作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
本案例主要分析在豆瓣爬取的短评数据,数据字段包括地址、评论时间、评论内容、评价程度、用户名和投票数6个属性值,将数据上传到hdfs的hive数据仓库中进行简要分析。
一、建立一个运行本案例的目录bigdatacase、dataset:


上传并查看文件

二、预处理文件,将csv生成txt文件:
1、删除第一行字段:
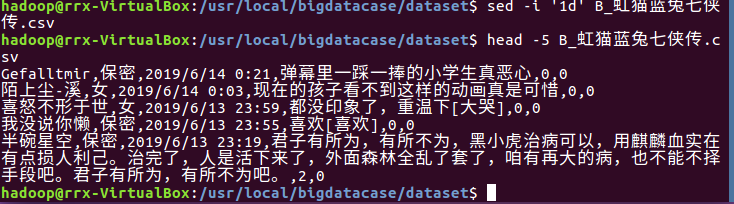
2、预处理字段:

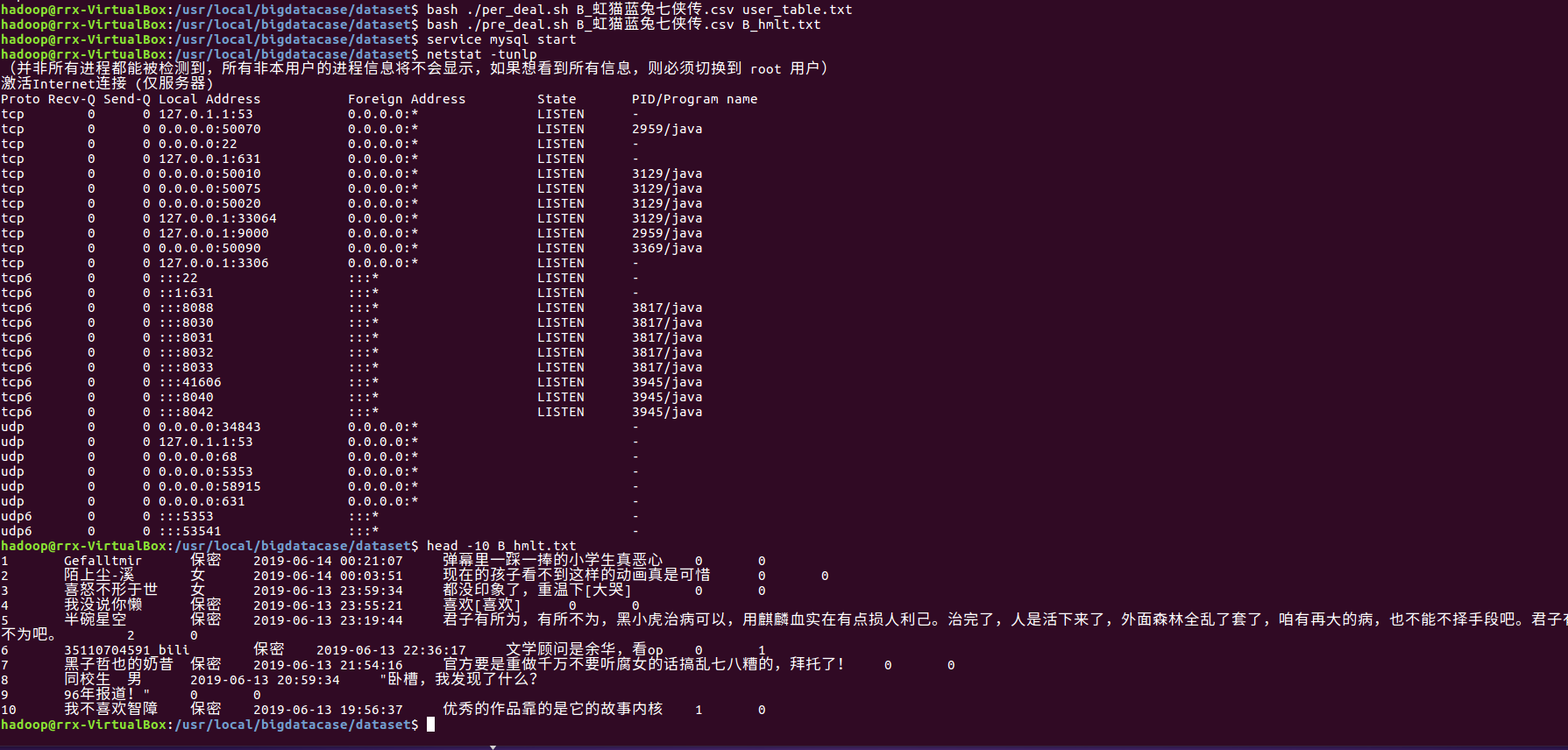
三、将文本文件上传到hive:
1、启动hdfs:

2、在HDFS上建立/bigdatacase/dataset文件夹,将文件上传:


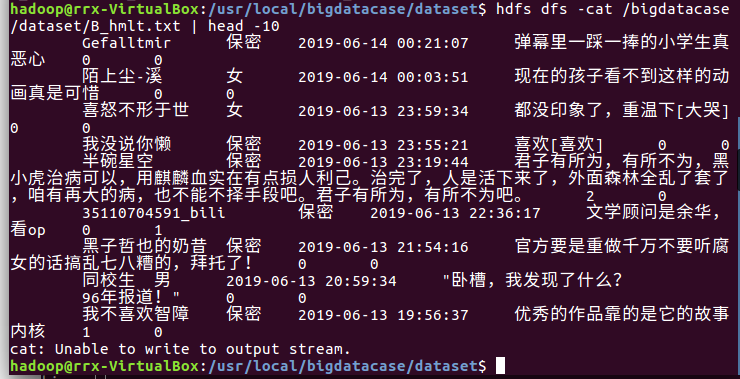

3、启动mysql:
4、在hive中创建数据库dblab:
5、在把hdfs中的“/bigdatabase/dataset”目录下的数据加载到了数据仓库的hive中的,在hive中查看数据,查找表的前10条记录:
四、Hive数据分析:
1、查询不重复的用户名:
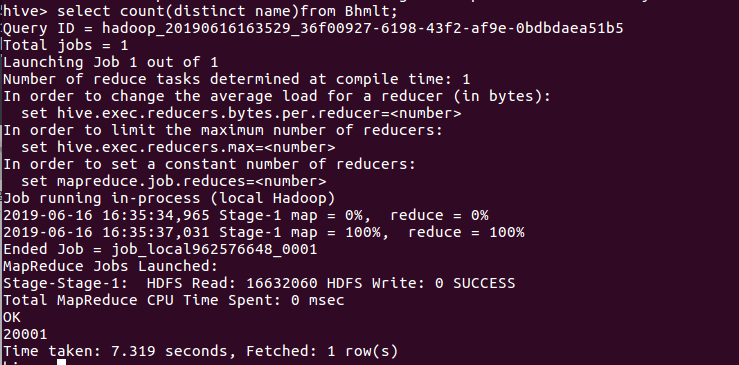
通过distinct username 查询出不重复的用户名有多少1871个,总数量2000左右,说明大部分还是比较真实的,但也有部分刷评论的。
2、查询前10被点赞情况: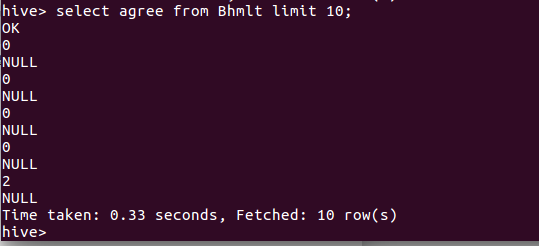
3、查询评价:
4、查询回复的数量: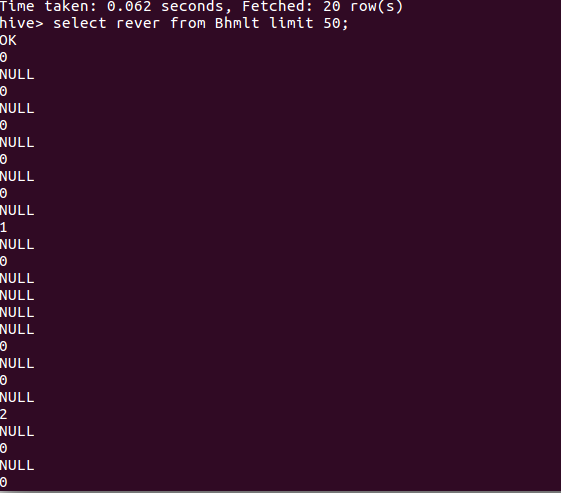
5、查询数据一共有多少条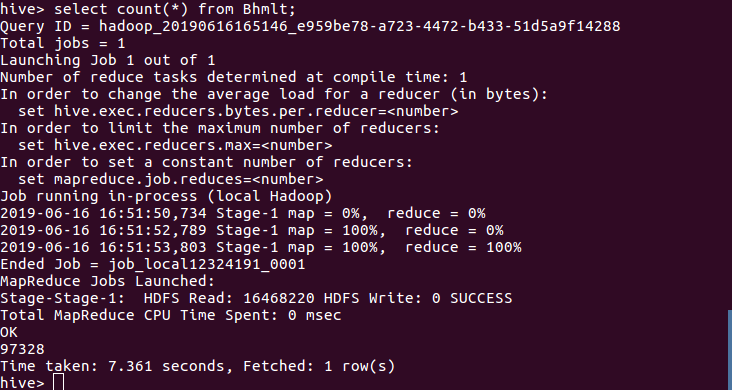
6、查询name属性是否相同
五、总结
通过本案例,了解hdfs和hive数据仓库的大数据分析基本的原理和操作,在大量数据处理方面,hadoop在数据容纳和分析方面有着先天的优势,步骤和分析的数据还要进一步熟悉,步骤出错很容易引起一大串问题,爬取的数据要有有意义。