GitHub仓库
计算模块接口的设计与实现过程
步骤
- 运用cppjieba对文本进行分词。
- 对分词结果进行降噪处理
- 计算余弦相似度
理论知识
一、词袋模型
文档内容中出现频率越高的词项,越能描述该文档。因此可以统计每个词项在每篇文档中出现的次数,即词项频率,记为
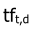
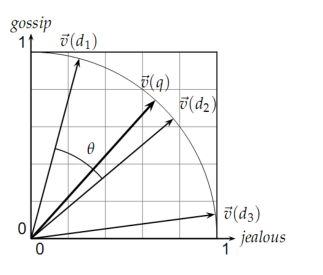
二、余弦相似度
对于统计好词项频率的文本,可以为分别生成n维向量。两个文本的向量之间形成一个夹角,如果夹角为0度,意味着方向相同、线段重合;如果夹角为90度,意味着形成直角,方向完全不相似;如果夹角为180度,意味着方向正好相反。因此,我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。
余弦相似度计算方法
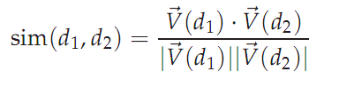
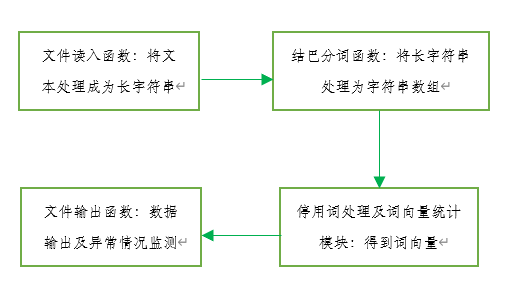
函数模块
一、文件处理模块
- 运用cppjieba对文件内容进行分词处理
- 运用停用词表对分词结果降噪
二、文本相似度计算
- 对处理后的文件进行词向量统计
- 计算余弦相似度,用余弦相似度近似替代文本相似度
测试
测试代码
string thefiles[]={"orig_0.8_add.txt",
"orig_0.8_del.txt",
