第1篇:如何理解EventLoop——宏任务和微任务篇
宏任务(MacroTask)引入
在 JS 中,大部分的任务都是在主线程上执行,常见的任务有:
- 渲染事件
- 用户交互事件
- js脚本执行
- 网络请求、文件读写完成事件等等。
为了让这些事件有条不紊地进行,JS引擎需要对之执行的顺序做一定的安排,V8 其实采用的是一种队列的方式来存储这些任务, 即先进来的先执行。模拟如下:
bool keep_running = true; void MainTherad(){ for(;;){ //执行队列中的任务 Task task = task_queue.takeTask(); ProcessTask(task); //执行延迟队列中的任务 ProcessDelayTask() if(!keep_running) //如果设置了退出标志,那么直接退出线程循环 break; } }
这里用到了一个 for 循环,将队列中的任务一一取出,然后执行,这个很好理解。但是其中包含了两种任务队列,除了上述提到的任务队列, 还有一个延迟队列,它专门处理诸如setTimeout/setInterval这样的定时器回调任务。
上述提到的,普通任务队列和延迟队列中的任务,都属于宏任务。
微任务(MicroTask)引入
对于每个宏任务而言,其内部都有一个微任务队列。那为什么要引入微任务?微任务在什么时候执行呢?
其实引入微任务的初衷是为了解决异步回调的问题。想一想,对于异步回调的处理,有多少种方式?总结起来有两点:
- 将异步回调进行宏任务队列的入队操作。
- 将异步回调放到当前宏任务的末尾。
如果采用第一种方式,那么执行回调的时机应该是在前面所有的宏任务完成之后,倘若现在的任务队列非常长,那么回调迟迟得不到执行,造成应用卡顿。
为了规避这样的问题,V8 引入了第二种方式,这就是微任务的解决方式。在每一个宏任务中定义一个微任务队列,当该宏任务执行完成,会检查其中的微任务队列,如果为空则直接执行下一个宏任务,如果不为空,则依次执行微任务,执行完成才去执行下一个宏任务。
常见的微任务有MutationObserver、Promise.then(或.reject) 以及以 Promise 为基础开发的其他技术(比如fetch API), 还包括 V8 的垃圾回收过程。
Ok, 这便是宏任务和微任务的概念,接下来正式介绍JS非常重要的运行机制——EventLoop。
第2篇: 如何理解EventLoop——浏览器篇
干讲理论不容易理解,让我们直接以一个例子开始吧:
console.log('start');
setTimeout(() => {
console.log('timeout');
});
Promise.resolve().then(() => {
console.log('resolve');
});
console.log('end');
我们来分析一下:
- 刚开始整个脚本作为一个宏任务来执行,对于同步代码直接压入执行栈(关于执行栈,若不了解请移步之前的文章《JavaScript内存机制之问——数据是如何存储的?》)进行执行,因此先打印start和end
- setTimeout 作为一个宏任务放入宏任务队列
- Promise.then作为一个为微任务放入到微任务队列
- 当本次宏任务执行完,检查微任务队列,发现一个Promise.then, 执行
- 接下来进入到下一个宏任务——setTimeout, 执行
因此最后的顺序是:
start
end
resolve
timeout
这样就带大家直观地感受到了浏览器环境下 EventLoop 的执行流程。不过,这只是其中的一部分情况,接下来我们来做一个更完整的总结。
- 一开始整段脚本作为第一个宏任务执行
- 执行过程中同步代码直接执行,宏任务进入宏任务队列,微任务进入微任务队列
- 当前宏任务执行完出队,检查微任务队列,如果有则依次执行,直到微任务队列为空
- 执行浏览器 UI 线程的渲染工作
- 检查是否有Web worker任务,有则执行
- 执行队首新的宏任务,回到2,依此循环,直到宏任务和微任务队列都为空
最后给大家留一道题目练习:
Promise.resolve().then(()=>{ console.log('Promise1') setTimeout(()=>{ console.log('setTimeout2') },0) }); setTimeout(()=>{ console.log('setTimeout1') Promise.resolve().then(()=>{ console.log('Promise2') }) },0); console.log('start'); // start // Promise1 // setTimeout1 // Promise2 // setTimeout2
第3篇: 如何理解EventLoop——nodejs篇
nodejs 和 浏览器的 eventLoop 还是有很大差别的,值得单独拿出来说一说。
不知你是否看过关于 nodejs 中 eventLoop 的一些文章, 是否被这些流程图搞得眼花缭乱、一头雾水:
看到这你不用紧张,这里会抛开这些晦涩的流程图,以最清晰浅显的方式来一步步拆解 nodejs 的事件循环机制。
1. 三大关键阶段
