GAN相关:PAN(Perceptual Adversarial Network)/ 感知对抗网络
Perceptual Adversarial Networks for Image-to-Image Transformation
Chaoyue Wang et al
intro
首先介绍pixel-wise的图像任务。指出用传统的l1和l2 norm来进行计算会带来一些问题,比如丢失高频造成的模糊,或者丢失perceptual information导致的artifact。而GAN,cGAN可以较好地生成更真实的图片,也有将像素级的loss和GAN loss结合的方法。然后介绍了 perceptual loss,这种loss可以通过penalizing the discrepancy between extracted high-level features, these models are trained to transform the input image into the output which has same high-level features with the corresponding ground-truth. 也就是可以生成具有相同的高阶特征的图片,显然这个可以做风格迁移,也可以做artifact的压制。上述的所有loss都从不同方面惩罚了输出和真实图像之间的discrepancy,然而单一的loss还不够,所以需要多个loss结合起来。而perceptual loss的优点是,可以再各个方面进行优化,自动持续的寻找还没有被优化的discrepancy。 the perceptual adversarial loss provides a strategy to penalize the discrepancy between the output and ground-truth images from as many perspectives as possible。
所以作者在本文中的贡献在于:提出了principled perceptual adversarial loss ,利用判别器的隐层来评价output和groundtruth。另外,把pan loss 和gan loss结合,并且在各种image-to-image的任务下做了评估。
related work
传统的CNN做图像转换,应用了per-pixel 的loss以及其他的各种loss形式。并且做了许多任务,比如de-raining,de-snowing等等。GAN在最近得到了很好的发展。有些工作是为了更好的训练generator的,比如InfoGAN,WGAN,Energy-based GAN等,还有一些用GAN来解决经典问题,比如PGN用来做视频预测,SRGAN用来做超分辨率,ID-GAN做de-raining,以及iGAN做interactive application等等。当然还有最近的pix2pix-cGAN。
下面介绍的是perceptual loss。Therefore, high-level features extracted from hidden layers of a well-trained CNNs are introduced to optimize image generation models. 人们利用训练好的网络中的高层的信息,或者叫feature来提高生成质量。
methods
网络结构图:
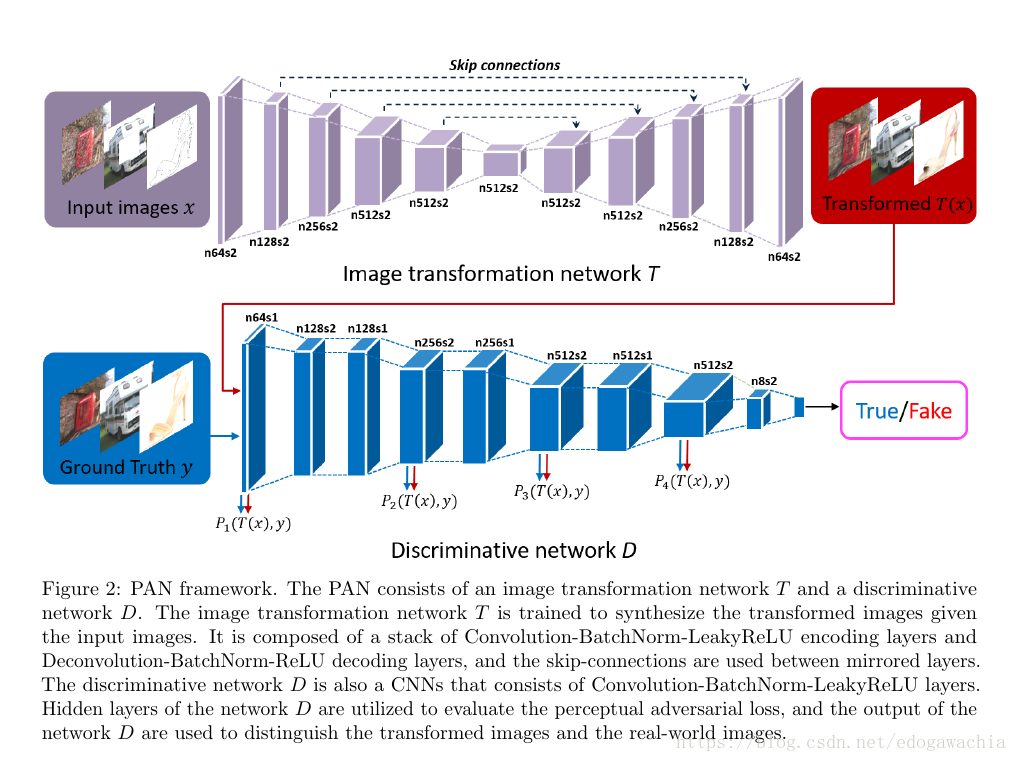
作为GAN网络,GAN loss和传统的gan一样:min max E[logD(y)] + E[log(1-D(T(x)))] ,这里的T是Transform网络,D就是判别网络,x是输入,比如snowy,rainy,或者inpainting里用的缺少部分的图片,或者用来补全的图画的轮廓等。y是真是图像。
下面是perceptual loss,这个loss实际上就是对网络的高层的偏离的一个惩罚,因为我们任务高层网络含有知觉意义上的信息,或者说是类似语义上的信息。具体的操作就是:
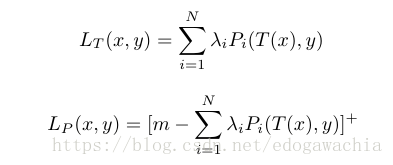
上面的lambda是超参数,Pi是第i层的一个函数,计算T(x)和y的偏差,这里用了l1-norm。这样,最终的loss 函数就是:
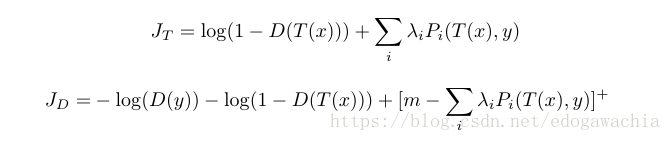
T(就是G)和D的loss 函数分别代表的意义如下:T希望我们生成的图像能够在D的判决下更趋向于1,也就是True,而且希望T(x)和y的perceptual的距离更加接近。而D刚好相反,一方面希望两者尽量分开,另一方面希望两者perceptual距离更大。但是m是一个margin,超过了这一项就变成0,并且没有gradient了。
然后T网络的参数如下;

可以看到,这个T网络加跳线用的是concatenate拼接,而且最后一层用了tanh,leaky-relu只出现在某几层。还可以看到用了BN层。
然后这是D网络的结构:

下图是一些对参数的讨论:

上面的比较是针对不同的loss function,下面的是用把lambda向量中的某一项置1,其他置0而得到的perceptual loss function 来训练得到的结果,可以看出,对高层进行perceptual的约束可以更好的回复高频,但是会丢失颜色信息;而对低层约束可以注意颜色,却无法恢复细节,从而产生blurring。所以将不同层的约束integrate起来。
下面的是跟其他方法如IDGAN或者pix2pix的比较,就不放图了。。。
conclusion
这个PAN网络的一个主要的改进就是损失函数,把perceptual loss和gan相结合,得到了更好的效果。(之前的pix2pix是把l1 loss和gan loss相结合)
2018年03月27日16:52:53