1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
防止过拟合方法:
(1)增加样本量
(2)正则化方法
(3)进行特征选择,减少特征数,保留重要特征
(4)特征离散化处理
正则化防止过拟合原因:

求导:
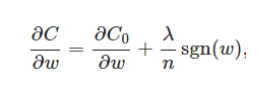
sgn(w)表示w的符号:
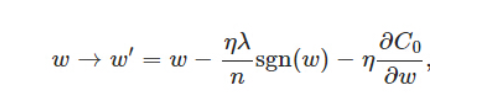
规定sgn(0)=0,当w为正时,更新后的w变小。当w为负时,更新后的w变大——因此它的效果就是让w往0靠,使网络中的权重尽可能为0,也就相当于减小了网络复杂度,防止过拟合。
2.用logiftic回归来进行实践操作,数据不限。
案例:银行用来预测客户是否将购买定期存款(变量C)
(1)银行客户的信息
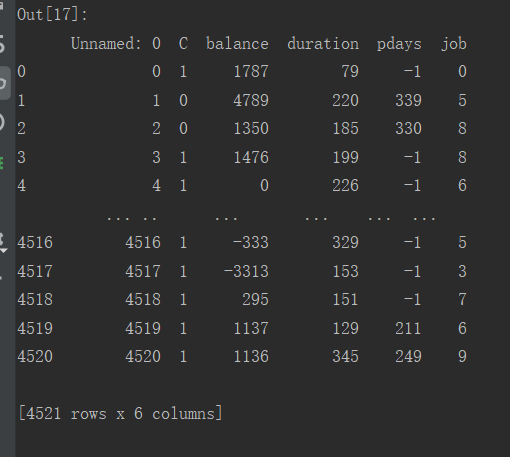
(2)逻辑回归算法:
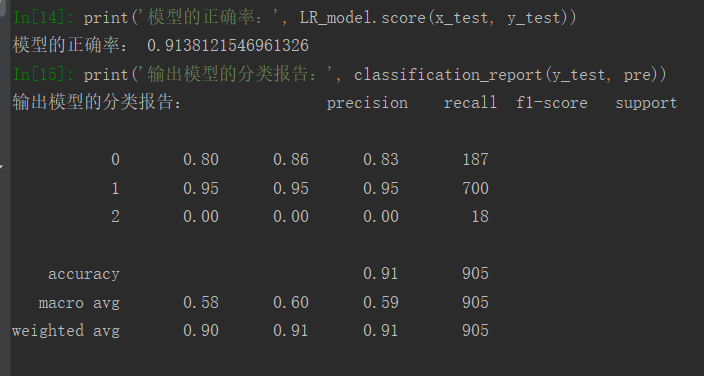
# 银行预测客户是否将购买定期存款(变量C) import pandas as pd from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report #数据读取与预处理 data = pd.read_excel('./bank_d.xls', index_col=0) x = data.iloc[:, 1:] y = data.iloc[:, 0] x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=5) #构建模型 LR_model = LogisticRegression() #训练模型 LR_model.fit(x_train, y_train) #预测模型 pre = LR_model.predict(x_test) print('模型的正确率:', LR_model.score(x_test, y_test)) print('输出模型的分类报告:', classification_report(y_test, pre))
(3)预测结果: