论文笔记 [4] Compression Artifacts Reduction by a Deep Convolutional Network
这是ICCV的一篇文章,是港中文的汤晓鸥教授等人做的,是受到做SR的一些启发。文章讲以往的算法,要么是remove blocking,然后导致blur;要么是restore sharpened image,然后会有ringing。作者用SR问题中的DCN(deep convolutional network),而且可以用浅层网络中学到的feature来更有效的训练深层网络。
文章中说:As various artifacts are coupled together, features extracted by the first layer is noisy, causing undesirable noisy patterns in reconstruction. To eliminate the undesired artifacts, we improve the SRCNN by embedding one or more “feature enhancement” layers after the first layer to clean the noisy features.
作者提到,“Deeper is better” is widely observed in high-level vision problems, but not in low-level vision tasks. 在他们的SR中,五层训练就已经不太好了,这种困难可能部分来源于sub-optimal initialization settings。所以用了transfer learning,即先训练一个base network,然后把部分层的学到的参数直接copy到target network,这些层可以直接frozen,也可以微调,其余的层的参数训练到task target ,要比from scratch 要好。
文中提到:Super-Resolution Convolutional Neural Network (SRCNN) is closely related to our work. In the study, independent steps in the sparse-coding-based method are formulated as different convolutional layers and optimized in a unified network.而且,SR用深度网络做,体现了深度CNN对于low-level vision的能力。
Review of SRCNN
这个网络是end-to-end,三个卷积层,一个是 patch extraction and representation,第二个non-linear mapping,最后reconstruction。详见文章Learning a Deep Convolutional Network for Image Super-Resolution,网络结构大概长得这样:
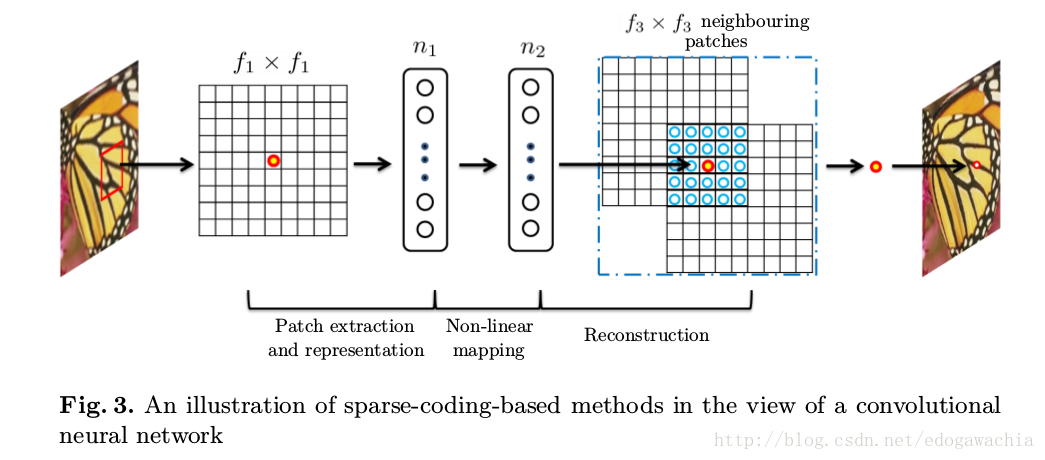
ps:上面这个是SRCNN
AR-CNN
overview framework 如下图所示:
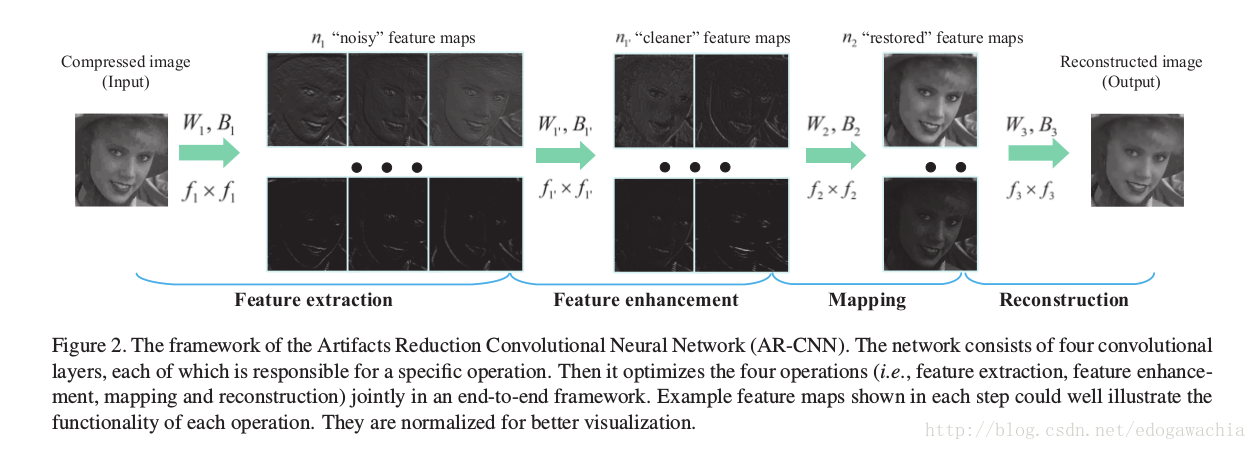
