题目原文
1046. 最后一块石头的重量
有一堆石头,每块石头的重量都是正整数。
每一回合,从中选出两块 最重的 石头,然后将它们一起粉碎。假设石头的重量分别为 x 和 y,且 x <= y。那么粉碎的可能结果如下:
- 如果
x == y,那么两块石头都会被完全粉碎; - 如果
x != y,那么重量为x的石头将会完全粉碎,而重量为y的石头新重量为y-x。
最后,最多只会剩下一块石头。返回此石头的重量。如果没有石头剩下,就返回 0。
示例:
输入:[2,7,4,1,8,1] 输出:1 解释: 先选出 7 和 8,得到 1,所以数组转换为 [2,4,1,1,1], 再选出 2 和 4,得到 2,所以数组转换为 [2,1,1,1], 接着是 2 和 1,得到 1,所以数组转换为 [1,1,1], 最后选出 1 和 1,得到 0,最终数组转换为 [1],这就是最后剩下那块石头的重量。
提示:
1 <= stones.length <= 301 <= stones[i] <= 1000
尝试解答
首先这是一道简单题,我用的传统排序的方法,选这道题的目的其实是为了说一下堆相关的知识,下面是我的代码,思路无脑易懂,在这里就不废话了:
1 class Solution { 2 public int lastStoneWeight(int[] stones) { 3 Arrays.sort(stones); 4 List<Integer> list = new ArrayList<>(); 5 for(int i=0;i<stones.length;i++) { 6 list.add(stones[i]); 7 } 8 while(true) { 9 if(list.size()<=1) { 10 return list.size()==0?0:list.get(0); 11 } 12 int y = list.remove(list.size()-1); 13 int x = list.remove(list.size()-1); 14 if(y!=x) { 15 int z = y-x; 16 if(list.size()==0) { 17 return z; 18 } 19 if(list.size()==1) { 20 return Math.abs(z-list.get(0)); 21 } 22 //将z插入到合适的位置 23 boolean vias = false; 24 for(int i=0;i<list.size()-1;i++) { 25 if (z>=list.get(i) && z<list.get(i+1)) { 26 list.add(i+1,z); 27 vias = true; 28 break; 29 } 30 else if(z<list.get(0)) { 31 list.add(0,z); 32 vias = true; 33 break; 34 } 35 } 36 if(!vias) { 37 list.add(z); 38 } 39 } 40 } 41 } 42 }
标准题解
将所有石头的重量放入最大堆中。每次依次从队列中取出最重的两块石头 a 和 b,必有 a≥b。如果 a>b,则将新石头 a−b 放回到最大堆中;如果a=b,两块石头完全被粉碎,因此不会产生新的石头。重复上述操作,直到剩下的石头少于2块。最终可能剩下 1 块石头,该石头的重量即为最大堆中剩下的元素,返回该元素;也可能没有石头剩下,此时最大堆为空,返回 0。
