论文题目:Real-Time MDNet
文献地址:https://arxiv.org/pdf/1808.08834.pdf
源码地址:https://github.com/IlchaeJung/RT-MDNet
Performance: MDNet vs RT-MDNet
RT-MDNet是MDnet的改进版,从作者单位来看,这两篇文献出自同一实验室。
Motivation
- 实时性
MDNet网络组成结构会让人联想到R-CNN,也会担忧MDNet的时效性。RT-MDNet从名称上可以看出该论文的切入点是MDNet的时效性,毕竟MDNet太慢了(1fps)。由于MDNet实时性差的原因与R-CNN病症相同,解决这样的问题会联想到RoIPooling,RoIAlign等Faster/Mask R-CNN中使用的技巧(从发表时间上也可以看出,这篇文献在Mask R-CNN之后)。本篇作者也是使用RoIAlign的方式,并对RoIAlign进行适当的改进。速度提升了25倍。
- 提升instance-level的分类能力
另一方面,作者认为前作在instance-level分类能力不够,在损失函数上做了些文章,想要做出一个分辨能力更强的模型。
这里所说的instance-level属于tracking 和 segmentation中的问题。简单来说,detection的任务是在category-level,即检测出东西属于哪一类即可。而在tracking和segmentation中会定义instance-level,即跟踪的哪一个人,哪一架无人机,要精确到实例个体,而不仅仅是语义的类别。下图是分割领域关于二者的区分。

Contribution
通过上面动机的分析,其实已经可以看出本篇主要包含两个contibution:
- 受Mask R-CNN的启发,提出了一种 Improved RoIAlign
- 对损失函数进行了改进,加入了一个 instance embedding loss
Performance: MDNet vs RT-MDNet
首先,欣赏一下改进前后二者的表现。(是骡子是马拉出来溜溜~)
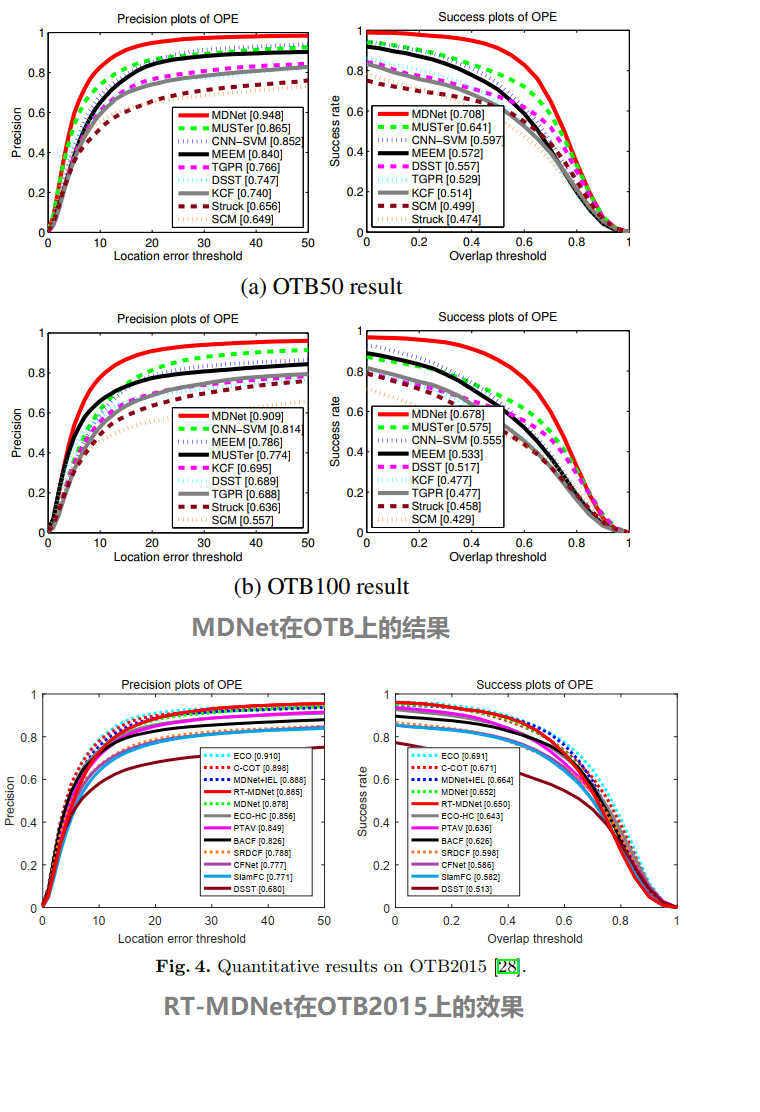
首先OTB100和OTB2015实际上是一个数据集,只不过一个以数量记名,一个以年份记名。(其对应视频序列为作者发表文章Wu Y, Lim J, Yang M H. Object tracking benchmark [J]. TPAMI, 2015.中的100个视频序列)那有意思的来了:
- MDNet论文中给出的precision分数是0.909,success分数是0.708;而RT-MDNet给出的MDNet的precision分数是0.878,success分数是0.652。差好多... 一个实验室的这么互相伤害真的好吗?
- 当overlap threshold大于0.8后,RT-MDNet在success上出现了明显的掉点,几乎已经处于最下沿。
RT-MDNet
网络结构
如下图所示,由于要使用RoIAlign方式对MDNet加速,网络的输入不能再是低分辨率的Bbox,而是整张图片。整体网络结构从外观上来看除了多了RoIAlign,与MDNet没有明显的区别。包含3个全卷积网络conv1-3,RoIAlign,2个全连接网络fc4-fc5。多域使用fc6(1-D)进行二值分类,用于区分target or background。
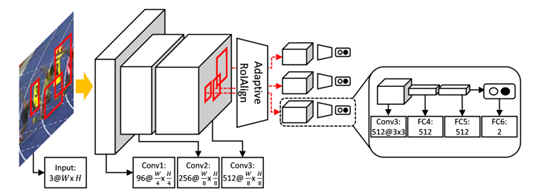
在线跟踪过程与MDNet一致,fc6(1-D)将会被一个单独的二分类fc6替代,并使用softmax交叉损失函数在第一帧进行微调。这里强调一下,本篇作者在损失函数上进行了改进,用于加强instance-level的分辨能力。
improved RoIAlign
熟悉R-CNN系列的同学对RoIAlign并不陌生,从SPPNet到RoIPooling再到RoIAlign。下图为Mask R-CNN中关于RoIAlign的示意图。RoIAlign是为了解决RoIPooling中均分而带来的边缘量化损失。具体来说,RoIPooling是为了可以固定输入的尺寸,将feature map划分为几等份,然后在这几等分中分别进行最大池化提取固定长度的特征。其中划分为几等份的操作会出现不能整除的现象,RoIPooling中采用选取最大可整除的方式,舍弃不能整除部分的像素,也就是量化损失。RoIAlign不采用最大可整除的方式,而是对落在非像素点上的采样点进行双线性插值,弥补量化的损失,毕竟Mask R-CNN要做分割,量化损失不容小觑。

