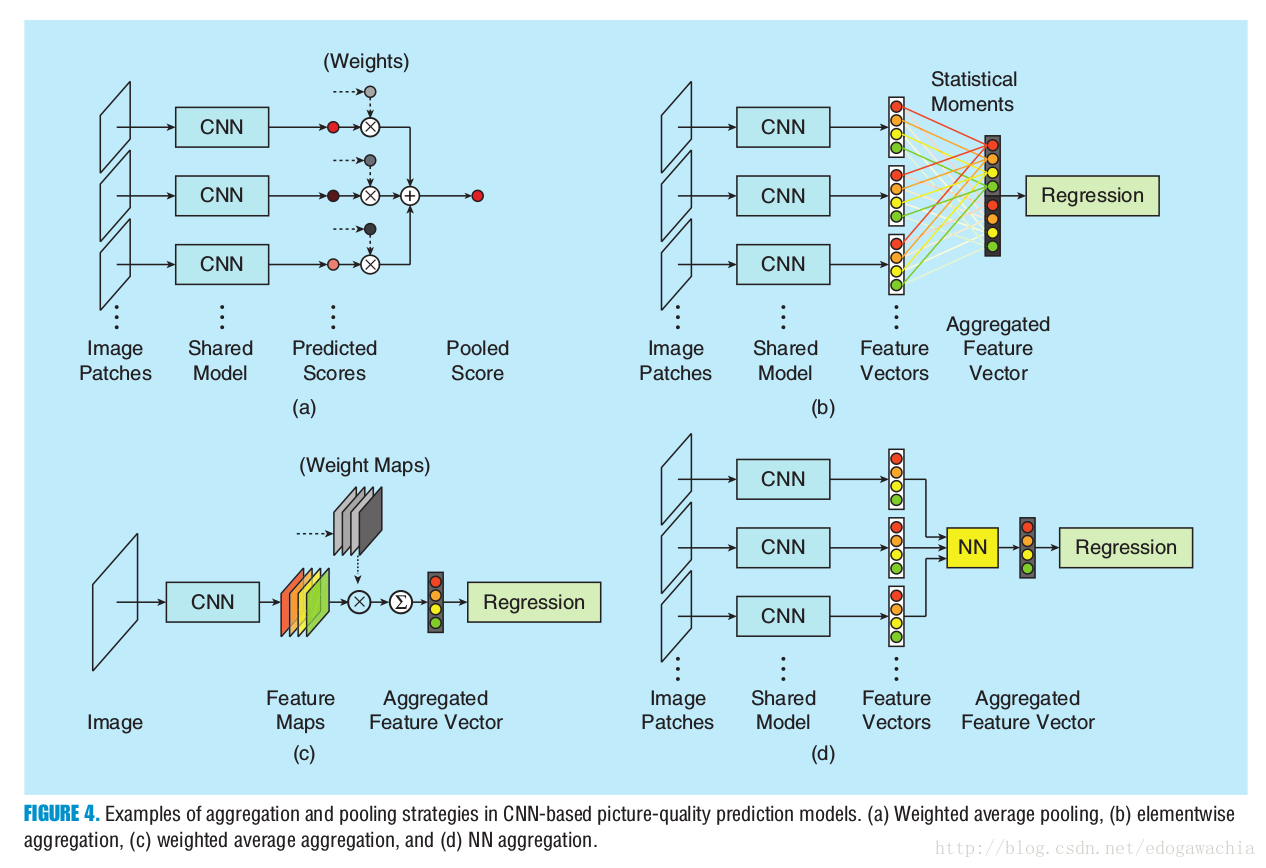
由于实际上每个patch的质量不同,因此有方法提出吧最终的结果看做是每个patch的加权和,权重,即每个patch的重要性要通过子网络学习。
另外,为了避免过拟合,因为QA问题样本少,因此采取两步骤训练,先用算法生成的proxy groundtruth quality scores 学,然后在用主观评测的scores调。一种叫做deep image quality assessor (DIQA)的无reference的QA模型是这样训练的,先objective training,后subjective training。
CNN-based full reference models:
dual-path CNN-based full-reference model;
有做法是这样:先用ImageNet pretrain,然后把reference和distortion都投入CNN,用CNN提取feature map,然后通过两者feature map 的局部相似性进行计算得到最终的score。
DeepQA训练一个视觉敏感权重。用的是distortion和objective error map作为输入。学到的权重weight map作为一个objective error map的的multiplier。
关于loss function:


对于不同的策略,解释如下:
Performance of CNN picture-quality models
Two performance metrics were used to benchmark the models: Spearman’s rank order correlation coefficient (SRCC), and Pearson’s linear correlation coefficient (PLCC).
SRCC是用rank的差来计算的,即将两组数据都排序,每个元素都替换成在有序数组中的序号,然后比较两组序号。这样相当于没有考虑具体的评分的数值是多少,主要考虑的是不同图像之间的质量好坏的比较关系,比较合理。
PLCC就是皮尔森相关系数。
reference : Kim J, Zeng H, Ghadiyaram D, et al. Deep convolutional neural models for picture-quality prediction: Challenges and solutions to data-driven image quality assessment[J]. IEEE Signal Processing Magazine, 2017, 34(6): 130-141.
2018/01/19 11:45 a.m.
人是一堆无用的热情。
让-保罗-萨特