先上代码,十分之简练易读,就是使用了java集合中的PriorityQueue,然后队列的维护都是基于包内的函数,而思想是基于最大堆,因此我们不仅要弄懂最大堆的机理也要弄懂java优先队列的实现方式最后再搞清楚PriorityQueue的具体一些用法,这篇博文的目的就达到了。
1 class Solution { 2 public int lastStoneWeight(int[] stones) { 3 PriorityQueue<Integer> pq = new PriorityQueue<Integer>((a, b) -> b - a); 4 for (int stone : stones) { 5 pq.offer(stone); 6 } 7 8 while (pq.size() > 1) { 9 int a = pq.poll(); 10 int b = pq.poll(); 11 if (a > b) { 12 pq.offer(a - b); 13 } 14 } 15 return pq.isEmpty() ? 0 : pq.poll(); 16 } 17 } 18 19 20 //作者:LeetCode-Solution 21 //链接:https://leetcode-cn.com/problems/last-stone-weight/solution/zui-hou-yi-kuai-shi-tou-de-zhong-liang-b-xgsx/ 22 //来源:力扣(LeetCode) 23 //著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
思路没什么可说的,但是里面引入的最大堆的概念,这个数据结构本身就比较好玩了,下面我将会从最大堆自身的机理、java的优先队列PriorityQueue两个方面来讲。
思路差距
首先我在做题的时候是想到了在石头序列中执行插入操作的时候使用二分法查找插入位置,但一看石头最多有30个,大e了,没有闪。这里其实应该想到,除了可以使用朴素的二分查找合适的插入位置,还可以使用最大堆的方法更为快速的找到合适的插入位置。
技术差距
首先说一下堆的机理:
首先我们应该知道堆的基本性质:

除此之外还有二叉树的一些基本性质(堆本身就是完全二叉树):
1、在二叉树的第i层上至多有2i-1个结点(i>=1),
2、深度为k的二叉树至多有2k-1个结点(k>=1)。
知道了基本性质就能理解下面的堆维护、堆建立、堆排序的代码了,堆排序在我之前的一篇博客里讲过,在这里就不重复了。
1 //堆有三个操作。维护堆,建堆,堆排序。 2 public class heapsort { 3 // 维护最大堆 4 public static void maxheap(int nums[], int i,int size) { 5 // 左孩子节点 6 int l = 2*i+1; 7 // 右孩子节点 8 int r = 2*i+2; 9 // 最大数节点 10 int largest; 11 // 如果左孩子节点在队列范围并且大于父节点 12 if(l<=size-1 &&nums[l]>nums[i]){ 13 largest = l; 14 }else { 15 // 可能是没有子节点或者是父节点大于子节点 16 largest = i; 17 } 18 // 右节点存在并且右节点大于左节点(父节点) 19 if (r<=size-1 && nums[r]>nums[largest]){ 20 largest = r; 21 } 22 // 最大节点不是父节点 23 if (largest!