PyTorch学习(2)
1 Numpy与Torch的区别与联系
1.1 numpy的array与Torch的tensor转换
1.2 Torch中的variable
2 激励函数(Activation Function)
3 Regression回归(关系拟合回归)
4 Classification(分类)
5 Torch网络
5.1 快速搭建torch网络
5.2 保存和提取网络与参数
5.3 批处理
5.3 优化器optimizer加速神经网络
6 神经网络分类
这里是根据莫凡pytorch学习的,与pytorch学习(1)可能有所重叠,但是大部分不太一样,可以结合着一起看。
1 Numpy与Torch的区别与联系
1.1 numpy的array与Torch的tensor转换
1)数据类型转换
注:torch只处理二维数据
import torch
import numpy as np
np_data = np.arange(6).reshape((2, 3))
torch_data = torch.from_numpy(np_data)
tensor2array = torch_data.numpy()
print('
np_data', np_data,
'
torch_data', torch_data,
'
tensor2array', tensor2array, )
#结果显示
np_data [[0 1 2]
[3 4 5]]
torch_data tensor([[0, 1, 2],
[3, 4, 5]], dtype=torch.int32)
tensor2array [[0 1 2]
[3 4 5]]
2)矩阵乘法
data = [[1, 2], [2, 3]]
tensor = torch.FloatTensor(data)
print('
numpy', np.matmul(data, data),
'
torch', torch.matmul(tensor, tensor))
#结果显示
numpy [[ 5 8]
[ 8 13]]
torch tensor([[ 5., 8.],
[ 8., 13.]])
注意的是torch中默认的tensor是float形式的
1.2 Torch中的variable
import torch
from torch.autograd import Variable
tensor = torch.FloatTensor([[1, 2], [3, 4]])
variable = Variable(tensor, requires_grad=True)
t_out = torch.mean(tensor*tensor)
v_out = torch.mean(variable*variable)
print('tensor', tensor)
print('variable', variable)
print('t_out', t_out)
print('v_out', v_out)
v_out.backward() # 反向传播
print('grad', variable.grad) # variable的梯度
print(variable.data.numpy())
#结果显示
tensor tensor([[1., 2.],
[3., 4.]])
variable tensor([[1., 2.],
[3., 4.]], requires_grad=True)
t_out tensor(7.5000)
v_out tensor(7.5000, grad_fn=<MeanBackward0>)
grad tensor([[0.5000, 1.0000],
[1.5000, 2.0000]])
[[1. 2.]
[3. 4.]]
2 激励函数(Activation Function)
对于多层神经网络,激励函数的选择有一定窍门
推荐网络与激活函数的对应:
-
CNN-relu
-
RNN-relu/tanh
有三种常用激活函数:(这里说的是线图)
relu、sigmoid、tanh
import torch
from torch.autograd import Variable
import matplotlib.pyplot as plt
x = torch.linspace(-5, 5, 200) # 从-5~5分成200段
x = Variable(x)
x_np = x.data.numpy()
y_relu = torch.relu(x).data.numpy()
y_sigmoid = torch.sigmoid(x).data.numpy()
y_tanh = torch.tanh(x).data.numpy()
plt.figure(1, figsize=(8, 6))
