1.加载与执行:
(1)将脚本放在底部;(否则会阻塞)
(2)由于每个<script>标签初始下载时都会阻塞页面渲染,所以减少页面包含的<script>标签数量有助于改善这一情况。这不仅仅针对外链脚本,内嵌脚本的数量同样也要限制。浏览器在解析HTML页面的过程中每遇到一个<script>标签,都会因执行脚本而导致一定的延时,因此最小化延迟时间将会明显改善页面的总体性能。(多个js文件可以使用合并处理器,合成一个js文件)
(3)延迟的脚本:defer属性;
任何带有defer属性的<script>元素在DOM完成加载之前都不会被执行,无论内嵌或外链脚本都是如此。带有defer属性的<script>元素不是跟在第二个后面执行,而是在onload事件处理器执行之前被调用。
(4)推荐的无阻塞模式:向页面添加大量javascript的推荐做法只有两步:先添加动态加载所需的代码,然后加载初始化页面所需的剩下的代码。(封装的loadScript()函数加载)
(5)XHR脚本注入:这种方法的主要优点是,你可以下载不立即执行的 JavaScript 代码。由于代码返回在<script>标签之外 (换句话说不受<script>标签约束),它下载后不会自动执行,这使得你可以推迟执行,直到一切都准备好了。另一个优点是,同样的代码在所有现代浏览器中都不会引发异常。 最主要的限制是: JavaScript 文件必须与页面放置在同一个域内,不能从 CDNs 下载( CDN 指“内容投递网络( Content Delivery Network) ”,前面 002 篇《成组脚本》一节提到)。正因为这个原因,大型网页通常不采用 XHR 脚本注入技术。
总结:多种无阻塞下载js文件的方法:a. 使用<script>标签的defer属性; b. 使用动态创建的<script>元素来下载并执行代码; c. 使用XHR对象下载js代码并注入页面;
2.数据存取:
(1)javascript有四种基本的数据存取位置:字面量;本地变量;数组元素;对象成员;
字面量:只代表自身,不存储在特别位置。js中的字面量有:字符串、数字、布尔值、对象、数组、函数。正则表达式、null及undefined值;
本地变量:开发人员使用关键字var定义的数据存储单元;
数组元素:存储在js数组对象内部,以数字作为索引;
对象成员:存储在js对象内部,以字符串作为索引;
如果在乎运行速度,那么尽量使用字面量和局部变量,减少数组项和对象成员的使用。
(2)作用域:
每一个 JavaScript 函数都被表示为对象。进一步说,它是一个函数实例。函数对象正如其他对象那样,拥有你可以编程访问的属性,和一系列不能被程序访问,仅供 JavaScript 引擎使用的内部属性。其中一个内部属性是[[Scope]]。内部[[Scope]]属性包含一个函数被创建的作用域中对象的集合。此集合被称为函数的作用域链,它决定哪些数据可由函数访问。此函数作用域链中的每个对象被称为一个可变对象,每个可变对象都以“键值对” 的形式存在。当一个函数创建后,它的作用域链被填充以对象,这些对象代表创建此函数的环境中可访问的数据。
function add(num1, num2){ var sum = num1 + num2; return sum; }