=i){ 24 int temp = nums[i]; 25 nums[i] = nums[largest]; 26 nums[largest] = temp; 27 // 交换值后,以下标为largest节点的子节点可能违反最大堆特性所以要递归调用 28 maxheap(nums,largest,size); 29 30 } 31 } 32 // 建立堆 33 public static void buildheap(int nums[]) { 34 // 一个二叉树叶节点只有一半 35 for (int i =nums.length/2-1;i>=0;i--){ 36 maxheap(nums,i,nums.length); 37 } 38 } 39 // 因为是个最大堆,依次减去剩下最大堆的头结点来进行排序。 40 public static void sortheap(int nums[]){ 41 // 先建好最大堆 42 buildheap(nums); 43 // 堆的长度 44 int j = nums.length; 45 // 把根节点和最后一个叶节点交换,并且更新数组长度。 46 while(j>1){ 47 int temp = nums[0]; 48 nums[0] = nums[j-1]; 49 nums[j-1] = temp; 50 j--; 51 maxheap(nums,0,j); 52 } 53 } 54 public static void main(String[] args) { 55 int a[] ={4,1,3,2,16,9,10,14,8,7}; 56 sortheap(a); 57 for (int b:a){ 58 System.out.print(b+","); 59 } 60 } 61 }
然后再介绍一下java中的PriorityQueue:
以下内容转载自CSDN@汉尼博 的博客https://blog.csdn.net/u010623927/article/details/87179364
实现原理:
Java中PriorityQueue通过二叉小顶堆实现,可以用一棵完全二叉树表示(任意一个非叶子节点的权值,都不大于其左右子节点的权值),也就意味着可以通过数组来作为PriorityQueue的底层实现。
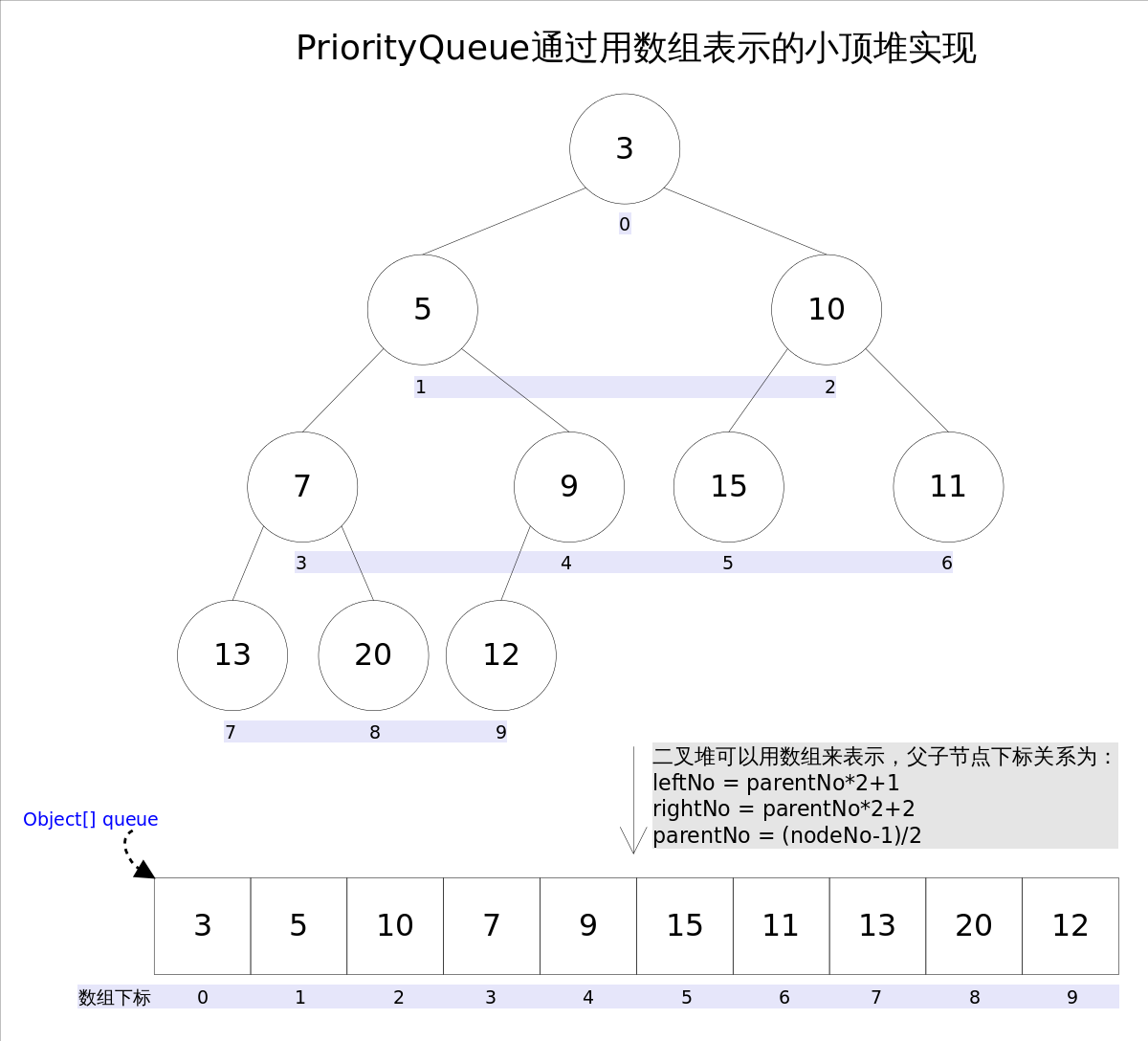
上图中我们给每个元素按照层序遍历的方式进行了编号,如果你足够细心,会发现父节点和子节点的编号是有联系的,更确切的说父子节点的编号之间有如下关系:
leftNo = parentNo*2+1
rightNo = parentNo*2+2
parentNo = (nodeNo-1)/2
通过上述三个公式,可以轻易计算出某个节点的父节点以及子节点的下标。这也就是为什么可以直接用数组来存储堆的原因。
PriorityQueue的peek()和element操作是常数时间,add(), offer(), 无参数的remove()以及poll()方法的时间复杂度都是log(N)。
