训练的过程中,损失函数的计算需要真值。
摘要
训练过程中,真值主要包含三种类型:
- 缩放后的图像
- 缩放后的标定框
- 三种尺度的真值
(需要注意框在不同阶段是相对于谁的位置)
关于前两项:
由于输入的图像与模型的输入尺寸可能不 一致,而需要对图像进行缩放,使图像适应模型的输入。
由于图像需要适应模型的输入,那么为图像标定的框的坐标也需要随着图像尺寸的缩放进行调整。
一张图片可能会对多个物体进行标定,即会包含多个box,代码中,对于一张图片,最多只记录20个box 的坐标(其包含max_box的设定)。 也就是说,训练集图像的选取中,要标定的数据最好不要超过20个。
此时,返回的box信息依旧是xmin, ymin, xmax, ymax,类别. 只不过是适应图像调整之后的。
关于尺度的真值:
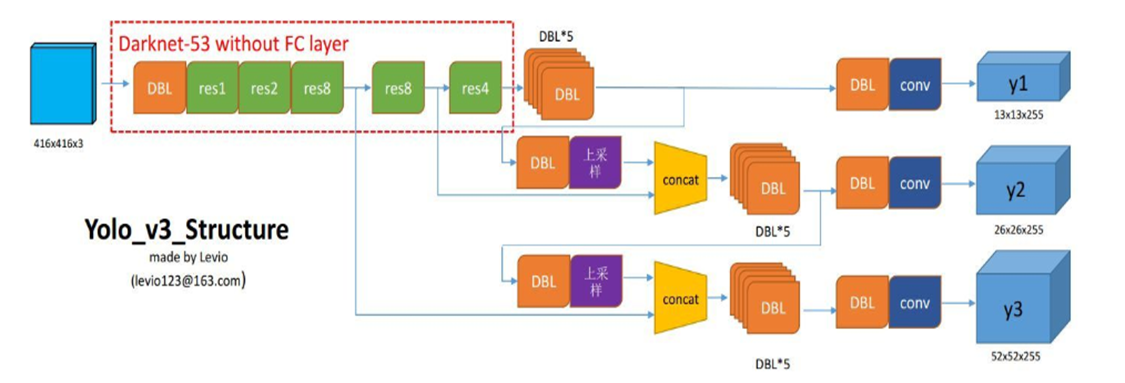
由于YOLO v3的一大亮点就是通过构建输出的模样让模型性通过学习,一次性的输出图像包含的位置信息和类别信息。 y_true的构建是该算法的核心之一.
由于前两项输出了模型的输入(尺寸规范化后的图像和相应的边框信息)
此处,需要边框信息转化为中心、宽高等信息, 并对其信息进行归一化。(存储的是相对于整张图片的位置)
由于, YOLO v3中包含多尺度的预测,也就是需要对不同的物体归属到不同的尺度中去。所以还包含有标定边框对应锚框的问题。 (找到一张图中所有标注对应最好的anchor, 并将其分配值对应的输出中)
每个ground truth box只会选用一个与它有最大IOU的anchor box作为正的anchor box,而不再使用一个threshold(一般为0.5),然后将超过此threshold值的anchor box也视为正样本框。 (正样本只要IOU最大的,而不是超过某一阈值的都是正样本(预测的时候才会有阈值的设定和nms))
代码解读
在进入训练中,通过predict_generator和后续的fit_generator提供真实的数据(入口):
1 bottlenecks=bottleneck_model.predict_generator(data_generator_wrapper(lines, batch_size, input_shape, anchors, num_classes, random=False, verbose=True), 2 steps=(len(lines)//batch_size)+1, max_queue_size=1)
- annotation_lines:标注数据的行,每行数据包含图片路径,和框的位置信息;
- batch_size:批次数,每批生成的数据个数;
- input_shape:图像输入尺寸,如(416, 416);
- anchors:anchor box列表,9个宽高值;
- num_classes:类别的数量;
data_generator_wrapper
判断输入的数据是否正确,然后调用data_generator
1 def data_generator_wrapper(annotation_lines, batch_size, input_shape, anchors, num_classes, random=True, verbose=False): 2 n = len(annotation_lines) 3 if n==0 or batch_size<=0: return None 4 return data_generator(annotation_lines, batch_size, input_shape, anchors, num_classes, random, verbose)
data_generator()
1 def data_generator(annotation_lines, batch_size, input_shape, anchors, num_classes, random=True, verbose=False): 2 '''data generator for fit_generator''' 3 n = len(annotation_lines) 4 i = 0 5 while True: 6 image_data = [] 7 box_data = [] 8 for b in range(batch_size): 9 if i==0 and random: 10 np.random.shuffle(annotation_lines) 11 ! image, box = get_random_data(annotation_lines[i], input_shape, random=random) 12 image_data.append(image) 13 box_data.append(box) 14 i = (i+1) % n 15 image_data = np.array(image_data) 16 if verbose: 17 print("Progress: ",i,"/",n) 18 box_data = np.array(box_data) 19 y_true = preprocess_true_boxes(box_data, input_shape, anchors, num_classes) 20 yield [image_data, *y_true], np.zeros(batch_size)
上述代码中,重要的内容包括:
- get_random_data()函数
- preprocess_true_boxes()函数
A. get_random_data():
该函数的作用:生成416*416规格的图像,并将标定框的坐标(xmin,ymin,xmax,ymax)缩放到图像缩放后的大小。
由于现在是训练的过程,为了增加模型的泛化能力与鲁棒性。 内部添加了一些随机性
a. 非随机部分(图像的伸缩和测试一致):
1 if not random: # 如果不随机 2 # resize image 图片的缩放和归一化 3 scale = min(w/iw, h/ih) # 缩放的倍数 4 nw = int(iw*scale) # 根据输入图片 和 设定图片的尺寸, 该图片可以转化成的尺寸(宽高) 5 nh = int(ih*scale) 6 dx = (w-nw)//2 # w 和 h 一定是大于等于 nw和nh的 两侧的残留 7 dy = (h-nh)//2 8 image_data = 0 9 if proc_img: 10 image = image.resize((nw, nh), Image.BICUBIC) # 先等比例缩放到nw 和nh 11 new_image = Image.new('RGB', (w,h), (128,128,128)) 12 new_image.paste(image, (dx, dy)) # 粘贴覆盖到另一个图像上面 dx 和 dy 是粘贴的起始点的横纵坐标 13 image_data = np.array(new_image)/255. # /255 进行归一化 14 15 # correct boxes 16 box_data = np.zeros((max_boxes, 5)) # 初始化坐标 和 属于哪个anchor_box 17 if len(box)>0: 18 np.random.shuffle(box) 19 if len(box)>max_boxes: box = box[:max_boxes] # 最多只取20个 为什么????????? 20 box[:, [0,2]] = box[:, [0,2]]*scale + dx # 真实框 缩放到缩放的图像中 21 box[:, [1,3]] = box[:, [1,3]]*scale + dy 22 box_data[:len(box)] = box 23 24 return image_data, box_data
为什么这个box最多只取20个呢?
答: 是在一张图中 如果有多个框的信息,最多只取20个(一张图中有多个物体),是否可以理解为选取训练集的时候,图片中目标物体的个数不要大于20个, 但为什么要这么做呢?
b.随机部分:
- 非等比缩放 (实际图的宽高会小于416,也就是四周都有灰度)
- 水平翻转
- 随机扭曲
非等比缩放
jitter默认设置为0.3,w和h是规定图像的尺寸,(416*416)
1 new_ar = w/h * rand(1-jitter, 1+jitter)/ rand(1-jitter, 1+jitter) 2 scale = rand(.25, 2) #缩放的比例也随机了 3 if new_ar < 1: 4 nh = int(scale*h) # nw 和 nh 应该可能都会小于416,之前的是至少有一个等于416 5 nw = int(nh*new_ar) # 这么做有没有可能会大于416呢?还是大于416没有关系 6 else: 7 nw = int(scale*w) 8 nh = int(nw/new_ar) 9 image = image.resize((nw,nh), Image.BICUBIC)
这么做有没有可能会大于416呢?
