注释结构
JML以javadoc注释的方式来表示规格,有两种注释方式,行注释和块注释。
行注释的表示方式为 //@annotation ,块注释的方式为 /* @ annotation @*/ 。
需要注意的是,规格中的每个子句都必须以分号结尾,否则会导致JML工具无法解析。
JML表达式
-
原子表达式
esult表达式:表示一个非 void 类型的方法执行所获得的结果。
esult表达式的类型就是
方法声明中定义的返回值类型。
old( expr )表达式:用来表示一个表达式 expr 在相应方法执行前的取值。针对一个对象引用而言,只能判断引用本身是否发生变化,而不能判断引用所指向的对象实体内容是否发生变化。
ot_assigned(x,y,...)表达式:用来表示括号中的变量是否在方法执行过程中被赋值。如果没有被赋值,返回为true ,否则返回 false 。
ot_modified(x,y,...)表达式:限制括号中的变量在方法执行期间的取值未发生变化。
onnullelements( container )表达式:表示 container 对象中存储的对象不会有 null 。
forall表达式:全称量词修饰的表达式,表示对于给定范围内的元素,每个元素都满足相应的约束。
exists表达式:存在量词修饰的表达式,表示对于给定范围内的元素,存在某个元素满足相应的约束。
sum表达式:返回给定范围内的表达式的和。
max表达式:返回给定范围内的表达式的最大值。
um_of表达式:返回指定变量中满足相应条件的取值个数。
-
集合表达式
集合构造表达式:可以在JML规格中构造一个局部的集合(容器),明确集合中可以包含的元素。
的一般形式为:new ST {T x|R(x)&&P(x)},其中的R(x)对应集合中x的范围,P(x)对应x取值的约束。
-
操作符
子类型关系操作符: E1<:E2 ,如果类型E1是类型E2的子类型(sub type),则该表达式的结果为真,否则为假。
等价关系操作符: b_expr1<==>b_expr2 或者 b_expr1<=!=>b_expr2 。 <==> 比 == 的优先级要低。
推理操作符: b_expr1==>b_expr2 或者 b_expr2<==b_expr1 。对于表达式b_expr1==>b_expr2 而言,当b_expr1==false ,或者 b_expr1==true 且 b_expr2==true 时,整个表达式的值为 true 。
变量引用操作符: othing指示一个空集;everything指示一个全集。
方法规格
-
前置条件(pre-condition)
前置条件通过requires子句来表示: requires P; 。要求调用者确保P为真。 -
后置条件(post-condition)
后置条件通过ensures子句来表示: ensures P; 。方法实现者确保方法执行返回结果一定满足谓词P的要求,即确保P为真。 -
副作用范围限定(side-effects)
副作用约束子句,使用关键词 assignable 或者 modifiable 。副作用指方法在执行过程中会修改对象的属性数据或者类的静态成员数据,从而给后续方法的执行带来影响。 -
signals子句
signals子句的结构为 signals (***Exception e) b_expr ,意思是当 b_expr 为 true 时,方法会抛出括号中给出的相应异常e。还有一个简化的signals子句,即signals_only子句,后面跟着一个异常类型,调满足前置条件时抛出相应的异常。
类型规格
类型规格指针对Java程序中定义的数据类型所设计的限制规则。
-
不变式invariant
不变式(invariant)是要求在所有可见状态下都必须满足的特性,语法上定义 invariant P ,其中 P 为谓词。下面所述的几种时刻下对象o的状态都是可见状态:
对象的有状态构造方法(用来初始化对象成员变量初值)的执行结束时刻
在调用一个对象回收方法(finalize方法)来释放相关资源开始的时刻
在调用对象o的非静态、有状态方法(non-helper)的开始和结束时刻
在调用对象o对应的类或父类的静态、有状态方法的开始和结束时刻
在未处于对象o的构造方法、回收方法、非静态方法被调用过程中的任意时刻
在未处于对象o对应类或者父类的静态方法被调用过程中的任意时刻 -
状态变化约束constraint
对象的状态在变化时往往也满足一些约束,这种约束本质上也是一种不变式。JML规定,invariant只针对可见状态的取值进行约束,而是用constraint来对前序可见状态和当前可见状态的关系进行约束。
工具链
-
openJML
根据JML对实现进行静态的检查。其使用SMT Solver检查程序实现是否满足规格,目前openjml封装了四个主流的solver:z3, cvc4, simplify, yices2。
-
JMLUnitNG
根据JML自动生成对应的测试样例,用于进行单元化测试。
二、JMLUnitNG使用实例
编写被测试的类:
public class Demo { /*@ ensures esult == (num1 - num2); @ */ public static int compare(int num1, int num2) { return num1 - num2; }
对上述Demo.java,选择使用JMLUnitNG生成测试文件:
java -jar jmlunitng.jar Demo.java
生成的测试文件有Demo_JML_Test.java和Demo_InstanceStrategy.java,以下是运行结果:
[TestNG] Running: Command line suite Failed: racEnabled() Passed: constructor Demo() Passed: static compare(-2147483648, -2147483648) Passed: static compare(0, -2147483648) Passed: static compare(2147483647, -2147483648) Passed: static compare(-2147483648, 0) Passed: static compare(0, 0) Passed: static compare(2147483647, 0) Passed: static compare(-2147483648, 2147483647) Passed: static compare(0, 2147483647) Passed: static compare(2147483647, 2147483647)
三、架构设计与重构分析
作业内容概述:
第九次作业:实现一个路径管理系统。可以通过各类输入指令来进行数据的增删查改等交互。
第十次作业:在上一次作业的基础上,将内部的
Path构建为无向图结构,进行基于无向图的一些查询操作。例如计算最短路径。第十一次作业:在上一次作业的基础上,构建一个简单的
RailwaySystem地铁系统,进行一些基本的查询操作。例如计算换乘次数,最低票价,最低不满意度。
第九次作业
-
架构
容器类里面有三个HashMap: path->pathid, pathid->path, nodeid->time.
调用addPath和removePath方法的时候,会对图产生修改。我采取了动态修改node出现次数,记录在hashMap中的方法。
-
类图
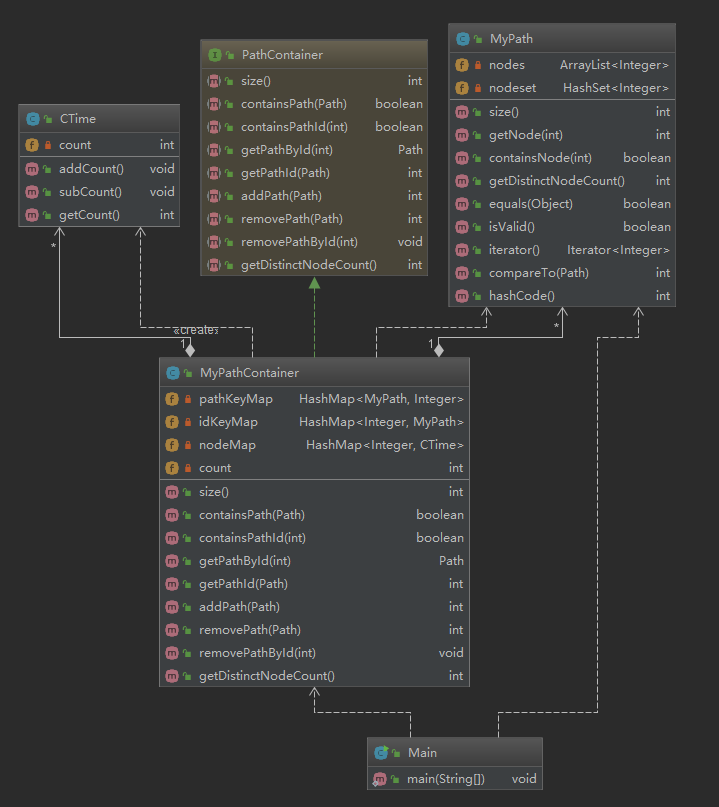

-
复杂度

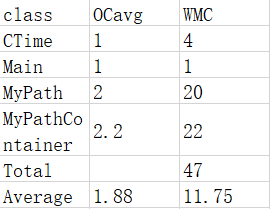


第十次作业
-
架构
存储结构:
我采用类似邻接链表的形式存储邻接矩阵。将节点封装成一个类VexNode,属性包含自己的value,和一个Arraylist<VexNode>存储相邻节点。
在PathContainer里面,用Arraylist存储不同节点。开一个HashMap存储节点的值到它在Arraylist的指数的映射。
最短路径算法:dijkstra
访问每个VexNode时,可以从内部Arraylist直接得到相邻节点,很好的支持了dij算法。
这个架构的拓展性不高,主要问题如下:
邻接矩阵通过VexNode类里面的Arraylist嵌套存储,在addPath和removePath的时候动态修改,容易出错。
dij虽然复杂度比floyd低,但是单源算法。我没有将单源+缓存机制相结合,求最短路径的时候再计算起点到其他节点的最短距离。而是在增加减少路径的时候,都重新对所有节点dij,求出一个最短距离矩阵,存储这一时刻下n*n个值。
-
类图
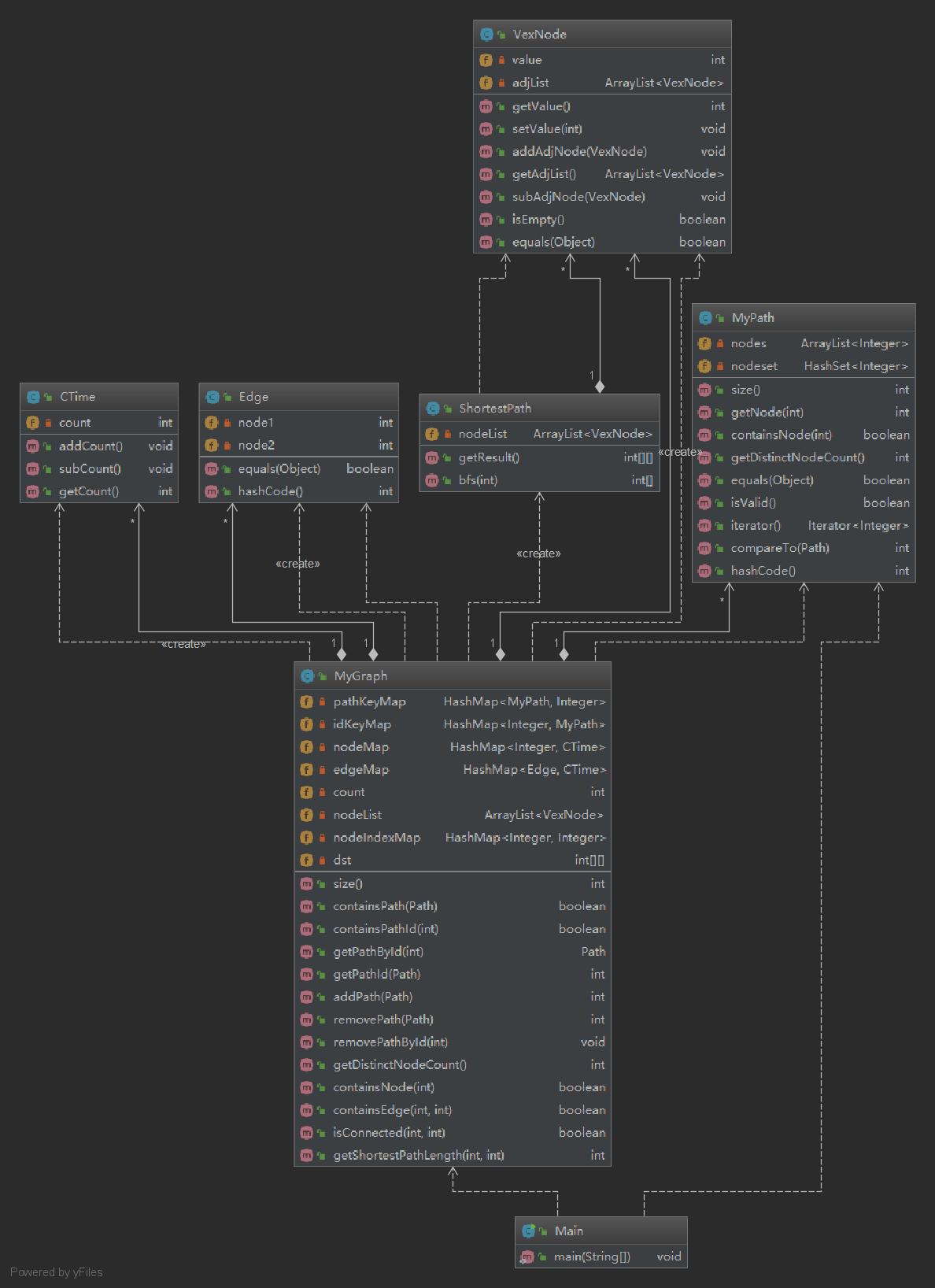

-
复杂度

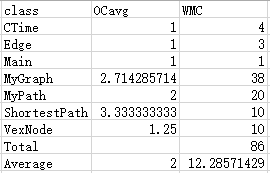


第十一次作业
-
架构
按照讨论区的拆点法进行设计:
认为不同路径上相同value的节点是不同点。为每个value的节点设置一个统一的起点和终点,起点指向所有这个value的节点(边权为0),这个value的节点都指向终点(边权为0),终点指向起点(边权为换乘代价)。同一路径上的相邻点之间有一条双向边。
存储结构:
首先进行节点映射nodeid->index(nodeid就是value),前120个index给起点,再120个node给终点,从240开始给普通节点。起点的个数其实就是pathContainer里面不同节点的个数。
嵌套Arraylist<Arraylist<Integer>>实现一个类似邻接矩阵的结构,存储有向图的边。每一行的Arraylist按照index分配给节点,存储的元素是这个节点指向的其他节点的index。另外一个嵌套Arraylist<Arraylist<Integer>>与上一个有向边的嵌套一一对应,存储边的权重。
int二维数组存储最短路径距离矩阵。再用一维数组记录是否缓存过某一个节点,实现缓存。
最短路径算法:spfa
spfa和dij都更适合稀疏图求解最短路径,floyd更适合稠密图。在这次作业中,通过尝试,发现spfa比dij有更好的时间性能。