作者认为RoIAlign提取的特征与从单个提案边界盒中提取的特征相比,本质上是粗糙的。粗糙是采样点个数需要固定,而feature map尺寸不固定而造成的采样间隔不匹配的问题。如7×7的feature map downsample到3×3,7/3=2.33,在每个2.33×2.33的grid上采2×2共4个点;当feature map变成了14×14, 同样downsample 到 3×3,14/3=4.66, 此时采用4*4的grid进行采样16个点的效果要优于还使用2×2 4个采样点的效果。
因此,bins的个数需要自适应,作者使用[w/w']的方式进行自适应。其中,w是conv3输出的feature map中RoI的宽度;w'是RoIAlign层中RoI输出特征的宽度;[·]是四舍五入运算。
作者提出,虽然只在RoIAlign 做了小的改进,但会在跟踪效果上有很大的提升。这在一定程度上是因为,与目标检测相反,由于目标表示方式的细微差异而产生的跟踪误差会随着时间的推移而传播,并产生较大的误差,最终导致跟踪器失败。
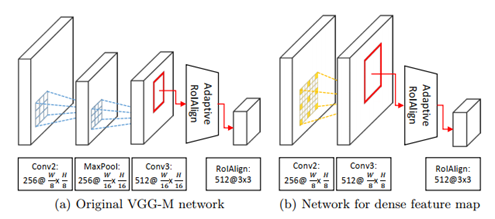
Dense feature map
由于使用了RoIAlign输入图像的分辨率变大,而网络层数并未加深,需要提升模型的感受野。因此,作者在MDNet网络结构的基础上,conv3使用r=3的空洞卷积。
Instance Embedding loss
作者在损失函数的设计上有两个目标:
-
其一是训练一个适用于多域的特征识别网络;
- MDNet只是学习目标和背景之间区别的表示。
-
另外,作者希望建立的损失函数能够拉开不同领域的目标彼此远离。结合下面类似聚类效果的图,确实这个目标很有价值。
- MDNet只是试图区分各自域中的目标和背景,没有多少能力区分在不同域中的目标。

如上图左侧部分,作者设计了两个损失函数,其一用于进行单个域中的target/background的分类;另一个是不同域之间的类别分类Linst。说白了,就是增添了一个当前RoI属于哪一个域的损失函数。确实符合目标描述的拉开不同领域的目标距离。
具体来说,主要体现在以下两个公式:
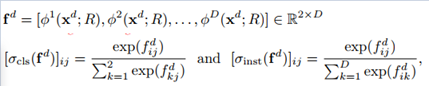
第一个公式实际上存储的是网络在每个域的输出,即target和background。x^d表示域d的输入图像,R表示对应的bbox;fd是网络输出的得分;φd为二分类的得分结果。
第一个公式在表达上如果你细抠可能会有疑问:就是关于d与D。如果φ1到φD描述了不同域的得分,那每个域中的x^d的d又如何理解,难道不是一个域输入一个域的图片吗?这里还真不是,因为它后续要做softmax损失函数,并且包含当前bbox(RoI)属于哪一个域的损失函数Linst。也就是说,作者这里假设的是输入图片是哪个域是未知的,并没有按照顺序一一对应的关系。所以x^d的表示是因为不知道该图片属于哪个域,所以哪个域都会有这个输入的形式。【原谅我之前是做优化的,对上下标都不放过...】由于这样的输出存储,在二分类上也不得不用softmax了吧。
第二个公式就简单了,就是两个softmax,一个是target与background二分类的softmax,另一个是当前bbox属于哪个域的多分类softmax。
基于此,将会产生损失函数三元组:两个损失函数,一个整合两个损失函数:
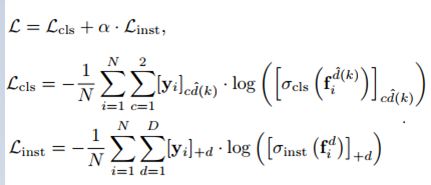
在线跟踪
这部分和MDNet是一致的,包括随机/最终bbox的生成方式、bbox回归训练与在线使用的方式、以及两种在线更新调用的方式。不了解的小伙伴可以猛戳MDNet!