答:多出的部分将在显示图像的外围,即被掩盖。
将缩放的图片放置在416*416的灰片上。
1 # place image 2 dx = int(rand(0, w-nw)) 3 dy = int(rand(0, h-nh)) 4 new_image = Image.new('RGB', (w,h), (128,128,128)) 5 new_image.paste(image, (dx, dy)) # 把刚刚的图片盖在一个灰片上 6 image = new_image
依概率水平翻转
1 # flip image or not 2 flip = rand() < .5 # 依概率左右翻转 3 if flip: image = image.transpose(Image.FLIP_LEFT_RIGHT)
随机扭曲
在HSV坐标域中,改变图片的颜色范围:
- hue值相加,
- sat和vat相乘,
- 先由RGB转为HSV,再由HSV转为RGB,添加若干错误判断,避免范围过大。
hue = rand(-hue, hue) # HSV sat = rand(1, sat) if rand() < .5 else 1/rand(1, sat) val = rand(1, val) if rand() < .5 else 1/rand(1, val) x = rgb_to_hsv(np.array(image)/255.) # 转hsv x[..., 0] += hue x[..., 0][x[..., 0] > 1] -= 1 x[..., 0][x[..., 0] < 0] += 1 x[..., 1] *= sat x[..., 2] *= val x[x>1] = 1 x[x<0] = 0 image_data = hsv_to_rgb(x) # numpy array, 0 to 1
boxes里面存的还是坐标点
B. preprocess_true_boxes()
该函数的目的是生成与y1,y2, y3对应的模式的真值 y_true。
其输入是上述返回的box的信息,即box_data;此时不需要图像的信息,即image_data.
主要过程包括:
- 将xmin,ymin,xmax,ymax的坐标转化为boxes_xy和boxes_wh,即y_true 的模样, 并将其中的数值进行归一化。
- 初始化y_true
- 计算标定框与anchor_box之间的IOU, 将IOU最大的归为y_true对应的anchor_box中。完成一个box的归属,每次进行一张图片的y_true 的归属。
1 def preprocess_true_boxes(true_boxes, input_shape, anchors, num_classes):
- true_boxes:检测框,批次数16,最大框数20,每个框5个值,4个边界点和1个类别序号,如(16, 20, 5);
- input_shape:图片尺寸,如(416, 416);
- anchors:anchor box列表;
- num_classes:类别的数量;
1 assert (true_boxes[..., 4] < num_classes).all(), '检测类别序号是否小于类别数,避免异常数据' 2 num_layers = len(anchors)//3 # default setting 3 anchor_mask = [[6, 7, 8], [3, 4, 5], [0, 1, 2]] if num_layers == 3 else [[3, 4, 5], [1, 2, 3]] 4 5 true_boxes = np.array(true_boxes, dtype='float32') 6 input_shape = np.array(input_shape, dtype='int32') 7 boxes_xy = (true_boxes[..., 0:2] + true_boxes[..., 2:4]) // 2 # 此处的true_box的内容是xmin,ymin,xmax,ymax 8 boxes_wh = true_boxes[..., 2:4] - true_boxes[..., 0:2] 9 true_boxes[..., 0:2] = boxes_xy/input_shape[::-1] # 真实要存的是(0到1) 是中心点归一化后的数据/416 10 true_boxes[..., 2:4] = boxes_wh/input_shape[::-1] # 真实要存的是(2到3) 是宽高归一化后的数据/416
此处的真值是相对于整张图片的位置(规范化的图片)
初始化y_true
1 grid_shapes = [input_shape//{0:32, 1:16, 2:8}[l] for l in range(num_layers)] 2 y_true = [np.zeros((m,grid_shapes[l][0],grid_shapes[l][1],len(anchor_mask[l]),5+num_classes), 3 dtype='float32') for l in range(num_layers)]
这里的三重循环 是构建anchor_box 和true_box之间的联系, 求取IOU挑最大的anchor_box也是为了把该真实框分配到哪个anchor box中,即13*13*3(3的哪一个里) 正样本只要最大的!!
1 for t, n in enumerate(best_anchor): 2 for l in range(num_layers): 3 if n in anchor_mask[l]: 4 i = np.floor(true_boxes[b,t,0]*grid_shapes[l][1]).astype('int32') # 第一项是xmin的坐标点 *尺度,就是它在哪个格中 5 j = np.floor(true_boxes[b,t,1]*grid_shapes[l][0]).astype('int32') # i,j判定的是哪个格 6 k = anchor_mask[l].index(n) 7 c = true_boxes[b,t, 4].astype('int32') # 第几个类 8 y_true[l][b, j, i, k, 0:4] = true_boxes[b,t, 0:4] 9 y_true[l][b, j, i, k, 4] = 1 10 y_true[l][b, j, i, k, 5+c] = 1
代码中第4行、5行用于计算在那个网格中:
xmin * 某一层(13/26/52)的尺度缩放
ymin * 某一层(13/26/52)的尺度缩放
在每不同尺度的预测y1,y2,y3,其中包含的anchor_box 都是有固定尺寸的,训练数据集中标定的框需要与anchor_box求IOU,会在IOU最大的anchor_box中获得该标定框的信息。