1、容器基本概念
容器其实就是一种特殊的进程,容器是一个 ‘单进程’模型。
Namespace :隔离 Namespace 技术实际上修改了应用进程看待整个计算机“视图”,即它的“视线”被操作系统做了限制,只能“看到”某些指定的内容
Linux Cgroups :限制 它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
通过修改 配置文件来限制某个进程的可使用的资源
可以看到,在 /sys/fs/cgroup 下面有很多诸如 cpuset、cpu、 memory 这样的子目录,也叫子系统。这些都是我这台机器当前可以被 Cgroups 进行限制的资源种类。而在子系统对应的资源种类下,你就可以看到该类资源具体可以被限制的方法。比如,对 CPU 子系统来说,我们就可以看到如下几个配置文件,这个指令是:
ls /sys/fs/cgroup/cpu
cgroup.clone_children cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release
cgroup.procs cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks
如果熟悉 Linux CPU 管理的话,你就会在它的输出里注意到 cfs_period 和 cfs_quota 这样的关键词。这两个参数需要组合使用,可以用来限制进程在长度为 cfs_period 的一段时间内,只能被分配到总量为 cfs_quota 的 CPU 时间。
-1代表不限制
$ cat /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us -1 $ cat /sys/fs/cgroup/cpu/container/cpu.cfs_period_us 100000
接下来,我们可以通过修改这些文件的内容来设置限制。
比如,向 container 组里的 cfs_quota 文件写入 20 ms(20000 us):
$ echo 20000 > /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
它意味着在每 100 ms 的时间里,被该控制组限制的进程只能使用 20 ms 的 CPU 时间,也就是说这个进程只能使用到 20% 的 CPU 带宽。
接下来,我们把被限制的进程的 PID 写入 container 组里的 tasks 文件,上面的设置就会对该进程生效了:
$ echo 226 > /sys/fs/cgroup/cpu/container/tasks
可以看到,计算机的 CPU 使用率立刻降到了 20%(%Cpu0 : 20.3 us)。
除 CPU 子系统外,Cgroups 的每一项子系统都有其独有的资源限制能力,比如:
- blkio,为块设备设定I/O 限制,一般用于磁盘等设备;
- cpuset,为进程分配单独的 CPU 核和对应的内存节点;
- memory,为进程设定内存使用的限制。
Linux Cgroups 的设计还是比较易用的,简单粗暴地理解呢,它就是一个子系统目录加上一组资源限制文件的组合。而对于 Docker 等 Linux 容器项目来说,它们只需要在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录),然后在启动容器进程之后,把这个进程的 PID 填写到对应控制组的 tasks 文件中就可以了。
当然这些如果使用Kubernetes 这些都会帮咱们做了
Mount Namespace 和 rootfs :够为进程构建出一个完善的文件系统隔离环境
容器的rootfs由下图所示的三部分组成:
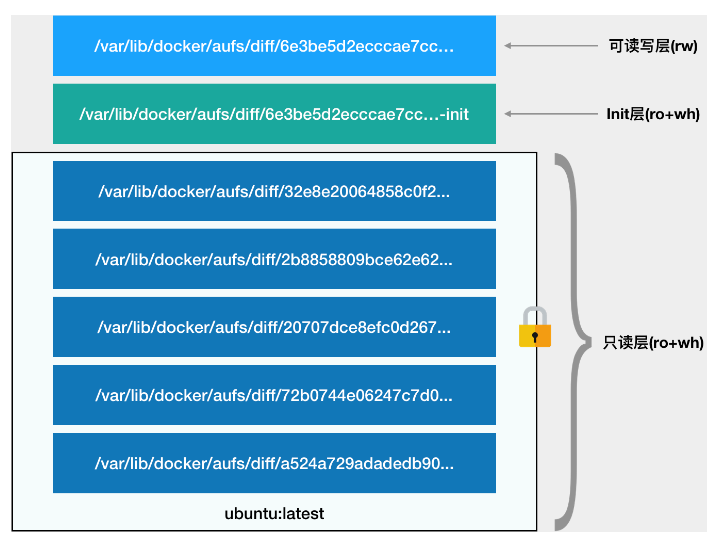
第一部分,只读层。
它是这个容器的 rootfs 最下面的五层,对应的正是 ubuntu:latest 镜像的五层。可以看到,它们的挂载方式都是只读的(ro+wh,即 readonly+whiteout,至于什么是 whiteout,我下面马上会讲到)。
这时,我们可以分别查看一下这些层的内容:
$ ls /var/lib/docker/aufs/diff/72b0744e06247c7d0... etc sbin usr var $ ls /var/lib/docker/aufs/diff/32e8e20064858c0f2... run $ ls /var/lib/docker/aufs/diff/a524a729adadedb900... bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
可以看到,这些层,都以增量的方式分别包含了 Ubuntu 操作系统的一部分。
第二部分,可读写层。
它是这个容器的 rootfs 最上面的一层(6e3be5d2ecccae7cc),它的挂载方式为:rw,即 read write。在没有写入文件之前,这个目录是空的。而一旦在容器里做了写操作,你修改产生的内容就会以增量的方式出现在这个层中。
可是,你有没有想到这样一个问题:如果我现在要做的,是删除只读层里的一个文件呢?
为了实现这样的删除操作,AuFS 会在可读写层创建一个 whiteout 文件,把只读层里的文件“遮挡”起来。
比如,你要删除只读层里一个名叫 foo 的文件,那么这个删除操作实际上是在可读写层创建了一个名叫.wh.foo 的文件。这样,当这两个层被联合挂载之后,foo 文件就会被.wh.foo 文件“遮挡”起来,“消失”了。这个功能,就是“ro+wh”的挂载方式,即只读 +whiteout 的含义。我喜欢把 whiteout 形象地翻译为:“白障”。
所以,最上面这个可读写层的作用,就是专门用来存放你修改 rootfs 后产生的增量,无论是增、删、改,都发生在这里。而当我们使用完了这个被修改过的容器之后,还可以使用 docker commit 和 push 指令,保存这个被修改过的可读写层,并上传到 Docker Hub 上,供其他人使用;而与此同时,原先的只读层里的内容则不会有任何变化。这,就是增量 rootfs 的好处
第三部分,Init 层。
它是一个以“-init”结尾的层,夹在只读层和读写层之间。Init 层是 Docker 项目单独生成的一个内部层,专门用来存放 /etc/hosts、/etc/resolv.conf 等信息。
需要这样一层的原因是,这些文件本来属于只读的 Ubuntu 镜像的一部分,但是用户往往需要在启动容器时写入一些指定的值比如 hostname,所以就需要在可读写层对它们进行修改。
可是,这些修改往往只对当前的容器有效,我们并不希望执行 docker commit 时,把这些信息连同可读写层一起提交掉。
所以,Docker 做法是,在修改了这些文件之后,以一个单独的层挂载了出来。而用户执行 docker commit 只会提交可读写层,所以是不包含这些内容的。
最终,这 7 个层都被联合挂载到 /var/lib/docker/aufs/mnt 目录下,表现为一个完整的 Ubuntu 操作系统供容器使用。
虚拟机与容器的对比图
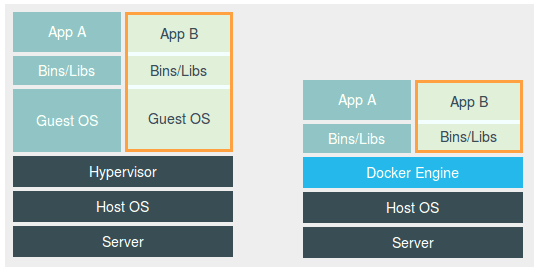
