超参数搜索的策略
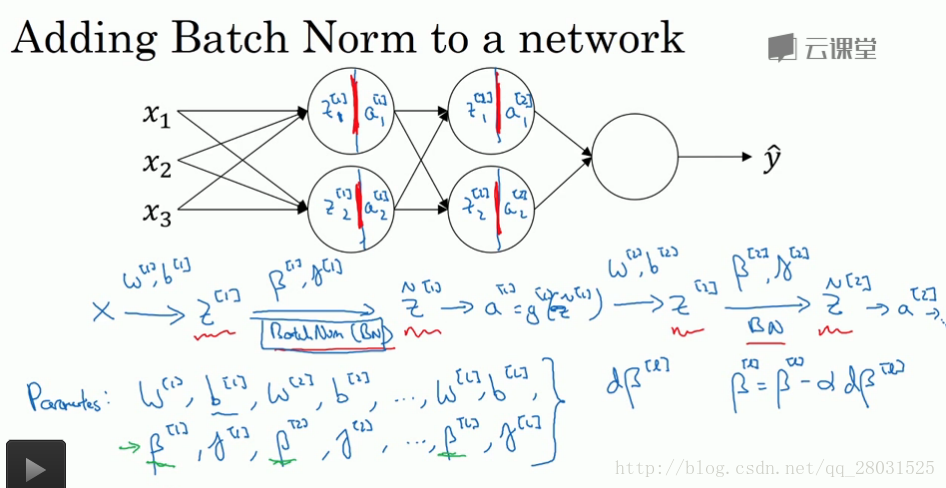
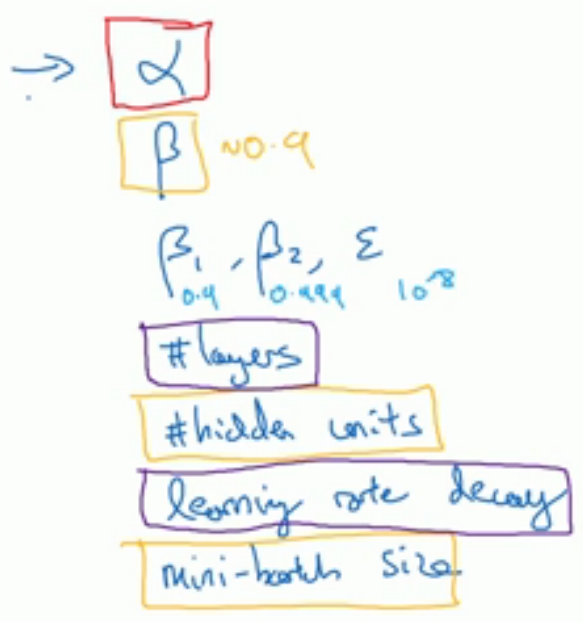
在深度学习中,超参数有很多,比如学习率α、使用momentum或Adam优化算法的参数(β1,β2,ε)、层数layers、不同层隐藏
单元数hidden units、学习率衰退、mini=batch的大小等。其中一些超参数比其他参数重要,其优先级可以分为以下几级,如图,红色
框最优先,橙色次之,紫色再次之,最后没有框住的一般直接取经验值。
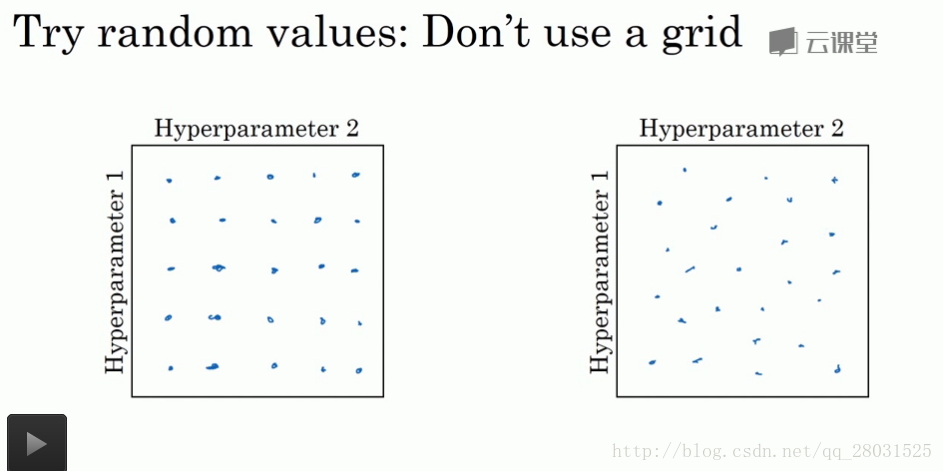
1. 随机取值。
网格搜索的问题在于:无法预先判断哪个参数是比较重要的,因此将浪费大量的运算在没有明细作用的变量上。
2. 精确搜索

为超参数选取合适的范围
对于如神经网络隐藏层数这类超参数可以采用平均取值,但是对于类似学习率和指数加权平均中的超参数ββ这类超参数需要采用对数平均取值。
如对学习率取值时,学习率的变化范围为[0.001,1],但是如果采用平均取值,则90%的都落在[0.1,1]的范围内,反而使得学习率不能在较大范围变化。因此采用对数取值,在区间[0.0001,0.001]、[0.001,0.01]、[0.01,0.1]和[0.1,1]内平均取值。 
假设指数加权平均中的beta参数取值范围为[0.9,0.999],那么根据平均效果计算公式,在接近1的取值时,即使较小的变化所得结果的灵敏度会变化,即使beta只有微小的变化,而当参数接近0.9时,平均效果的变化并不明显。为了在更大的范围内探索可取值,采用对数平均取值。 
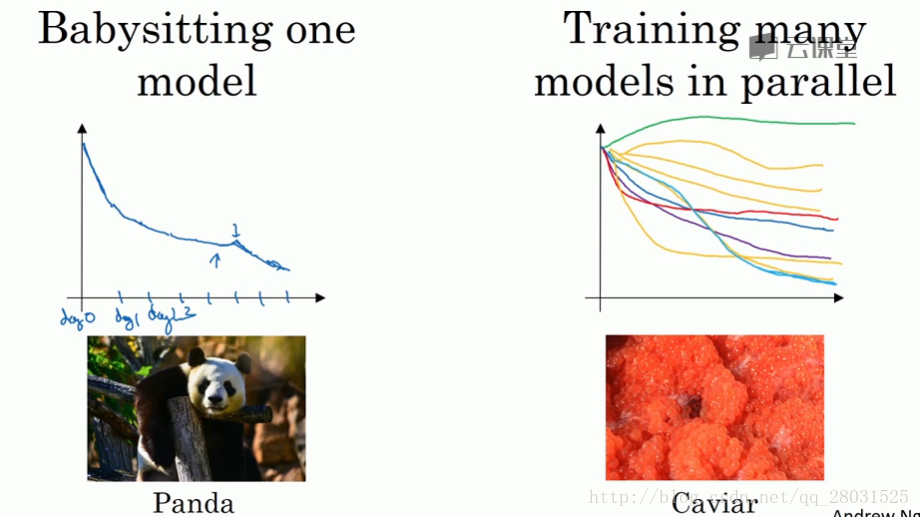
超参数搜索过程的两种方式
1. 在计算资源不足的情况下,单一模型上不断的尝试改变数值的设置
2. 在计算资源充足、数据丰富的情况下,可以尝试多种不同的模型并选择最好结果的模型