方法剖析
add()和offer()
add(E e)和offer(E e)的语义相同,都是向优先队列中插入元素,只是Queue接口规定二者对插入失败时的处理不同,前者在插入失败时抛出异常,后则则会返回false。对于PriorityQueue这两个方法其实没什么差别。

新加入的元素可能会破坏小顶堆的性质,因此需要进行必要的调整。
-
//offer(E e)
-
public boolean offer(E e) {
-
if (e == null)//不允许放入null元素
-
throw new NullPointerException();
-
modCount++;
-
int i = size;
-
if (i >= queue.length)
-
grow(i + 1);//自动扩容
-
size = i + 1;
-
if (i == 0)//队列原来为空,这是插入的第一个元素
-
queue[0] = e;
-
else
-
siftUp(i, e);//调整
-
return true;
-
}
上述代码中,扩容函数grow()类似于ArrayList里的grow()函数,就是再申请一个更大的数组,并将原数组的元素复制过去,这里不再赘述。需要注意的是siftUp(int k, E x)方法,该方法用于插入元素x并维持堆的特性。
-
//siftUp()
-
private void siftUp(int k, E x) {
-
while (k > 0) {
-
int parent = (k - 1) >>> 1;//parentNo = (nodeNo-1)/2
-
Object e = queue[parent];
-
if (comparator.compare(x, (E) e) >= 0)//调用比较器的比较方法
-
break;
-
queue[k] = e;
-
k = parent;
-
}
-
queue[k] = x;
-
}
新加入的元素x可能会破坏小顶堆的性质,因此需要进行调整。调整的过程为:从k指定的位置开始,将x逐层与当前点的parent进行比较并交换,直到满足x >= queue[parent]为止。注意这里的比较可以是元素的自然顺序,也可以是依靠比较器的顺序。
element()和peek()
element()和peek()的语义完全相同,都是获取但不删除队首元素,也就是队列中权值最小的那个元素,二者唯一的区别是当方法失败时前者抛出异常,后者返回null。根据小顶堆的性质,堆顶那个元素就是全局最小的那个;由于堆用数组表示,根据下标关系,0下标处的那个元素既是堆顶元素。所以直接返回数组0下标处的那个元素即可。
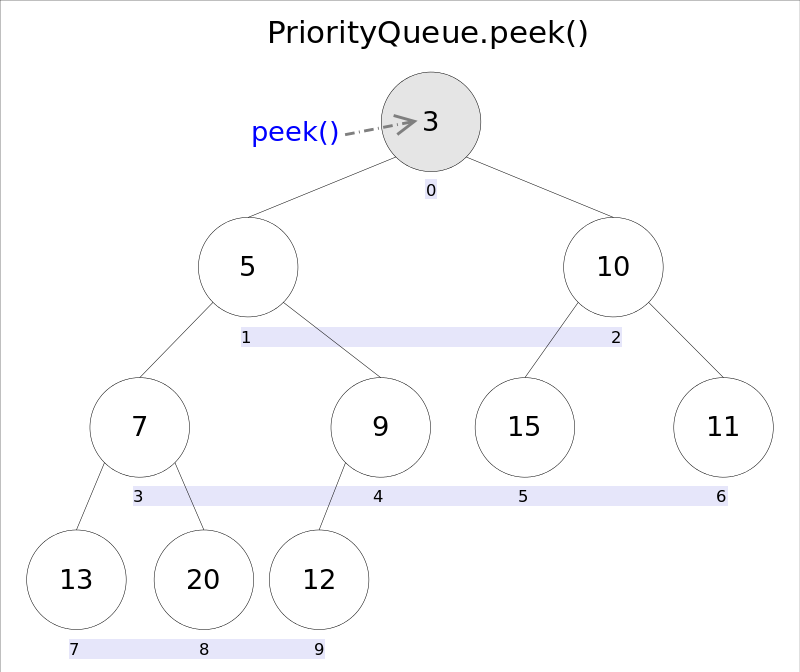
代码也就非常简洁:
-
//peek()
-
public E peek() {
-
if (size == 0)
-
return null;
-
return (E) queue[0];//0下标处的那个元素就是最小的那个
-
}
remove()和poll()
remove()和poll()方法的语义也完全相同,都是获取并删除队首元素,区别是当方法失败时前者抛出异常,后者返回null。由于删除操作会改变队列的结构,为维护小顶堆的性质,需要进行必要的调整。

代码如下:
-
public E poll() {
-
if (size == 0)
