揭秘HBase:
-----------------------------------------------------------------
安装HBase:
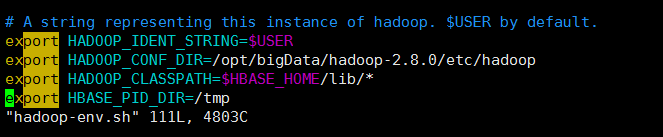
为了Hadoop集成HBase不出现问题,修改hadoop的hadoop.env.sh文件
export HADOOP_IDENT_STRING=$USER
export HADOOP_CONF_DIR=/opt/bigData/hadoop-2.8.0/etc/hadoop
export HADOOP_CLASSPATH=$HBASE_HOME/lib/*
export HBASE_PID_DIR=/tmp
1):将HBase压缩包上传到master机器上 点我下载HBase包
2):切换到指定目录解压安装包

[root@admin tools]# tar -zxvf hbase-1.3.1-bin.tar.gz -C ../bigData/hbase-1.3.1/
3):进入解压目录的conf文件夹,修改hbase-site.xml文件
<property>
<name>hbase.rootdir</name>
<value>hdfs://admin:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.admin</name>
<value>admin</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>admin,admin-01,admin-02</value>
</property>
4):修改regionservers文件(把原来的 localhost 删掉,添加上两个子机器的名称)

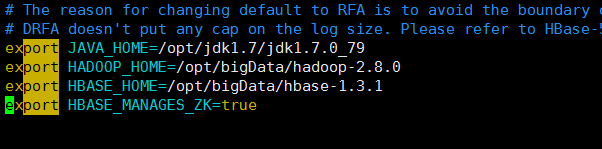
5):修改hbase-env.sh文件(根据自身环境路径配置)
export JAVA_HOME=/opt/jdk1.7/jdk1.7.0_79
export HADOOP_HOME=/opt/bigData/hadoop-2.8.0
export HBASE_HOME=/opt/bigData/hbase-1.3.1
export HBASE_MANAGES_ZK=true
6):配置HBase的环境变量
export HBASE_HOME=/opt/bigData/hbase-1.3.1
export PATH=$HBASE_HOME/bin:$PATH

7):将配置好的hbase复制到子机器当中
scp -r /opt/bigData/hbase-1.3.1 root@admin-01:/opt/bigData/
scp -r /opt/bigData/hbase-1.3.1 root@admin-02:/opt/bigData/
8):配置子机器的HBase环境变量
9):切换到admin机器侠HBase安装目录下的bin文件夹启动HBase(保证Hadoop集群先启动)
[root@admin conf]# cd /opt/bigData/hbase-1.3.1/bin/
[root@admin bin]# ./start-hbase.sh
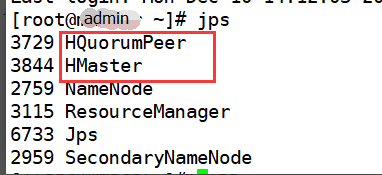
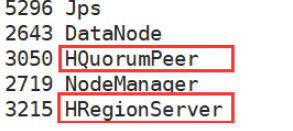
分别在两台子机器上查询后台服务:()
10):在master主机上运行hbase shell

11):启动成功查看界面(ip地址:16010)