这幅图的左边,画出了虚拟机的工作原理。其中,名为 Hypervisor 的软件是虚拟机最主要的部分。它通过硬件虚拟化功能,模拟出了运行一个操作系统需要的各种硬件,比如 CPU、内存、I/O 设备等等。然后,它在这些虚拟的硬件上安装了一个新的操作系统,即 Guest OS。
这样,用户的应用进程就可以运行在这个虚拟的机器中,它能看到的自然也只有 Guest OS 的文件和目录,以及这个机器里的虚拟设备。这就是为什么虚拟机也能起到将不同的应用进程相互隔离的作用。
而这幅图的右边,则用一个名为 Docker Engine 的软件替换了 Hypervisor。这也是为什么,很多人会把 Docker 项目称为“轻量级”虚拟化技术的原因,实际上就是把虚拟机的概念套在了容器上。
2、k8s基本概念
Kubernetes 项目最主要的设计思想是,从更宏观的角度,以统一的方式来定义任务之间的各种关系,并且为将来支持更多种类的关系留有余地。
Kubernetes 项目核心功能的“全景图”。
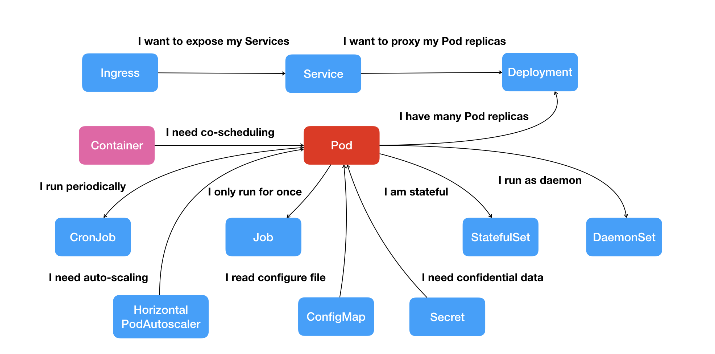
Kubernetes 项目中,我们所推崇的使用方法是:
- 首先,通过一个“编排对象”,比如 Pod、Job、CronJob 等,来描述你试图管理的应用;
- 然后,再为它定义一些“服务对象”,比如 Service、Secret、Horizontal Pod Autoscaler(自动水平扩展器)等。这些对象,会负责具体的平台级功能。
这种使用方法,就是所谓的“声明式 API”。这种 API 对应的“编排对象”和“服务对象”,都是 Kubernetes 项目中的 API 对象(API Object)。
例子:
最后,我来回答一个更直接的问题:Kubernetes 项目如何启动一个容器化任务呢?
比如,我现在已经制作好了一个 Nginx 容器镜像,希望让平台帮我启动这个镜像。并且,我要求平台帮我运行两个完全相同的 Nginx 副本,以负载均衡的方式共同对外提供服务。
-
如果是自己 DIY 的话,可能需要启动两台虚拟机,分别安装两个 Nginx,然后使用 keepalived 为这两个虚拟机做一个虚拟 IP。
-
而如果使用 Kubernetes 项目呢?你需要做的则是编写如下这样一个 YAML 文件(比如名叫 nginx-deployment.yaml):
apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment labels: app: nginx spec: replicas: 2 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9 ports:
- containerPort: 80
在上面这个 YAML 文件中,我们定义了一个 Deployment 对象,它的主体部分(spec.template 部分)是一个使用 Nginx 镜像的 Pod,而这个 Pod 的副本数是 2(replicas=2)。
然后执行:
kubectl create -f nginx-deployment.yaml
这样,两个完全相同的 Nginx 容器副本就被启动了。
重点
Kubernetes 项目所擅长的,是按照用户的意愿和整个系统的规则,完全自动化地处理好容器之间的各种关系。这种功能,就是我们经常听到的一个概念:编排。
所以说,Kubernetes 项目的本质,是为用户提供一个具有普遍意义的容器编排工具。
不过,更重要的是,Kubernetes 项目为用户提供的不仅限于一个工具。它真正的价值,乃在于提供了一套基于容器构建分布式系统的基础依赖