使用requests , lxml ,xpath进行爬取并写入了TXT(也可以存入数据库)。参考博客:https://blog.csdn.net/yexing_cts/article/details/80855059
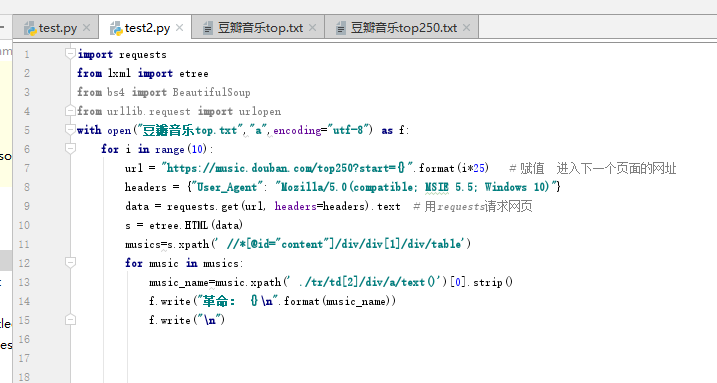
话不多说,直接上源码:
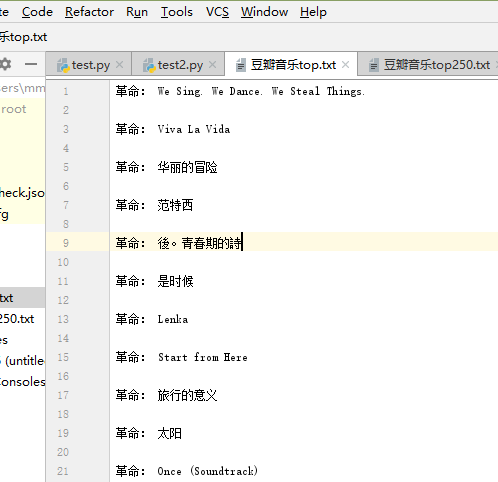
运行结果:
使用requests , lxml ,xpath进行爬取并写入了TXT(也可以存入数据库)。参考博客:https://blog.csdn.net/yexing_cts/article/details/80855059
话不多说,直接上源码:
运行结果: