2.1 Data Acquisition
一、本地数据获取 Local Data Acquisition:打开后才能进行读写;读文件、写文件;文件处理完毕要关闭文件(因为Python回缓存写入数据,若异常崩溃则无法写入)。
1 文件的打开 file_obj=open(filename,mode='r',buffering=-1):filename为路径和名称mode为可选参数,默认值为r;buffering也为可选参数,默认值为-1(0代表不缓冲,1或大于1的值表示缓冲一行或制定缓冲区大小)
>>>f1=open(r'd:\infile.text')读数据默认缓冲大大小(为了读数据快一些请使用缓冲吧)
>>>f2=open(r'd:\outfile.txt','w')
>>>f3=open('frecord.csv','ab',0)

返回值:open()函数返回一个文件(file)对象;文件对象可迭代;有关闭方法和许多读写相关的方法/函数,
—f.read(),f.write(),f.readines(),f.writelines()
—f.close()
—f.seek()
2 写文件—f.write():将一个字符串写入文件,
file_obj.write(str)
f=open(r'd:python�01.txt','w')
f.write('wang shou fei ,hello!')
f.close()
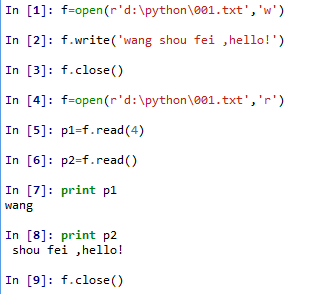
3 读文件-f.read()
file_obj.read(size)-从文件中至多读出size字节数据,返回一个字符串;
file_obj.read()-读文件直到文件结束,返回一个字符串
eg.
4 其他读写函数
file_obj.readlines()

file_obj.readline()
file_obj.writelines()
5 文件读写例子:将文件companies.txt的字符串前加上1、2、3、···后写到另一个文件scompanies.txt中
f1=open(r'd:companies.txt') cNames=f1.readlines() for i in range(0,len(cNames)): cNames[i]=str(i+1)+''+cNames[i] f1.close() f2=open(r'd:scompanies.txt','w') f2.writelines(cNames) f2.close()
错误示范

正确示范:
file_obj.seek(offset,whence=0):在文件红移动文件指针,从whence(0表示文件头部,1表示当前位置,2表示文件尾部)偏移offset个字节;whence参数可选,默认值为0。

6 标准文件:当程序启动后,以下三种标准文件有效:stdin标准输入,stdout标准输出,stderr标准错误

二、网络数据获取:抓取网页,解析网页内容;urllib,urllib2,httplib,httplib2
利用urllib库获取网络数据:
urllib.urlopen()
f.read(),f.readline(),f.readlines(),f.close()等方法
利用urllib库获取yahoo财经数据 Obtain Yahoo financial data using urllib libraries
import urllib2 import re dStr = urllib2.urlopen('https://hk.finance.yahoo.com/q/cp?s=%5EDJI').read() m = re.findall('<tr><td class="yfnc_tabledata1"><b><a href=".*?">(.*?)</a></b></td><td class="yfnc_tabledata1">(.*?)</td>.*?<b>(.*?)</b>.*?</tr>', dStr) if m: print m print ' ' print len(m) else: print 'not match'