Batch normalization
Batch normalization归一化的作用在于它适用的归一化过程不只在输入层,同样适用于神经网络的深度隐藏层。采用Batch normalization归一化了一些隐藏层单元值的平均值和方差。
但是与输入层归一化不同,在隐藏单元中,一般不想设置0均值和单位方差,因为那样在激活函数中就只用到了线性部分,而没有充分的发挥激活单元的非线性作用。
一般把Batch normalization放在计算z和a之间,先对z进行BN处理,再通过激活函数。
Batch normalization 只能在mini-batch上计算均值和方差,因此在test时,需要一些细节操作。
整个forward计算过程:
Batch normalization的作用:
1. “Covariate shift”
BN限制了在前面层的参数更新会影响数值分布的程度,BN归一化减少了输入值改变的问题,并使得值的变化在固定的范围,使得值的变化更加稳定;同时也使得各个层之间的学习变得相互独立,有助于加速整个网络的学习;
2. regularization效果
在结合mini-batch使用时,由z[L]z[L]的计算转化为z˜[L]z~[L],且均值和方差的计算也是由一小部分数据估计得出,因此存在稍微的偏差,使得类似于dropout一样,在隐藏层添加了噪音,使得隐藏单元的神经元不能过分的依赖任何一个隐藏单元,有稍微正则化效果。
BN在测试集上的处理:
在测试集上预测一般是对单个样本处理,因此无法在测试集上得到整个数据集的均值和方差,而需要在测试集上使用BN时,一般可以有两种处理方式:
1、在整个训练集上得到每层的均值和方差,并利用神经网络中学习得到的参数BN;
2、在mini-batch的基础上针对每个batch计算每层的均值和方差,然后在最后预测的时候利用指数加权平均,对batch上的均值和方差做平均。
3、但是实际上如果采用深度神经网络框架时,一般都会有默认的估算均值和方差的方式。