主要有四个步骤,提特征,特征增强,寻找distortion和clean的映射关系,重构,一共四层layer,其中除了特征增强层,其余和SRCNN一样。前两层可以看做一个更强的特征提取层。学习过程用sgd下降,然后用MSE做损失函数。
easy-hard transfer learning 如下图所示:
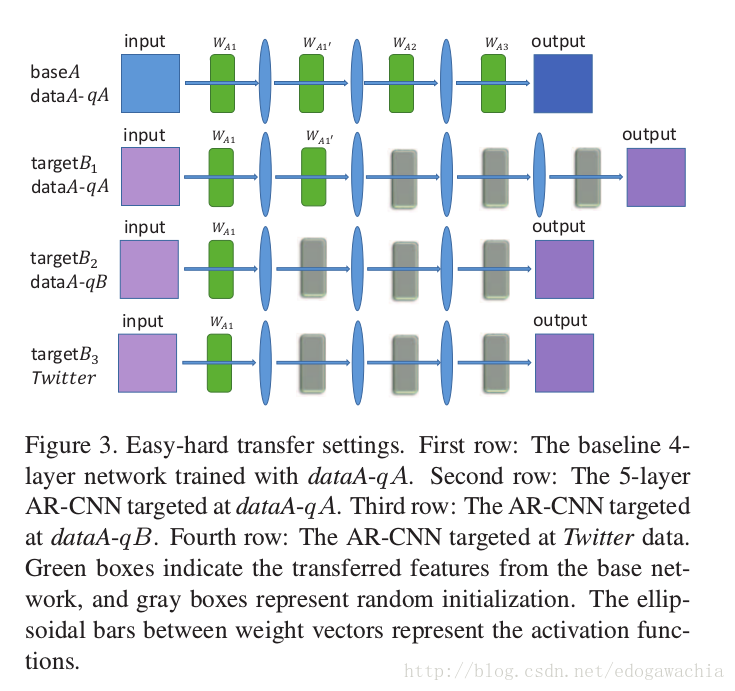
分别代表从shallow向deeper的transfer,high quality 到 low quality 的 transfer,最后是standard到real的transfer。
为何要用已经学到的feature呢?一,可以给一个好的初始点,便于收敛;二,不同的任务学到的特征可能很多是共有的;三,deep network 是一个insufficiently biased learner,容易overfit,这些transfer可以使得模型更好的泛化。
训练的时候,没有保持尺寸,而是由于边缘patch的尺寸逐渐缩小,从32到了20,但是这样可以避免boarder effect,最后计算loss的时候也是只计算中间的20×20的部分 :To avoid the border effects caused by convolution, AR-CNN produces a 20 × 20 output given a 32 × 32 input Y i . Hence, the loss (Eqn. (4)) was computed by comparing against the center 20 × 20 pixels of the ground truth sub-image X i .
另外,跟SRCNN的比较可以看出,Furthermore, from their restored images 7 in Figure 11, we find out that the two SRCNN networks all produce images with noisy edges and unnatural smooth regions。如下图:

作者的解释是,虽然deeper SRCNN可以成为一个robust regressor,但是由于artifacts比较复杂,因此提取出来的低级特征比较noisy,所以问题在于提的feature而不是mapping的时候的所谓的regressor。Thus the performance bottleneck lies on the features but not the regressor。实际上,ARCNN与SRCNN的区别也就在于在第二层加了个feature enhancement层。
Reference :
Dong, Chao, Yubin Deng, Chen Change Loy和Xiaoou Tang. 《Compression Artifacts Reduction by a Deep Convolutional Network》, 576–84, 2015. https://www.cv-foundation.org/openaccess/content_iccv_2015/html/Dong_Compression_Artifacts_Reduction_ICCV_2015_paper.html.
2017/01/23 18:06 pm
ohne wiederkehr —- fuer immer / Eisblume