最近再hue 集群查询任务经常失败,经过几天的观察,终于找到原因,报错如下
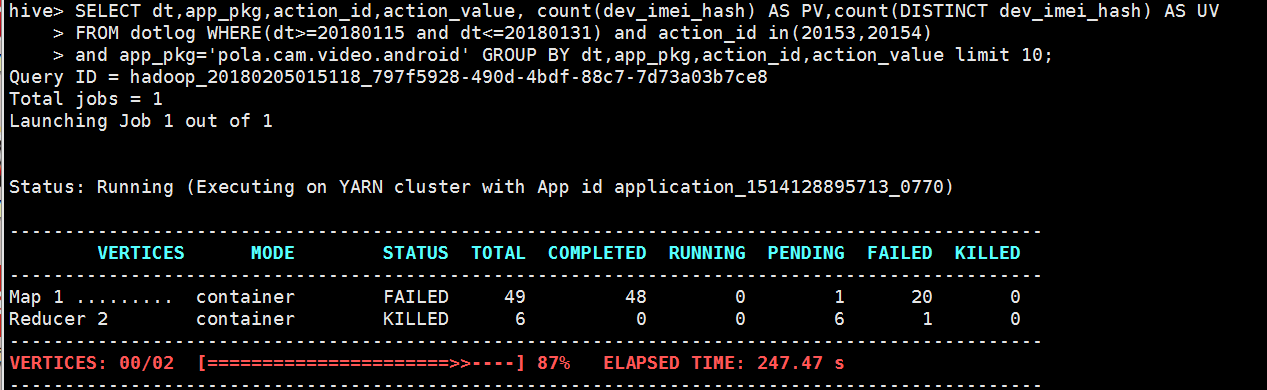
Status: Failed
Vertex failed, vertexName=Map 1, vertexId=vertex_1514128895713_0770_1_00, diagnostics=[Task failed, taskId=task_1514128895713_0770_1_00_000006, diagnostics=[TaskAttempt 0 failed, info=[Container container_1514128895713_0770_01_000008 finished with diagnostics set to [Container failed, exitCode=-100. Container released on a *lost* node]], TaskAttempt 1 failed, info=[Container container_1514128895713_0770_01_000026 finished with diagnostics set to [Container failed, exitCode=-100. Container released on a *lost* node]], TaskAttempt 2 failed, info=[Container container_1514128895713_0770_01_000036 finished with diagnostics set to [Container failed, exitCode=-100. Container released on a *lost* node]], TaskAttempt 3 failed, info=[Container container_1514128895713_0770_01_000042 finished with diagnostics set to [Container failed, exitCode=-100. Container released on a *lost* node]]], Vertex did not succeed due to OWN_TASK_FAILURE, failedTasks:1 killedTasks:0, Vertex vertex_1514128895713_0770_1_00 [Map 1] killed/failed due to:OWN_TASK_FAILURE]
Vertex killed, vertexName=Reducer 2, vertexId=vertex_1514128895713_0770_1_01, diagnostics=[Vertex received Kill while in RUNNING state., Vertex did not succeed due to OTHER_VERTEX_FAILURE, failedTasks:0 killedTasks:6, Vertex vertex_1514128895713_0770_1_01 [Reducer 2] killed/failed due to:OTHER_VERTEX_FAILURE]
DAG did not succeed due to VERTEX_FAILURE. failedVertices:1 killedVertices:1