plt.subplot(311)
plt.plot(x_np, y_relu, c='r', label='relu')
plt.ylim((-1, 5))
plt.legend(loc='best')
plt.subplot(312)
plt.plot(x_np, y_sigmoid, c='g', label='sigmoid')
plt.ylim((-0.2, 1.5))
plt.legend(loc='best')
plt.subplot(313)
plt.plot(x_np, y_tanh, c='b', label='tanh')
plt.ylim((-1.2, 1.5))
plt.legend(loc='best')
plt.show()
#结果显示
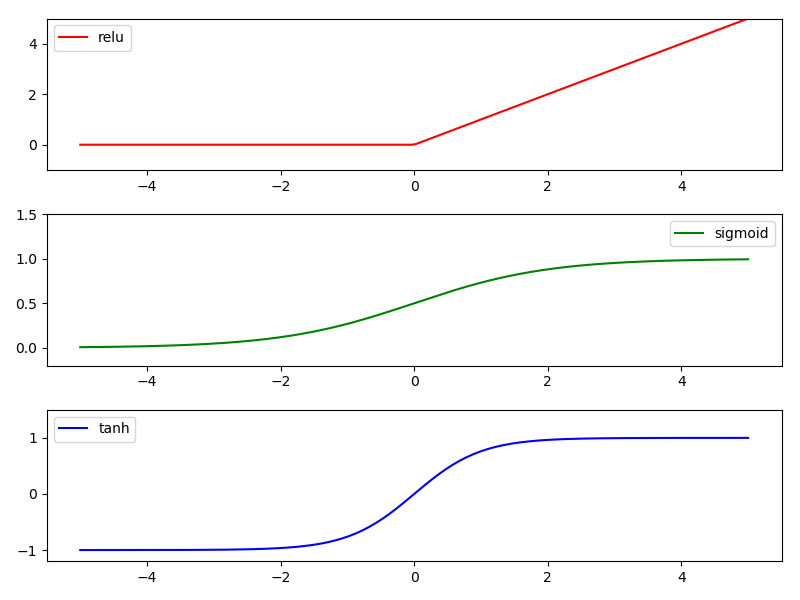
3 Regression回归(关系拟合回归)
一般分为两种:
-
回归问题:一堆数据出一条线
-
分类问题:一堆数据进行分类
我们讲的是回归问题:
import torch
from torch.autograd import Variable
import matplotlib.pyplot as plt
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # 一维变二维
y = x.pow(2) + 0.2*torch.rand(x.size())
x, y = Variable(x), Variable(y)
# plt.scatter(x.data.numpy(), y.data.numpy())
# plt.show()
# 搭建网络
class Net(torch.nn.Module):
def __init__(self, n_features, n_hidden , n_output):
super(Net, self).__init__()
# 以上为固定的初始化
self.hidden = torch.nn.Linear(n_features, n_hidden)
self.predict = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = torch.relu(self.hidden(x))
x = self.predict(x)
return x
net = Net(1, 10, 1) # 1个输入点,10个隐藏层的节点,1个输出
print(net)
plt.ion() # 可视化
plt.show()
optimizer = torch.optim.SGD(net.parameters(), lr=0.5)
loss_function = torch.nn.MSELoss() # 回归问题用均方误差,分类问题用其他的误差损失函数
for t in range(100):
out = net(x)
loss = loss_function(out, y) # 预测值在前真实值在后
optimizer.zero_grad()
loss.backward()
optimizer.step()
if t % 5 == 0:
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), out.data.numpy(), 'r-', lw=5)
plt.text(0.5, 0, 'Loss=%.4f' % loss.item(), fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
plt.ioff()
plt.show()
#结果显示
Net(
(hidden): Linear(in_features=1, out_features=10, bias=True)
(predict): Linear(in_features=10, out_features=1, bias=True)
)
最终输出的结果图:
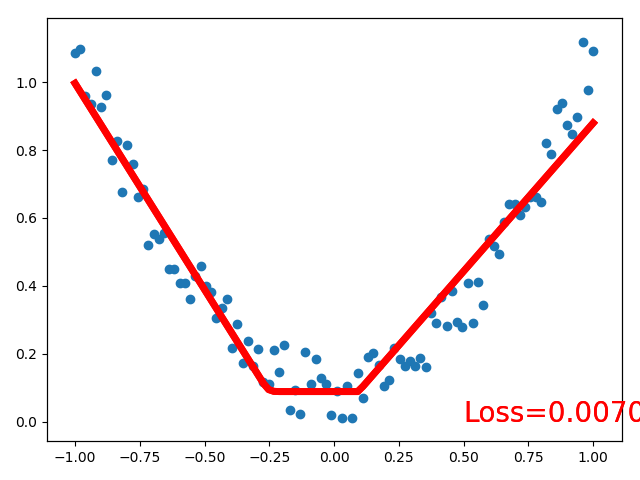
4 Classification(分类)
import torch
from torch.autograd import Variable
import matplotlib.pyplot as plt
n_data = torch.ones(100, 2)
x0 = torch.normal(2*n_data, 1)
y0 = torch.zeros(100)
x1 = torch.normal(-2*n_data, 1)
y1 = torch.ones(100)
x = torch.cat((x0, x1), 0).type(torch.FloatTensor)