SPFA:是 Bellman-Ford算法的队列优化算法的别称,通常用于求的单源最短路径。SPFA 最坏情况下复杂度和朴素 Bellman-Ford 相同,为 O(VE)。
Dijkstra:适用于权值为非负的图的单源最短路径,复杂度是O(N^2),用斐波那契堆的复杂度O(E+VlgV)。
-
类图
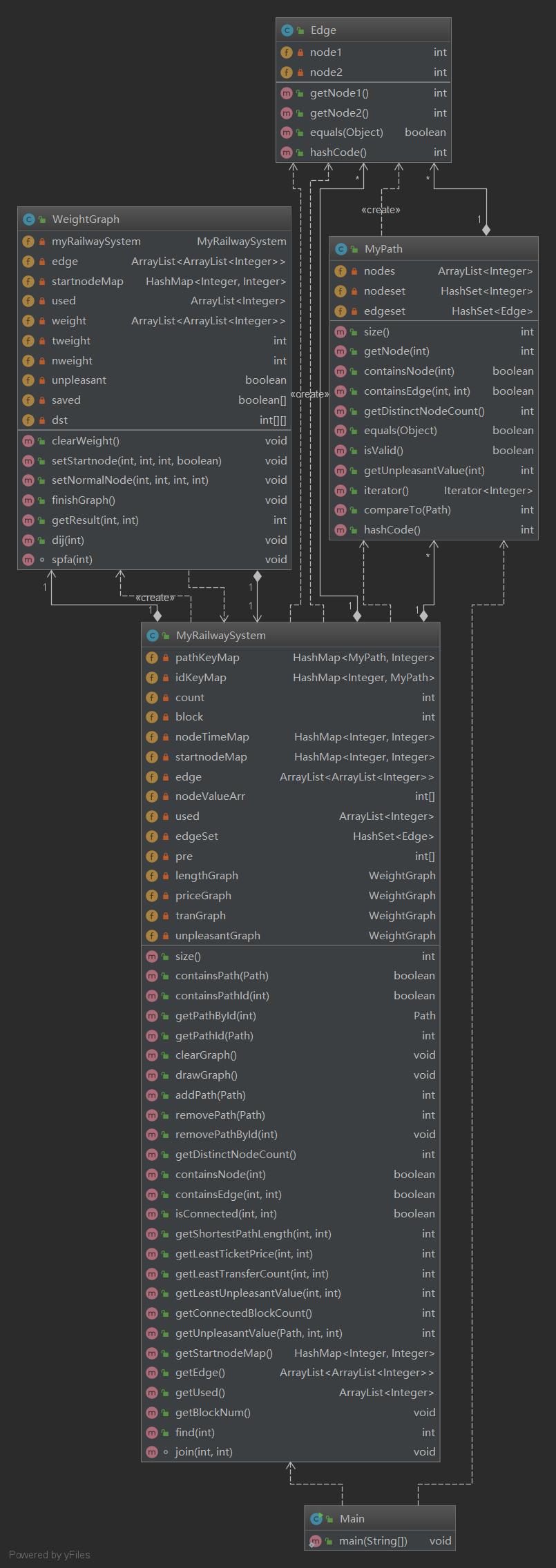

-
复杂度
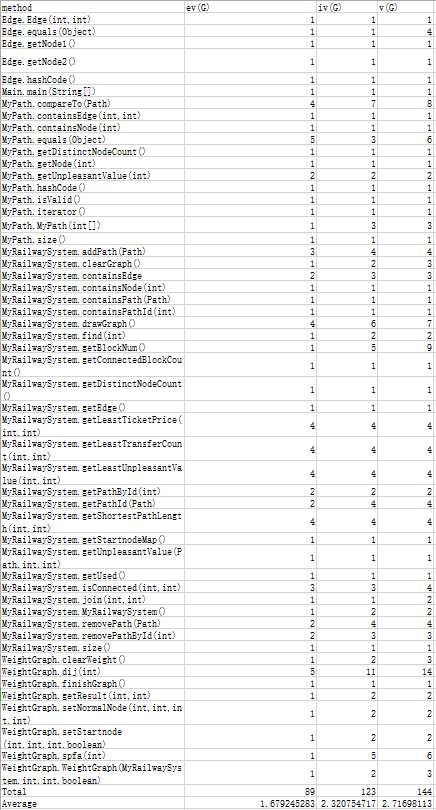
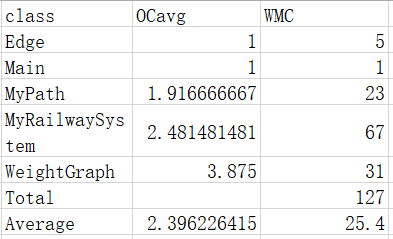


四、bug与修复
第九次作业
我发现了一个很容易被忽视的bug:两个Integer判相等不能用==,要用equals方法。数字很小的时候==能得到正确结果,但超过200会出现灵异的现象。一不注意引入这个bug是程序员的灾难,非常难de出来。
第十次作业
这次作业我践行了一句话“只要不测试,我的程序就没有bug”。本地测试不充分,导致我上交的程序携带着严重的bug。如果出现环路(for example 2 3 2),我会将2节点添加到3节点的邻接Arraylist里面两次。如果节点重复(for example 2 2 2),我会将2添加到自己的邻接Arraylist里面。
第十一次作业
当我发现别人只需要跑8秒的压力测试集我跑了10分钟,就知道自己选错了架构。
我原先超时的版本,最致命的问题是使用了没有堆优化的dij,而且没有缓存(即在被问起的时候再求某点最短路径,并将这点标志为已缓存)。拆点后图变得很庞大,在addPath时遍历求解每个节点的距离数组,时间复杂度接近n^3。bug修复阶段我换成了spfa算法,还将有权图封装成一个独立的类来更简单的实现缓存。
我没有给相同value的节点设置“汇点”,而是让它们之间形成完全图使得彼此能相互到达。
我还沿用了第十次作业的VexNode存储邻接节点,这样递归不如用嵌套Arraylist快速。
经过一个周末的重写(“重构”已经不能描述我的改动之大了),我终于在8秒内跑完了那个测试集。菜鸡落泪orz
五、规格撰写与理解的心得体会
JML可以代替自然语言,将代码行为描述的更加精准。但是有时,一句自然语言就能描述清楚的行为,JML写的很冗长。当描述一个较复杂的行为时,撰写JML可能需要花比代码很长的时间,甚至多实现一些底层的函数来辅助表述。像第十一次作业中“换乘”这个概念,JML写的既巧妙又抽象,非常佩服写出这个规格的老师。