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.tez.TezTask. Vertex failed, vertexName=Map 1, vertexId=vertex_1514128895713_0770_1_00, diagnostics=[Task failed, taskId=task_1514128895713_0770_1_00_000006, diagnostics=[TaskAttempt 0 failed, info=[Container container_1514128895713_0770_01_000008 finished with diagnostics set to [Container failed, exitCode=-100. Container released on a *lost* node]], TaskAttempt 1 failed, info=[Container container_1514128895713_0770_01_000026 finished with diagnostics set to [Container failed, exitCode=-100. Container released on a *lost* node]], TaskAttempt 2 failed, info=[Container container_1514128895713_0770_01_000036 finished with diagnostics set to [Container failed, exitCode=-100. Container released on a *lost* node]], TaskAttempt 3 failed, info=[Container container_1514128895713_0770_01_000042 finished with diagnostics set to [Container failed, exitCode=-100. Container released on a *lost* node]]], Vertex did not succeed due to OWN_TASK_FAILURE, failedTasks:1 killedTasks:0, Vertex vertex_1514128895713_0770_1_00 [Map 1] killed/failed due to:OWN_TASK_FAILURE]Vertex killed, vertexName=Reducer 2, vertexId=vertex_1514128895713_0770_1_01, diagnostics=[Vertex received Kill while in RUNNING state., Vertex did not succeed due to OTHER_VERTEX_FAILURE, failedTasks:0 killedTasks:6, Vertex vertex_1514128895713_0770_1_01 [Reducer 2] killed/failed due to:OTHER_VERTEX_FAILURE]DAG did not succeed due to VERTEX_FAILURE. failedVertices:1 killedVertices:1
分析:
taskId=task_1514128895713_0770_1_00_000006 失败了几次,失败的原因是container被高优先级的任务抢占了。而task最大的失败次数默认是4.当集群上的任务比较多时,比较容易出现这个问题。还有一个原因我认为container设置的内存太小,我这是1.5G 不过没有修改,我设置了以下参数就解决了:
解决方案:
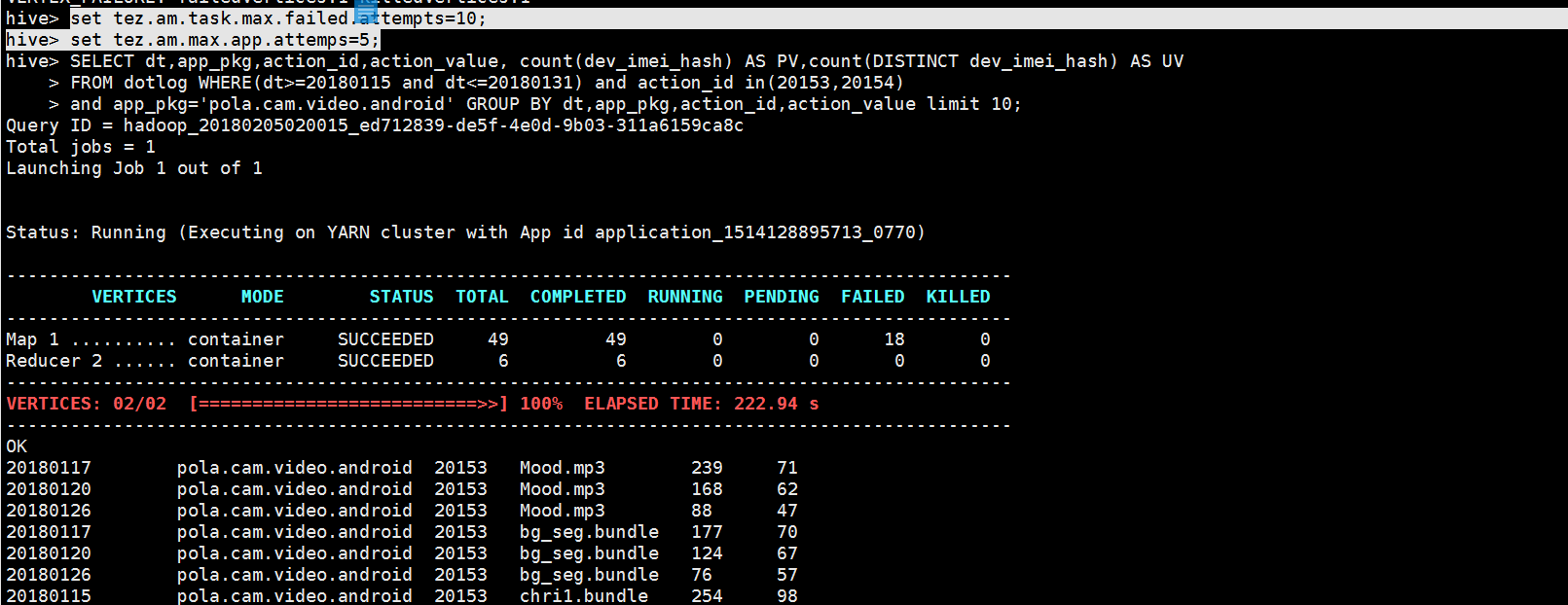
问题解决了,希望帮到你