y = torch.cat((y0, y1), ).type(torch.LongTensor)
x, y = Variable(x), Variable(y)
# plt.scatter(x.data.numpy(), y.data.numpy())
# plt.show()
# 搭建网络
class Net(torch.nn.Module):
def __init__(self, n_features, n_hidden , n_output):
super(Net, self).__init__()
# 以上为固定的初始化
self.hidden = torch.nn.Linear(n_features, n_hidden)
self.predict = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = torch.relu(self.hidden(x))
x = self.predict(x)
return x
net = Net(2, 10, 2) # 2个输入点,10个隐藏层的节点,2个输出
print(net)
plt.ion() # 可视化
plt.show()
optimizer = torch.optim.SGD(net.parameters(), lr=0.2)
loss_function = torch.nn.CrossEntropyLoss()
for t in range(10): # 训练的步数
out = net(x)
loss = loss_function(out, y) # 预测值在前真实值在后
optimizer.zero_grad()
loss.backward()
optimizer.step()
if t % 2 == 0:
plt.cla()
out = torch.softmax(out, 1)
prediction = torch.max(out, 1)[1] # 如果索引为1则为最大值所在位置,如果为0,则为最大值本身
pred_y = prediction.data.numpy().squeeze()
target_y = y.data.numpy()
plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=pred_y, s=100)
accuracy = sum(pred_y == target_y) / 200
plt.text(1.5, -4, 'Accuracy=%.4f' % accuracy, fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
plt.ioff()
plt.show()
#结果显示
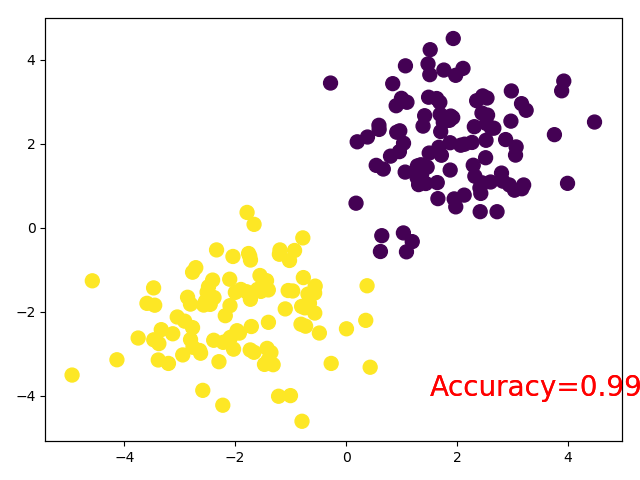
5 Torch网络
5.1 快速搭建torch网络
# 搭建网络
class Net(torch.nn.Module):
def __init__(self, n_features, n_hidden , n_output):
super(Net, self).__init__()
# 以上为固定的初始化
self.hidden = torch.nn.Linear(n_features, n_hidden)
self.predict = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = torch.relu(self.hidden(x))
x = self.predict(x)
return x
net1 = Net(2, 10, 2) # 2个输入点,10个隐藏层的节点,2个输出
print(net1)
net2 = torch.nn.Sequential(
torch.nn.Linear(2, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 2),
)
print(net2)
这里的net1与net2其实是一样的,其中多数用第二种方式进行模型搭建,net2与tensorflow中的搭建方式一样。
5.2 保存和提取网络与参数
import torch
from torch.autograd import Variable
import matplotlib.pyplot as plt
torch.manual_seed(1)
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # 一维变二维
y = x.pow(2) + 0.2*torch.rand(x.size())
x, y = Variable(x, requires_grad=False), Variable(y, requires_grad=False) # 当requires_grade为False时,不用求梯度
