很多时候我们需要通过筛选条件同时对表进行 更新,插入,删除 等操作。这样如果我们单一的去操作表会显得很麻烦,下面会说到这个merge into 的用法会极大的优化我们操作表的时间和代码量。
举例,先新建2个表:
create table book( id number, name varchar(64), price number, primary key(id) ) create table pbook as select * from book delete pbook
这里create table A as (select....) 不熟悉的人可以记一下,以后可以常用,相当于备份一个表,既有表结构也有数据。分别插入不同的数据,如下
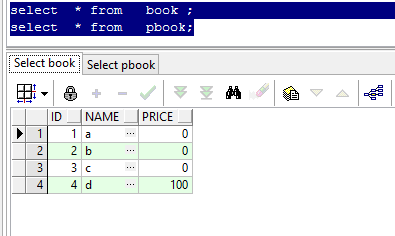

现在我们对表book (下面称a表)进行操作, 需要同时更新a表价格为0的数据,插入 a表没有的数据,且通过条件过滤掉b表的价格大于1000的数据的极大数据。
merge into book a using pbook b on (a.id=b.id) when matched then update set a.price=b.price*0.8 where a.price=0 delete where (b.price>1000) when not matched then insert (a.id,a.name,a.price) values (b.id,b.name,b.price);
说明:when matched then 是判断条件,即如果a表中 a.price没有等于0的就不会去执行更新语句了,后面的delete where 也是在更新中过滤某些数据。没有则可以不加
a表结果如下:
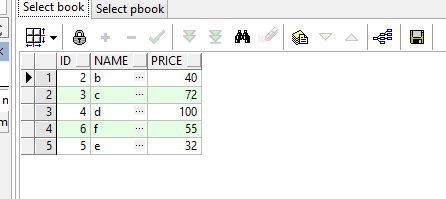
该语句做到了:1、删除id=1的数据,2、更新了2,3的数据。3、插入了4,5两条新数据。4、id为4的数据不变
merge into是dml语句,需要进行rollback和commit 结束事物
发现:经测试插入数据顺序为无序(没有规律,如有人发现规律请指教)。