"orig_0.8_dis_1.txt",
"orig_0.8_dis_3.txt",
"orig_0.8_dis_7.txt",
"orig_0.8_dis_10.txt",
"orig_0.8_dis_15.txt",
"orig_0.8_mix.txt",
"orig_0.8_rep.txt"};
string path;
string path0="main.exe sim_0.8/orig.txt sim_0.8/";
string path2=" result.txt";
for(int i=0;i<9;i++){
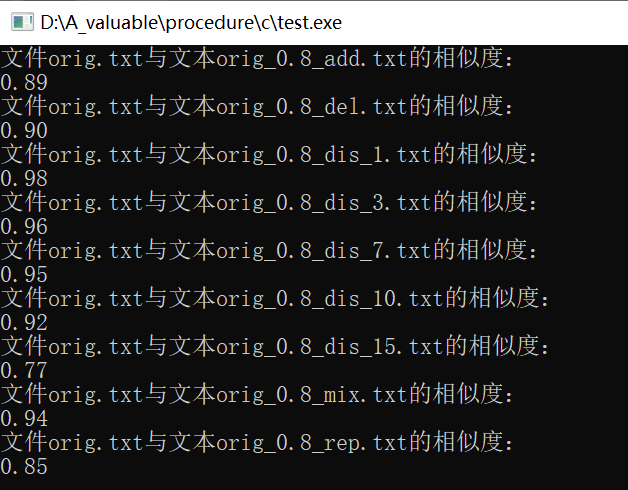
cout<<"文件orig.txt与文本" <<thefiles[i]<< "的相似度:"<<endl;
path=path0+thefiles[i]+path2;
system(path.c_str());
cout<<endl;
}
测试结果
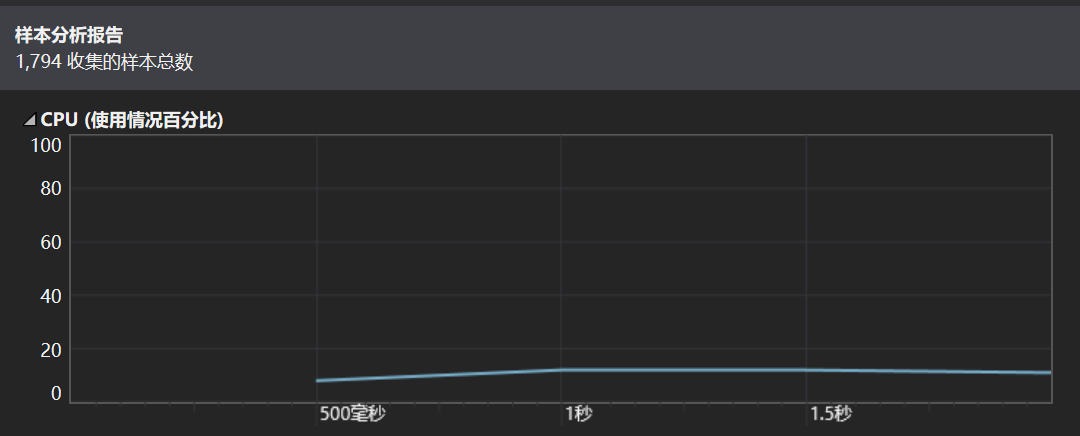
性能分析
计算模块部分异常处理
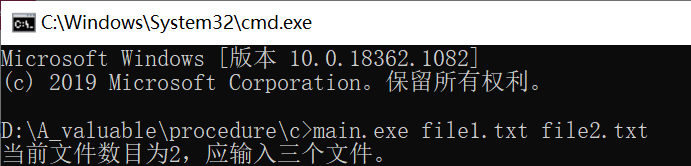
一、输入文件数目不对
处理方案:提示当前输入文件参数数目。
二、无法找到文件或文件打开失败
处理方案:提示文件打开失败。

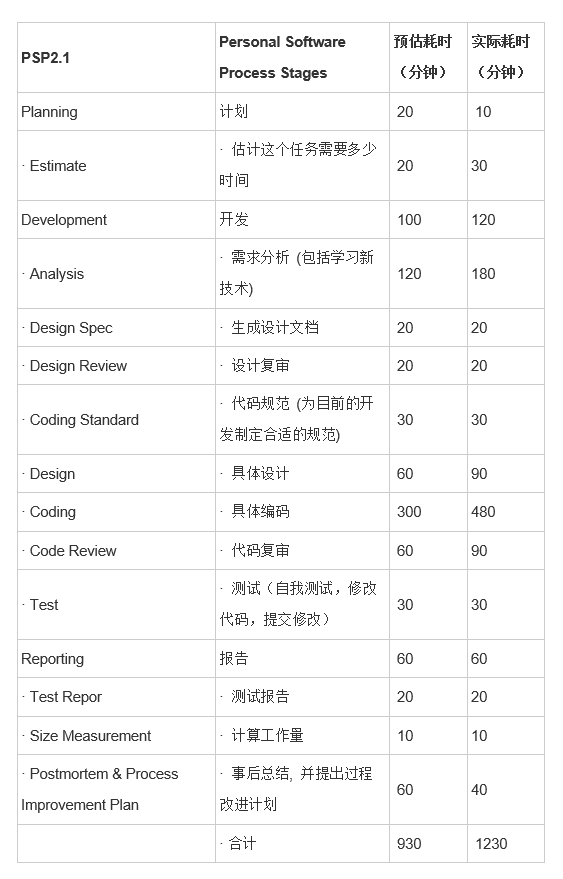
PSP表格
个人总结
这次作业一边百度一边写,期间学完这个又有了另一个等着学,学海无涯呐!