def save():
net1 = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1),
)
optimizer = torch.optim.SGD(net1.parameters(), lr=0.05)
loss_function = torch.nn.MSELoss()
for t in range(1000): # 训练的步数
prediction = net1(x)
loss = loss_function(prediction, y) # 预测值在前真实值在后
optimizer.zero_grad()
loss.backward()
optimizer.step()
torch.save(net1, 'net.pkl') # 保存模型
torch.save(net1.state_dict(), 'net_params.pkl') # 保存所有节点
plt.figure(1, figsize=(10, 3))
plt.subplot(131)
plt.title('Net1')
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
def restore_net():
net2 = torch.load('net.pkl')
prediction = net2(x)
plt.subplot(132)
plt.title('Net2')
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
def restore_params():
net3 = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1),
)
net3.load_state_dict(torch.load('net_params.pkl'))
prediction = net3(x)
plt.subplot(133)
plt.title('Net3')
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
plt.show()
save()
restore_net()
restore_params()
#结果显示

5.3 批处理
import torch
import torch.utils.data as Data
BATCH_SIZE = 5 # 一小批5个训练
x = torch.linspace(1, 10, 10)
y = torch.linspace(10, 1, 10)
torch_dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(
dataset=torch_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=2,
) # shuffle就是定义是否打乱数据顺序, num_workers就是用几个线程进行提取
def show_batch():
for epoch in range(3): # 总体训练三次
for step, (batch_x, batch_y) in enumerate(loader):
print('Epoch: ', epoch, '| Step: ', step, '| batch x: ', batch_x.numpy(), '| batch y: ', batch_y.numpy())
if __name__ == '__main__':
show_batch()
#结果显示
Epoch: 0 | Step: 0 | batch x: [10. 1. 2. 9. 4.] | batch y: [ 1. 10. 9. 2. 7.]
Epoch: 0 | Step: 1 | batch x: [5. 7. 6. 3. 8.] | batch y: [6. 4. 5. 8. 3.]
Epoch: 1 | Step: 0 | batch x: [3. 1. 2. 7. 5.] | batch y: [ 8. 10. 9. 4. 6.]
Epoch: 1 | Step: 1 | batch x: [10. 4. 9. 8. 6.] | batch y: [1. 7. 2. 3. 5.]
Epoch: 2 | Step: 0 | batch x: [10. 7. 1. 5. 4.] | batch y: [ 1. 4. 10. 6. 7.]
Epoch: 2 | Step: 1 | batch x: [9. 3. 8. 6. 2.] | batch y: [2. 8. 3. 5. 9.]
