众所周知,solr与es的最大区别是,solr可以对pdf,txt,doc等文件生成索引
那我们如何添加文件索引呢?
步骤1.添加core,取名暂且为 coreFile 在bin下执行命令 ./solr create -c coreFile
步骤2.准备要搜索的文件
步骤3.添加搜索的数据源 注意,此时使用的class是solr.DataimportHandler
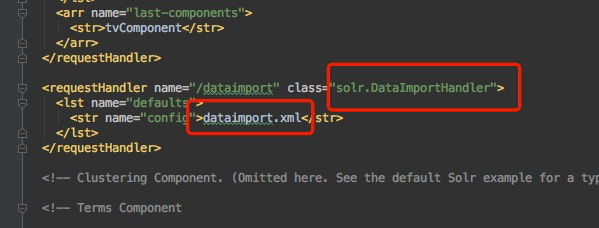
步骤4.添加数据源文件,注意更换 baseDir为你自己的文件路径
<?xml version="1.0" encoding="UTF-8" ?> <dataConfig> <dataSource type="BinFileDataSource"/> <document> <entity name="file" processor="FileListEntityProcessor" dataSource="null" baseDir="/Users/sunpeizhen/Desktop/file" fileName=".(doc)|(pdf)|(docx)|(txt)|(csv)|(json)|(xml)|(pptx)|(pptx)|(ppt)|(xls)|(xlsx)" rootEntity="false"> <field column="file" name="id"/> <field column="fileSize" name="fileSize"/> <field column="fileLastModified" name="fileLastModified"/> <field column="fileLastModified" name="fileLastModified"/> <field column="fileAbsolutePath" name="fileAbsolutePath"/> <entity name="pdf" processor="TikaEntityProcessor" url="${file.fileAbsolutePath}" format="text"> <field column="Author" name="author" meta="true"/> <!-- in the original PDF, the Author meta-field name is upper-cased, but in Solr schema it is lower-cased --> <field column="title" name="title" meta="true"/> <field column="text" name="text"/> </entity> </entity> </document> </dataConfig>
步骤5.添加字段索引
在managed-schema 文件下添加字段索引:
<field name="title" type="text_cn" indexed="true" stored="true"/> <field name="text" type="text_cn" indexed="true" stored="true" omitNorms ="true"/> <field name="author" type="string" indexed="true" stored="true"/> <field name="fileSize" type="plong" indexed="true" stored="true"/> <field name="fileLastModified" type="pdate" indexed="true" stored="true"/> <field name="fileAbsolutePath" type="string" indexed="true" stored="true"/>
步骤6.添加中文分词
solr默认没有开启中文分词,许压迫我们添加中文分词的配置
在managed-schema 文件下添加:
<fieldType name="text_cn" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/> </analyzer> </fieldType>
此时中文分词开启。
文件搜索已经添加完毕
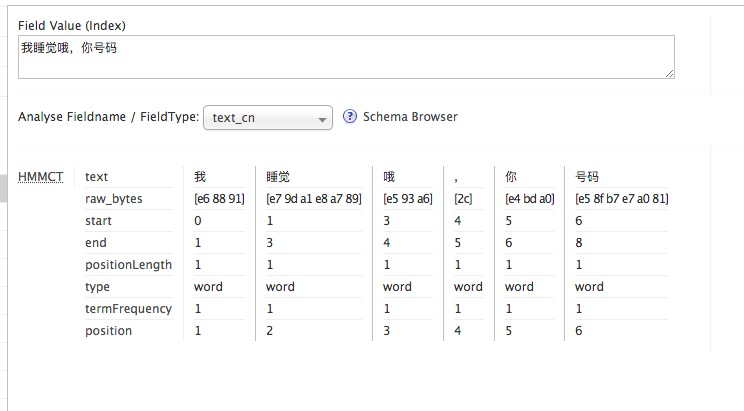
测试中文分词:
我们添加的分词名称为 text_cn
进入solrUI操作界面,选择coreFIle,点击 Analys

输入中文语句,进行分词,测试如下:
文件搜索:
点击query,进入查询页面。 可以看到文件内容也已经可以搜索到