首先,梳理一下 nodejs 三个非常重要的执行阶段:
-
执行
定时器回调的阶段。检查定时器,如果到了时间,就执行回调。这些定时器就是setTimeout、setInterval。这个阶段暂且叫它timer。 -
轮询(英文叫
poll)阶段。因为在node代码中难免会有异步操作,比如文件I/O,网络I/O等等,那么当这些异步操作做完了,就会来通知JS主线程,怎么通知呢?就是通过'data'、 'connect'等事件使得事件循环到达poll阶段。到达了这个阶段后:
如果当前已经存在定时器,而且有定时器到时间了,拿出来执行,eventLoop 将回到timer阶段。
如果没有定时器, 会去看回调函数队列。
- 如果队列
不为空,拿出队列中的方法依次执行 - 如果队列
为空,检查是否有setImmdiate的回调- 有则前往
check阶段(下面会说) 没有则继续等待,相当于阻塞了一段时间(阻塞时间是有上限的), 等待 callback 函数加入队列,加入后会立刻执行。一段时间后自动进入 check 阶段。
- 有则前往
- check 阶段。这是一个比较简单的阶段,直接
执行 setImmdiate的回调。
这三个阶段为一个循环过程。不过现在的eventLoop并不完整,我们现在就来一一地完善。
2. 完善
首先,当第 1 阶段结束后,可能并不会立即等待到异步事件的响应,这时候 nodejs 会进入到 I/O异常的回调阶段。比如说 TCP 连接遇到ECONNREFUSED,就会在这个时候执行回调。
并且在 check 阶段结束后还会进入到 关闭事件的回调阶段。如果一个 socket 或句柄(handle)被突然关闭,例如 socket.destroy(), 'close' 事件的回调就会在这个阶段执行。
梳理一下,nodejs 的 eventLoop 分为下面的几个阶段:
- timer 阶段
- I/O 异常回调阶段
- 空闲、预备状态(第2阶段结束,poll 未触发之前)
- poll 阶段
- check 阶段
- 关闭事件的回调阶段
是不是清晰了许多?
3. 实例演示
好,我们以上次的练习题来实践一把:
setTimeout(()=>{ console.log('timer1') Promise.resolve().then(function() { console.log('promise1') }) }, 0) setTimeout(()=>{ console.log('timer2') Promise.resolve().then(function() { console.log('promise2') }) }, 0)
这里我要说,node版本 >= 11和在 11 以下的会有不同的表现。
首先说 node 版本 >= 11的,它会和浏览器表现一致,一个定时器运行完立即运行相应的微任务。
timer1
promise1
time2
promise2
而 node 版本小于 11 的情况下,对于定时器的处理是:
若第一个定时器任务出队并执行完,发现队首的任务仍然是一个定时器,那么就将微任务暂时保存,
直接去执行新的定时器任务,当新的定时器任务执行完后,再一一执行中途产生的微任务。
因此会打印出这样的结果:
timer1
timer2
promise1
promise2
4.nodejs 和 浏览器关于eventLoop的主要区别
两者最主要的区别在于浏览器中的微任务是在每个相应的宏任务中执行的,而nodejs中的微任务是在不同阶段之间执行的。
5.关于process.nextTick的一点说明
process.nextTick 是一个独立于 eventLoop 的任务队列。
在每一个 eventLoop 阶段完成后会去检查这个队列,如果里面有任务,会让这部分任务优先于微任务执行。
第4篇: nodejs中的异步、非阻塞I/O是如何实现的?
在听到 nodejs 相关的特性时,经常会对 异步I/O、非阻塞I/O有所耳闻,听起来好像是差不多的意思,但其实是两码事,下面我们就以原理的角度来剖析一下对 nodejs 来说,这两种技术底层是如何实现的?
什么是I/O?
首先,我想有必要把 I/O 的概念解释一下。I/O 即Input/Output, 输入和输出的意思。在浏览器端,只有一种 I/O,那就是利用 Ajax 发送网络请求,然后读取返回的内容,这属于网络I/O。回到 nodejs 中,其实这种的 I/O 的场景就更加广泛了,主要分为两种:
- 文件 I/O。比如用 fs 模块对文件进行读写操作。
- 网络 I/O。比如 http 模块发起网络请求。
阻塞和非阻塞I/O
阻塞和非阻塞 I/O 其实是针对操作系统内核而言的,而不是 nodejs 本身。阻塞 I/O 的特点就是一定要等到操作系统完成所有操作后才表示调用结束,而非阻塞 I/O 是调用后立马返回,不用等操作系统内核完成操作。
对前者而言,在操作系统进行 I/O 的操作的过程中,我们的应用程序其实是一直处于等待状态的,什么都做不了。那如果换成非阻塞I/O,调用返回后我们的 nodejs 应用程序可以完成其他的事情,而操作系统同时也在进行 I/O。这样就把等待的时间充分利用了起来,提高了执行效率,但是同时又会产生一个问题,nodejs 应用程序怎么知道操作系统已经完成了 I/O 操作呢?
为了让 nodejs 知道操作系统已经做完 I/O 操作,需要重复地去操作系统那里判断一下是否完成,这种重复判断的方式就是轮询。对于轮询而言,有以下这么几种方案:
-
一直轮询检查I/O状态,直到 I/O 完成。这是最原始的方式,也是性能最低的,会让 CPU 一直耗用在等待上面。其实跟阻塞 I/O 的效果是一样的。
-
遍历文件描述符(即 文件I/O 时操作系统和 nodejs 之间的文件凭证)的方式来确定 I/O 是否完成,I/O完成则文件描述符的状态改变。但 CPU 轮询消耗还是很大。
-
epoll模式。即在进入轮询的时候如果I/O未完成CPU就休眠,完成之后唤醒CPU。
总之,CPU要么重复检查I/O,要么重复检查文件描述符,要么休眠,都得不到很好的利用,我们希望的是:
nodejs 应用程序发起 I/O 调用后可以直接去执行别的逻辑,操作系统默默地做完 I/O 之后给 nodejs 发一个完成信号,nodejs 执行回调操作。
这是理想的情况,也是异步 I/O 的效果,那如何实现这样的效果呢?
异步 I/O 的本质
Linux 原生存在这样的一种方式,即(AIO), 但两个致命的缺陷:
- 只有 Linux 下存在,在其他系统中没有异步 I/O 支持。
- 无法利用系统缓存。
nodejs中的异步 I/O 方案
是不是没有办法了呢?在单线程的情况下确实是这样,但是如果把思路放开一点,利用多线程来考虑这个问题,就变得轻松多了。我们可以让一个进程进行计算操作,另外一些进行 I/O 调用,I/O 完成后把信号传给计算的线程,进而执行回调,这不就好了吗?没错,异步 I/O 就是使用这样的线程池来实现的。
只不过在不同的系统下面表现会有所差异,在 Linux 下可以直接使用线程池来完成,在Window系统下则采用 IOCP 这个系统API(其内部还是用线程池完成的)。
有了操作系统的支持,那 nodejs 如何来对接这些操作系统从而实现异步 I/O 呢?
以文件为 I/O 我们以一段代码为例:
let fs = require('fs');
fs.readFile('/test.txt', function (err, data) {
console.log(data);
});
执行流程
执行代码的过程中大概发生了这些事情:
- 首先,fs.readFile调用Node的核心模块fs.js ;
- 接下来,Node的核心模块调用内建模块node_file.cc,创建对应的文件I/O观察者对象(这个对象后面有大用!) ;
- 最后,根据不同平台(Linux或者window),内建模块通过libuv中间层进行系统调用
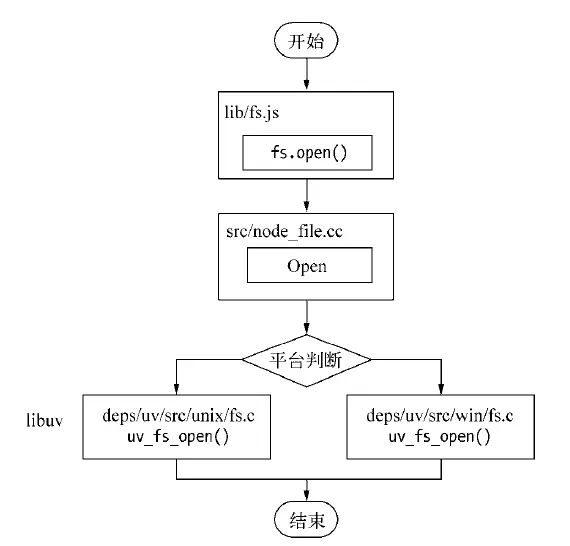
libuv调用过程拆解
重点来了!libuv 中是如何来进行进行系统调用的呢?也就是 uv_fs_open() 中做了些什么?