5.3 优化器optimizer加速神经网络
-
所有的优化器都是更新我们神经网络的参数,例传统更新方法:
-
Adam方法
m为下坡属性,v为阻力属性
import torch
import torch.utils.data as Data
# from torch.autograd import Variable
import matplotlib.pyplot as plt
LR = 0.02
BATH_SIZE = 32
EPOCH = 12
x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size()))
# plt.scatter(x.numpy(), y.numpy())
# plt.show()
torch_dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATH_SIZE, shuffle=True, num_workers=2)
# class Net(torch.nn.Module):
# def __init__(self, n_features=1, n_hidden=20 , n_output=1):
# super(Net, self).__init__()
# # 以上为固定的初始化
# self.hidden = torch.nn.Linear(n_features, n_hidden)
# self.predict = torch.nn.Linear(n_hidden, n_output)
#
# def forward(self, x):
# x = torch.relu(self.hidden(x))
# x = self.predict(x)
# return x
net = torch.nn.Sequential(
torch.nn.Linear(1, 20),
torch.nn.ReLU(),
torch.nn.Linear(20, 1)
)
net_SGD = net
# net_Momentum = net
# net_RMSprop = net
net_Adam = net
nets = [net_SGD, net_Adam]
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
# opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.7)
# opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Adam]
loss_func = torch.nn.MSELoss()
losses_his = [[], []]
def show_batch():
for epoch in range(EPOCH):
print(epoch)
for step, (batch_x, batch_y) in enumerate(loader):
# b_x = Variable(batch_x)
# b_y = Variable(batch_y)
for net, opt, l_his in zip(nets, optimizers, losses_his):
output = net(batch_x)
loss = loss_func(output, batch_y)
opt.zero_grad()
loss.backward()
opt.step()
l_his.append(loss.item())
# print('1111', l_his)
labels = ['SGD', 'Adam']
for i, l_his in enumerate(losses_his):
plt.plot(l_his, label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0, 0.2))
plt.show()
if __name__ == '__main__':
show_batch()
#结果显示
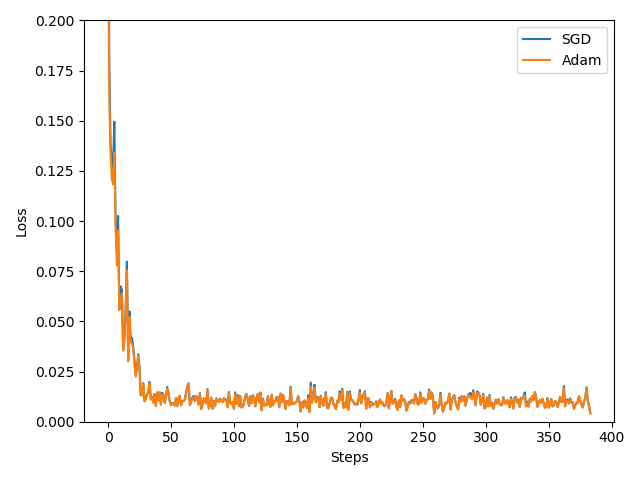
6 神经网络分类
-
CNN 卷积神经网络
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision
import matplotlib.pyplot as plt
EPOCH = 1
BATCH_SIZE = 50
LR = 0.001
DOWNLOAD_MNIST = True
train_data = torchvision.datasets.MNIST(
root='./mnist',
train=True,
transform=torchvision.transforms.ToTensor(), # 将三维数据压缩成二维的(0, 1)
download=DOWNLOAD_MNIST
)
# print(train_data.data.size())
# print(train_data.targets.size())
# plt.imshow(train_data.data[0].numpy(), cmap='gray')
# plt.title('%i' % train_data.targets[0])
# plt.show()
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True, num_workers=2)
test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
test_x = torch.unsqueeze(test_data.data, dim=1).type(torch.FloatTensor)[:2000]/255.
test_y = test_data.targets[:2000]
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=1,
out_channels=16,
kernel_size=5,
stride=1,
padding=2, # padding=(kernel_size-1)/2
),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,),
)
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.out = nn.Linear(32 * 7 * 7, 10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1) # 这里的size就是conv2的输出,-1就是展平
output = self.out(x)
return output
cnn = CNN()
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR)
loss_func = nn.CrossEntropyLoss()
def show_batch():
for epoch in range(EPOCH):
print(epoch)
for step, (batch_x, batch_y) in enumerate(train_loader):
# b_x = Variable(batch_x)
# b_y = Variable(batch_y)
output = cnn(batch_x)
loss = loss_func(output, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 50 == 0:
test_output = cnn(test_x)
pred_y = torch.max(test_output, 1)[1].data.squeeze()
accuracy = sum(pred_y == test_y) / float(test_y.size(0))
print('Epoch: ', epoch, '| train loss: %.4f' % loss.