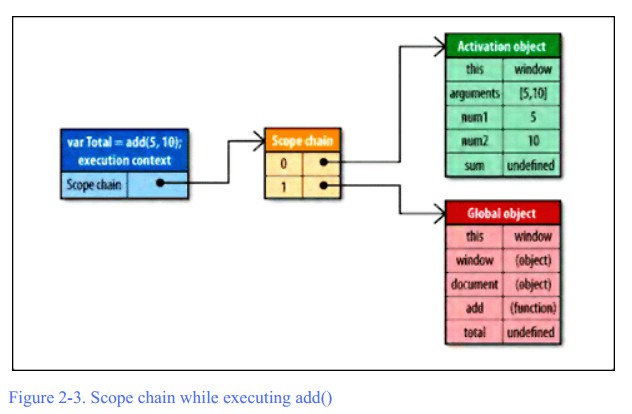
(3)标识符解析的性能:在执行环境的作用域链中,一个标识符所在的位置越深,它的读写速度也就越慢。因此,函数中读写局部变量总是最快的,而读写全局变量通常是最慢的(优化js引擎在某些情况下能有所改善,比如chrome和safari)。请记住,全局变量总是存在于执行环境作用域链的最末端,因此它也是最远的。
因此,在没有优化js引擎的浏览器中,建议尽可能使用局部变量,一个好的经验法则是:如果某个跨作用域的值在函数中被引用一次以上,那么就把它存储到局部变量里。
比如: function initUI(){ var bd = document.body, links = document.getElementsByTagName_r("a"), i = 0, len = links.length; while(i < len){ update(links[i++]); } document.getElementById("go-btn").onclick = function(){ start(); }; bd.className = "active"; }
可重写为:
function initUI(){ var doc = document, bd = doc.body, links = doc.getElementsByTagName_r("a"),i = 0, len = links.length; while(i < len){ update(links[i++]); } doc.getElementById("go-btn").onclick = function(){ start(); }; bd.className = "active"; }
更新后的 initUI() 函数首先把 document 对象的引用存储到局部变量 doc 中,访问局部变量的次数由3次减少到1次。由于doc是局部变量,因此通过它访问 document 会更快。
(4)对象成员:
搜索实例成员比从字面量或局部变量中读取数据代价更高,再加上遍历原型链带来的开销,这让性能问题更为严重。
由于所有这些性能问题与对象成员有关,所以如果可能的话请避免使用它们。更确切地说,你应当小心地,只在必要情况下使用对象成员。例如,没有理由在一个函数中多次读取同一个对象成员的值 。一般来说,如果在同一个函数中你要多次读取同一个对象属性,最好将它存入一个局部变量。以局部变量替代属性,避免多余的属性查找带来性能开销。
(提示:这种优化并不推荐用于对象的成员方法。因为许多对象方法使用this来判断执行环境,把一个对象方法保存在局部变量会导致this绑定到window,而this值的改变会使得js引擎无法正确解析它的对象成员,进而导致程序出错)
总结:
1. 在 JavaScript 中,数据存储位置可以对代码整体性能产生重要影响。有四种数据访问类型:直接量,变量,数组项,对象成员。它们有不同的性能考虑。 直接量和局部变量访问速度非常快,数组项和对象成员需要更长时间。
2. 局部变量比域外变量快,因为它位于作用域链的第一个对象中。变量在作用域链中的位置越深,访问所需的时间就越长。全局变量总是最慢的,因为它们总是位于作用域链的最后一环。
3. 避免使用 with 表达式, 因为它改变了运行期上下文的作用域链。而且应当小心对待 try-catch 表达式的 catch子句,因为它具有同样效果。
4. 嵌套对象成员会造成重大性能影响,尽量少用
5. 一个属性或方法在原形链中的位置越深,访问它的速度就越慢。
一般来说,你可以通过这种方法提高 JavaScript 代码的性能:将经常使用的对象成员,数组项,和域外变量存入局部变量中。然后,访问局部变量的速度会快于那些原始变量。
3. DOM编程:
1. 浏览器中通常会把DOM和javascript独立实现;简单理解,即两个相互独立的功能只要通过接口彼此连接,就会产生消耗;
2. 访问DOM元素是有代价的,而修改元素则更甚,它会导致浏览器重新计算计算页面的几何变化;——— 减少访问DOM的次数,把运算尽量留在 ECMAScript 这一端处理;
3. 修改页面区域的最佳方案是用非标准但支持良好的 innerHTML 属性还是 document.createElement() 原生DOM方法:在除开最新版的 Webkit 内核(Chrome 和 Safari)之外的所有浏览器中, innerHTML 会更快一点;
4. 使用 DOM 方法更新页面内容的另一个途径是克隆已有元素,即使用 element.cloneNode() (element表示已有节点)替代 document.createElement();且在大多数浏览器中,节点克隆都更有效率;
5. HTML 集合是包含了 DOM 节点引用的类数组对象。比如:document.getElementByName()、document.getElementByTagName、document.images 等,返回值均为类数组对象;事实上,HTML 集合一直与文档保持着连接,每次你需要最新的信息时,都会重复执行查询的过程,哪怕只是获取集合里的元素个数(即访问集合的 length 属性)也是如此,这正是低效之源;
6. 遍历数组比遍历集合快,因此如果先将集合元素拷贝到数组中,访问它的属性会更快;
以下的 toArray() 函数可作为一个通用的集合转数组函数:
function toArray(){ for (var i=0, a=[], len=coll.length; i<len; i++) { a[i] =coll[i]; } return a; }
7. nextSibling 与 childNodes:在 IE 中,nextSibling 方法查找 DOM 节点更快,其余 nextSibling 与 childNodes 差异不大;
8. 以下为浏览器提供的一些API,可只返回元素节点:

9. 选择器 API:
最新浏览器提供了 querySelectorAll() 方法,该方法不会返回 HTML 集合,而是返回一个 NodeList(包含着匹配节点的类数组对象),因此返回的节点不会对应实时的文档结构,同时也就避免了 HTML 集合引起的性能(和潜在逻辑)问题;
10. 重绘和重排:
浏览器下载完页面中的所有组件——HTML标记、Javascript、CSS、图片——之后会解析并生成两个内部数据结构:DOM 树(表示页面结构)和渲染树(表示DOM 节点如何显示);
当页面布局和集合属性改变时就需要“重排”,如:增删可见的 DOM 元素、元素位置改变、元素尺寸改变、内容改变、页面渲染器初始化、浏览器窗口尺寸改变;而有些改变会触发整个页面的重排,如:当滚动条出现时;
由于每次重排都产生计算消耗,大多数浏览器通过队列化修改并批量执行来优化重排过程,但可能会无意间强制刷新队列并要求计划任务立刻执行:获取布局信息的操作会导致列队刷新,比如:

以上属性和方法需要返回最新的布局信息,因此浏览器不得不执行渲染列队中的“待处理变化”并触发重排以返回正确的值;
在修改样式的过程中,最好避免使用上面列出的属性,它们都会刷新渲染队列,即使你是在获取最近未发生改变的或者与最新改变无关的布局信息;
最小化重绘重排:合并多次对 DOM 和样式的修改,然后一次处理掉;
(1)使用 cssText 属性


(2)修改 CSS 的 class 名称(该方法适用于不依赖于运行逻辑和计算的情况)
批量修改DOM: 使元素脱离文档流——对其应用多重改变——把元素带回文档中(基本思路);




(1)通过改变 display 属性,临时从文档中移除,然后再恢复它;

(2)在文档之外创建并更新一个文档片断,然后把它附加到原始列表中。文档片断是个轻量级的 document 对象,它的设计初衷就是为了完成这类任务——更新和移动节点。文档片断的一个便利的语法特性是当你附加一个片断到节点中时,实际上被添加的是该片断的子节点,而不是片断本身。

(3)为需要修改的节点创建一个备份,然后对副本进行操作,一旦操作完成,就用新的节点替代旧的节点;

推荐使用文档碎片;
缓存布局信息:浏览器尝试通过队列化修改和批量执行的方式最小化重排次数。当查询布局信息时,如获取偏移量(offsets)、滚动位置(scroll values)或计算出的样式值(computedstyle values)时,浏览器为了返回最新值,会刷新队列并应用所有变更。最好的做法是尽量减少布局信息的获取次数,获取后把它赋值给局部变量,然后再操作局部变量;
让元素脱离文档流:
使用以下步骤可以避免页面中的大部分重排:
1. 使用绝对位置定位页面上的动画元素,将其脱离文档流;
2. 让元素动起来。当它扩大时,会临时覆盖部分页面。但这只是页面一个小区域的重绘过程,不会产生重排并重绘页面的大部分内容。
3. 当动画结束时恢复定位,从而只会下移一次文档的其他元素。
IE中大量使用:hover该css伪选择器会降低性能,避免表格或很长的列表中使用;
总结:
1. 最小化 DOM 访问次数,尽可能在Javascript 端处理;
2. 如果需要多次访问某个 DOM 节点,请使用局部变量存储它的引用;
3. 小心处理 HTML 集合,因为它实时连系着底层文档。把集合的长度缓存到一个变量中,并在迭代中使用它。如果需要经常操作集合,建议把它拷贝到一个数组中;
4. 如果可能的话,使用速度更快的 API,比如 querySelectorAll() 和 firstElementChild;
5. 留意重绘(repaint)和重排(reflow),批量修改样式时,“离线”操作 DOM 树,使用缓存,并减少访问布局信息的次数;
6. 动画中使用绝对定位,使用拖放代理(脱离文档流——动画展示——回归文档流——只会下移一次文档中其他元素);
7. 使用事件委托(子委托父)来减少事件处理器的数量;
4. 算法和流程控制:
(1)循环:四种循环方式:for、while、do...while、for in;其中for in的速度是最慢的,其他三个差不多;或使用以下方法:
var props = ["prop1", "prop2"], i = 0; while (i < props.length) { process(object[props[i++]]); }
提升循环性能,两个主要可选因素:每次迭代处理的事务;迭代的次数;
通过减少这两者中的一个或者全部的时间开销,就能提升循环整体性能;
(2)循环性能:倒序循环可以略微提升性能(当排除额外操作带来的影响时):减少了与条件比较这一步,直接将数值到0时是否为false进行条件判断;
当循环复杂度为O(n)时,减少每次迭代的工作量是最有效的方法;当复杂度大于O(n),建议着重减少迭代次数;
(3)减少迭代次数:广为人知的一种限制循环迭代次数的模式:“达夫设备(Duff's Device)”;“达夫设备”的基本理念是:每次循环最多可调用8次 process()。循环的迭代次数为总数除以8。由于不是所有数字都能被8整除,变量 startAt 用来存放余数,表示第一次循环中应调用多少次 process()。如果是12次,那么第一次循环会调用 process() 4次,第二次循环调用 process() 8次,用两次循环替代了12次循环。
原始版:

进化版:

(4)基于函数的迭代:原生数组方法 forEach();方便,但仍比基于循环的迭代要慢一些,而对每个数组项调用外部方法所带来的开销是速度慢的主要原因;
(5)条件语句:
优化 if-else 的目标:最小化到达正确分支前所需判断的条件数量。
最简单方法:确保最可能出现的条件放在首位;或使用二分法把值域分成一系列的区间,然后逐步缩小范围。二分法非常适用于有多个值域需要测试的时候(如果是离散值,switch语句更合适)。
(6)查找表:js可用使用数组和普通对象来构建查找表,通过查找表访问数据比用 if-else 或 switch 快很多,特别是在条件语句数量很大的时候;

(7)递归:
递归函数的潜在问题是终止条件不明确或缺少终止条件会导致函数长时间运行,并使得用户界面处于假死状态。而且,递归函数还可能遇到浏览器的“调用栈大小限制”(call stack size limites)。
两种递归模式:函数调用自身;两个函数相互调用;
function recurse(){ recurse(); } recurse();
function first(){ second(); } function second(){ first(); } first();
定位模式错误的第一步是验证终止条件。
不过建议迭代、Memoization,或者综合两者使用。
(8)迭代: 运行一个循环比反复调用一个函数的开销要少得多。
把递归算法改为迭代实现是避免栈溢出错误的方法之一。
以下为一个递归用迭代实现的例子:
递归:


迭代:


(9)Memoization:它缓存前一个计算结果供后续计算使用,避免了重复工作。具体如下图:

总结:
1. for、while 和 do-while 循环性能特性相当,并没有一种循环类型明显快于或慢于其他类型;
2. 避免使用 for-in 循环,除非你需要遍历一个属性数量未知的对象;
3. 改善循环性能的最佳方式是减少每次迭代的运算量和减少循环迭代次数;
4. 通常来说,swich 总是比 if-else 快,但并不总是最佳解决方案;
5. 在判断条件较多时,使用查找表比 if-else 和 switch 更快;
6. 浏览器的调用栈大小限制了递归算法在 Javascript 中的应用;栈溢出错误会导致其他代码中断运行;
7. 如果你遇到栈溢出错误,可将方法改为迭代算法,或使用 Memoization 来避免重复计算;
运行的代码数量越大,使用这些策略所带来的性能提升也就越明显。
5. 字符串和正则表达式:
(1) 在大多数浏览器中,数组项合并(Array.prototype.join)比其他字符串连接方法更慢,但它却在IE7及更早版本浏览器中合并大量字符串唯一高效的途径;
(2) String.prototype.concat 比使用简单的 + 和 += 稍慢,尤其是在IE、Opera 和 Chrome 中慢的更明显。此外,尽管使用 concat 合并字符串数组与前面讨论的数组项连接类似,但它通常更慢一些(Opera 除外),并且它也潜伏着灾难性的性能问题;
(3) 正则表达式的运行效率受许多因素影响。首先,正则表达式匹配的文本千差万别,部分匹配比完全不匹配所用的时间要长;不同的浏览器对正则表达式引擎有着不同程度的内部优化;