1. 创建请求对象
以Windows系统为例来说,在这个函数的调用过程中,我们创建了一个文件I/O的请求对象,并往里面注入了回调函数。
req_wrap->object_->Set(oncomplete_sym, callback);
req_wrap 便是这个请求对象,req_wrap 中 object_ 的 oncomplete_sym 属性对应的值便是我们 nodejs 应用程序代码中传入的回调函数。
2. 推入线程池,调用返回
在这个对象包装完成后,QueueUserWorkItem() 方法将这个对象推进线程池中等待执行。
好,至此现在js的调用就直接返回了,我们的 js 应用程序代码可以继续往下执行,当然,当前的 I/O 操作同时也在线程池中将被执行,这不就完成了异步么:)
等等,别高兴太早,回调都还没执行呢!接下来便是执行回调通知的环节。
3. 回调通知
事实上现在线程池中的 I/O 无论是阻塞还是非阻塞都已经无所谓了,因为异步的目的已经达成。重要的是 I/O 完成后会发生什么。
在介绍后续的故事之前,给大家介绍两个重要的方法: GetQueuedCompletionStatus 和 PostQueuedCompletionStatus。
-
还记得之前讲过的 eventLoop 吗?在每一个Tick当中会调用
GetQueuedCompletionStatus检查线程池中是否有执行完的请求,如果有则表示时机已经成熟,可以执行回调了。 -
PostQueuedCompletionStatus方法则是向 IOCP 提交状态,告诉它当前I/O完成了。
名字比较长,先介绍是为了让大家混个脸熟,至少后面出来不会感到太突兀:)
我们言归正传,把后面的过程串联起来。
当对应线程中的 I/O 完成后,会将获得的结果存储起来,保存到相应的请求对象中,然后调用PostQueuedCompletionStatus()向 IOCP 提交执行完成的状态,并且将线程还给操作系统。一旦 EventLoop 的轮询操作中,调用GetQueuedCompletionStatus检测到了完成的状态,就会把请求对象塞给I/O观察者(之前埋下伏笔,如今终于闪亮登场)。
I/O 观察者现在的行为就是取出请求对象的存储结果,同时也取出它的oncomplete_sym属性,即回调函数(不懂这个属性的回看第1步的操作)。将前者作为函数参数传入后者,并执行后者。 这里,回调函数就成功执行啦!
总结 :
阻塞和非阻塞I/O 其实是针对操作系统内核而言的。阻塞 I/O 的特点就是一定要等到操作系统完成所有操作后才表示调用结束,而非阻塞 I/O 是调用后立马返回,不用等操作系统内核完成操作。- nodejs中的异步 I/O 采用多线程的方式,由
EventLoop、I/O 观察者,请求对象、线程池四大要素相互配合,共同实现。
第5篇:JS异步编程有哪些方案?为什么会出现这些方案?
关于 JS 单线程、EventLoop 以及异步 I/O 这些底层的特性,我们之前做过了详细的拆解,不在赘述。在探究了底层机制之后,我们还需要对代码的组织方式有所理解,这是离我们最日常开发最接近的部分,异步代码的组织方式直接决定了开发和维护的效率,其重要性也不可小觑。尽管底层机制没变,但异步代码的组织方式却随着 ES 标准的发展,一步步发生了巨大的变革。接着让我们来一探究竟吧!
回调函数时代
相信很多 nodejs 的初学者都或多或少踩过这样的坑,node 中很多原生的 api 就是诸如这样的:
fs.readFile('xxx', (err, data) => {
});
典型的高阶函数,将回调函数作为函数参数传给了readFile。但久而久之,就会发现,这种传入回调的方式也存在大坑, 比如下面这样:
fs.readFile('1.json', (err, data) => {
fs.readFile('2.json', (err, data) => {
fs.readFile('3.json', (err, data) => {
fs.readFile('4.json', (err, data) => {
});
});
});
});
回调当中嵌套回调,也称回调地狱。这种代码的可读性和可维护性都是非常差的,因为嵌套的层级太多。而且还有一个严重的问题,就是每次任务可能会失败,需要在回调里面对每个任务的失败情况进行处理,增加了代码的混乱程度。
Promise 时代
ES6 中新增的 Promise 就很好了解决了回调地狱的问题,同时了合并了错误处理。写出来的代码类似于下面这样:
readFilePromise('1.json').then(data => {
return readFilePromise('2.json')
}).then(data => {
return readFilePromise('3.json')
}).then(data => {
return readFilePromise('4.json')
});
以链式调用的方式避免了大量的嵌套,也符合人的线性思维方式,大大方便了异步编程。
co + Generator 方式
利用协程完成 Generator 函数,用 co 库让代码依次执行完,同时以同步的方式书写,也让异步操作按顺序执行。
co(function* () { const r1 = yield readFilePromise('1.json'); const r2 = yield readFilePromise('2.json'); const r3 = yield readFilePromise('3.json'); const r4 = yield readFilePromise('4.json'); })
async + await方式
这是 ES7 中新增的关键字,凡是加上 async 的函数都默认返回一个 Promise 对象,而更重要的是 async + await 也能让异步代码以同步的方式来书写,而不需要借助第三方库的支持。
const readFileAsync = async function () { const f1 = await readFilePromise('1.json') const f2 = await readFilePromise('2.json') const f3 = await readFilePromise('3.json') const f4 = await readFilePromise('4.json') }
这四种经典的异步编程方式就简单回顾完了,由于是鸟瞰大局,我觉得知道是什么比了解细节要重要, 因此也没有展开。不过没关系,接下来,让我们针对这些具体的解决方案,一步步深入异步编程,理解其中的本质。
第6篇: 能不能简单实现一下 node 中回调函数的机制?
