论文题目:Real-time Scene Text Detection with Differentiable Binarization
文献地址:https://arxiv.org/abs/1911.08947
源码地址:https://github.com/MhLiao/DB (Pytorch版)
近年,由于基于分割的方法对各种形状(弯曲、竖直、多方向)的场景文本检测更加精确,因此,基于分割的方法在场景文本检测领域很流行。
基于分割的场景文本检测即把分割方法产生的概率图(热力图)转化为边界框和文字区域,其中会包含二值化的后处理过程。二值化的过程非常关键,常规二值化操作通过设定固定的阈值,然而固定的阈值难以适应复杂多变的检测场景。本文作者提出了一种可微分的二值化操作,通过将二值化操作插入到分割网络中进行组合优化,从而实现阈值在热力图各处的自适应。

DB在场景文本检测上的效果

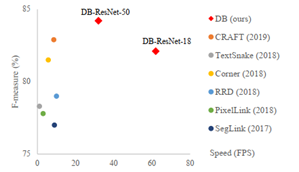
作者在5个标准数据集上进行对比实验,其中包括2个弯曲文本数据集,1个多方向文本数据集,2个多语言数据集:
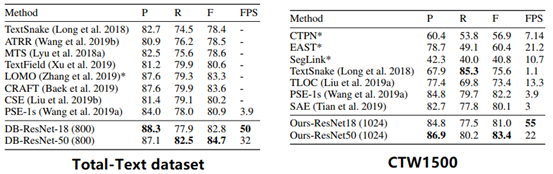
- 弯曲文本数据集:Total-Text dataset && CTW1500
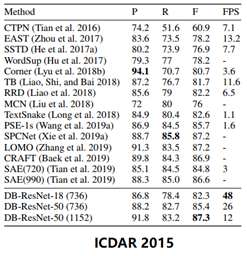
- 多方向文本数据集: ICDAR 2015
- 多语言数据集 : MSRA-TD500 && MLT-2017