-
return null;
-
int s = --size;
-
modCount++;
-
E result = (E) queue[0];//0下标处的那个元素就是最小的那个
-
E x = (E) queue[s];
-
queue[s] = null;
-
if (s != 0)
-
siftDown(0, x);//调整
-
return result;
-
}
上述代码首先记录0下标处的元素,并用最后一个元素替换0下标位置的元素,之后调用siftDown()方法对堆进行调整,最后返回原来0下标处的那个元素(也就是最小的那个元素)。重点是siftDown(int k, E x)方法,该方法的作用是从k指定的位置开始,将x逐层向下与当前点的左右孩子中较小的那个交换,直到x小于或等于左右孩子中的任何一个为止。
-
//siftDown()
-
private void siftDown(int k, E x) {
-
int half = size >>> 1;
-
while (k < half) {
-
//首先找到左右孩子中较小的那个,记录到c里,并用child记录其下标
-
int child = (k << 1) + 1;//leftNo = parentNo*2+1
-
Object c = queue[child];
-
int right = child + 1;
-
if (right < size &&
-
comparator.compare((E) c, (E) queue[right]) > 0)
-
c = queue[child = right];
-
if (comparator.compare(x, (E) c) <= 0)
-
break;
-
queue[k] = c;//然后用c取代原来的值
-
k = child;
-
}
-
queue[k] = x;
-
}
remove(Object o)
remove(Object o)方法用于删除队列中跟o相等的某一个元素(如果有多个相等,只删除一个),该方法不是Queue接口内的方法,而是Collection接口的方法。由于删除操作会改变队列结构,所以要进行调整;又由于删除元素的位置可能是任意的,所以调整过程比其它函数稍加繁琐。具体来说,remove(Object o)可以分为2种情况:1. 删除的是最后一个元素。直接删除即可,不需要调整。2. 删除的不是最后一个元素,从删除点开始以最后一个元素为参照调用一次siftDown()即可。此处不再赘述。
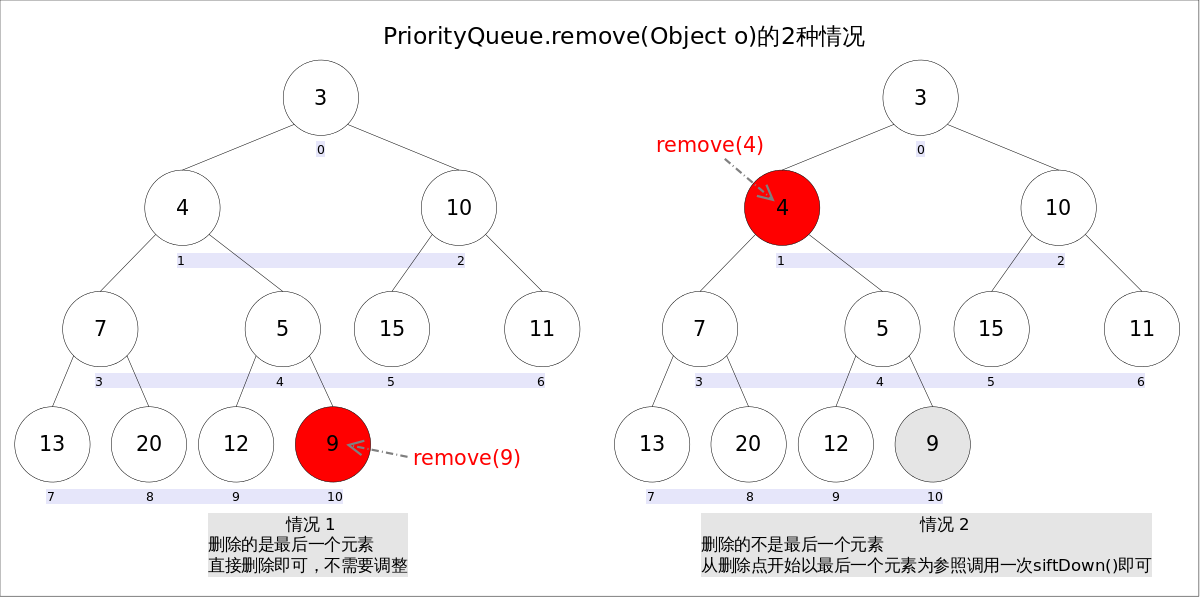
具体代码如下:
-
//remove(Object o)
-
public boolean remove(Object o) {
-
//通过遍历数组的方式找到第一个满足o.equals(queue[i])元素的下标
-
int i = indexOf(o);
-
if (i == -1)
-
return false;
-
int s = --size;
-
if (s == i) //情况1
-
queue[i] = null;
-
else {
-
E moved = (E) queue[s];
-
queue[s] = null;
-
siftDown(i, moved);//情况2
-
......
-
}
-
return true;
-
}