回调函数的方式其实内部利用了发布-订阅模式,在这里我们以模拟实现 node 中的 Event 模块为例来写实现回调函数的机制。
function EventEmitter() { this.events = new Map(); }
这个 EventEmitter 一共需要实现这些方法: addListener, removeListener, once, removeAllListener, emit。
首先是addListener:
// once 参数表示是否只是触发一次 const wrapCallback = (fn, once = false) => ({ callback: fn, once }); EventEmitter.prototype.addListener = function (type, fn, once = false) { let handler = this.events.get(type); if (!handler) { // 为 type 事件绑定回调 this.events.set(type, wrapCallback(fn, once)); } else if (handler && typeof handler.callback === 'function') { // 目前 type 事件只有一个回调 this.events.set(type, [handler, wrapCallback(fn, once)]); } else { // 目前 type 事件回调数 >= 2 handler.push(wrapCallback(fn, once)); } }
removeLisener 的实现如下:
EventEmitter.prototype.removeListener = function (type, listener) { let handler = this.events.get(type); if (!handler) return; if (!Array.isArray(handler)) { if (handler.callback === listener.callback) this.events.delete(type); else return; } for (let i = 0; i < handler.length; i++) { let item = handler[i]; if (item.callback === listener.callback) { // 删除该回调,注意数组塌陷的问题,即后面的元素会往前挪一位。i 要 -- handler.splice(i, 1); i--; if (handler.length === 1) { // 长度为 1 就不用数组存了 this.events.set(type, handler[0]); } } } }
once 实现思路很简单,先调用 addListener 添加上了once标记的回调对象, 然后在 emit 的时候遍历回调列表,将标记了once: true的项remove掉即可。
EventEmitter.prototype.once = function (type, fn) { this.addListener(type, fn, true); } EventEmitter.prototype.emit = function (type, ...args) { let handler = this.events.get(type); if (!handler) return; if (Array.isArray(handler)) { // 遍历列表,执行回调 handler.map(item => { item.callback.apply(this, args); // 标记的 once: true 的项直接移除 if (item.once) this.removeListener(type, item); }) } else { // 只有一个回调则直接执行 handler.callback.apply(this, args); } return true; }
最后是 removeAllListener:
EventEmitter.prototype.removeAllListener = function (type) { let handler = this.events.get(type); if (!handler) return; else this.events.delete(type); }
现在我们测试一下:
let e = new EventEmitter(); e.addListener('type', () => { console.log("type事件触发!"); }) e.addListener('type', () => { console.log("WOW!type事件又触发了!"); }) function f() { console.log("type事件我只触发一次"); } e.once('type', f) e.emit('type'); e.emit('type'); e.removeAllListener('type'); e.emit('type'); // type事件触发! // WOW!type事件又触发了! // type事件我只触发一次 // type事件触发! // WOW!type事件又触发了!
OK,一个简易的 Event 就这样实现完成了,为什么说它简易呢?因为还有很多细节的部分没有考虑:
- 在
参数少的情况下,call 的性能优于 apply,反之 apply 的性能更好。因此在执行回调时候可以根据情况调用 call 或者 apply。 - 考虑到内存容量,应该设置
回调列表的最大值,当超过最大值的时候,应该选择部分回调进行删除操作。 鲁棒性有待提高。对于参数的校验很多地方直接忽略掉了。
不过,这个案例的目的只是带大家掌握核心的原理,如果在这里洋洋洒洒写三四百行意义也不大,有兴趣的可以去看看Node中 Event 模块 的源码,里面对各种细节和边界情况做了详细的处理。