场景文本检测的现状
近年,由于场景文字识别有着广泛的实际应用价值,比如图像/视频理解,视觉搜索,自动驾驶,盲文辅助等。
作为场景文字识别的一个核心组件,场景文字检测(scene text detection)的目的在于定位每一个文字实例的边界框和区域,但这并非易事,因为,文字常常有着不同的大小和形状,比如水平,多方向和弯曲。
得益于像素级别的预测结果,基于分割的场景文字检测方法可以描述不同形状的文字,因而最近流行开来。但是,大多数基于分割的方法需要复杂的后处理,把像素级别的预测结果分类为已检测的文字实例,导致推理的时间成本相当高。
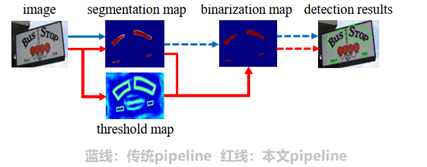
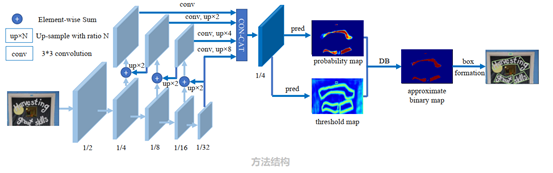
下图是传统pipeline和本文提出pipeline的区别,传统的pipeline使用固定的阈值对于分割后的热力图进行二值化处理;而本文提出的pipeline会将二值化操作嵌入到分割网络中进行组合优化,如下图红线,会生成与热力图对应的阈值图,通过二者的结合生成最终的二值化操作。
作者总结了本文提出的DB模块具备显著的优势:
- 本文方法连续在水平、多方向和弯曲文字在内的 5 个基准数据集上获得更加性能;
- 本文方法比先前的方法速度更快;
- 在使用轻量级 backbone 时,DB 表现相当好;
- 由于可以在推理阶段删除DB而不牺牲性能,因此测试不会产生额外的内存/时间成本。就像BN操作在网络中的作用。
方法
如下图方法结构图所示,首先,图片通过特征金字塔结构的backbone,通过上采样的方式将特征金字塔的输出变换为同一尺寸,并级联(cascade)产生特征F;然后,通过特征图F预测概率图(P)和阈值图(T);最后,通过概率图P和阈值图T生成近似的二值图(B)。
在训练阶段,监督被应用在阈值图、概率图和近似的二值图上,其中后两者共享同一个监督;在推理阶段,则可以从后两者轻松获取边界框。
可微分二值化
下式表示了传统二值化操作的方法,其中P表示概率图,t表示划分阈值。通过固定的阈值对网络输出的概率图进行划分。
由于这种二值化方式是不可微分的,因此它无法在训练阶段随着分割网络被优化。
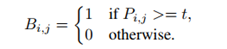
因此,作者提出了一个approximate step function,用于将二值化操作融合于分割网络中。如下式所示,建立了概率图P和阈值图T与二值化图之间的关系,使得二值化的计算可微,从而可以满足梯度反向传播的条件。
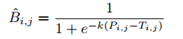
其中,k为放大因子,依经验设定为50.
带有自适应阈值的可微分二值化不仅有助于把文字区域与背景区分开,而且还能把相近的实例分离开来。
自适应阈值
在可微分二值化中,将阈值图、概率图建立可微的关系生成二值图实际上已经解决了阈值自适应的问题。
而下图显示的是阈值图T在有、无监督下的表现。
即使没有监督的阈值图,阈值图也能突出文本边界区域。这表明像边界一样的阈值图有利于最终的结果。因此,作者在阈值图上应用边界监督来更好地指导。
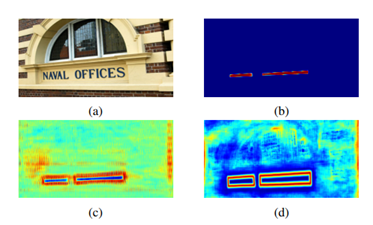
上图中,图a为原图,图b为概率图,图c为无监督的阈值图,图d为有监督的阈值图。
标签的生成
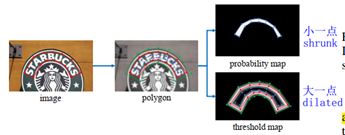
对于概率图标签的生成,作者受到了PSENet的启发。给定一张文字图像,其文本区域的每个多边形由一组线段描述:
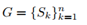
其中,n表示顶点的数量。
通过 Vatti clipping 算法 (Vati 1992)缩小多边形。收缩偏移量D可以通过周长L和面积A计算:
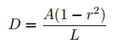
其中,r是收缩因子,依经验设置为0.4.
优化
损失函数是通过概率图损失Ls - 二值图损失Lb - 阈值图Lt构成的带有权重的损失。
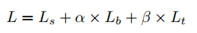
其中,α,β分别设置为1.0和10.
Ls和Lb使用二值交叉熵损失函数:
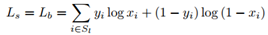
其中,Sl表示正负样本比例为1:3的样本集。
Lt使用L1距离损失函数。
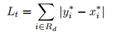
番外篇
另外百度paddlehub中开源的中文OCR识别可以支持中英文、数字组合识别,竖排文字识别,长文本识别等场景。其使用的模型便是基于本篇介绍的模型Differentiable Binarization ,外加CRNN。
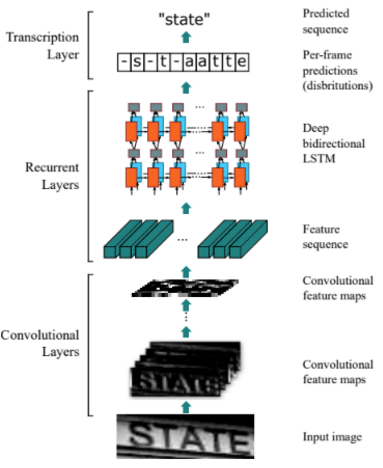
CRNN是卷积递归神经网络,是DCNN和RNN的组合,专门用于识别图像中的序列是对象。与CTC loss配合使用,进行文字识别,可以直接从文本词级或行级的标注中学习,不需要详细的字符级的标注。参考论文:An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition
基本结构如下:
基于百度paddle中提供的接口可以实现下面的效果:

