awk处理的内容可以是标准输入,文本文件或管道
awk演示文档passwd
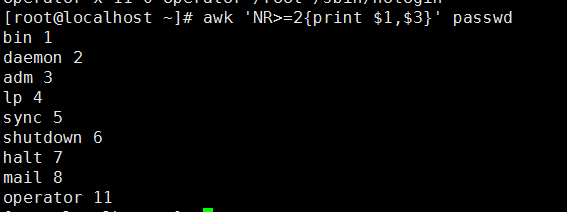
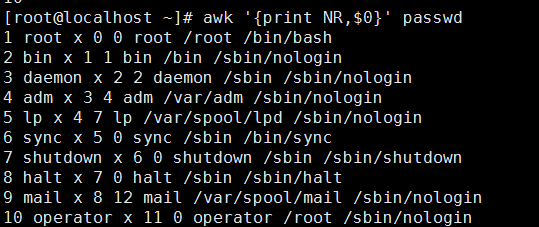
root x 0 0 root /root /bin/bash bin x 1 1 bin /bin /sbin/nologin daemon x 2 2 daemon /sbin /sbin/nologin adm x 3 4 adm /var/adm /sbin/nologin lp x 4 7 lp /var/spool/lpd /sbin/nologin sync x 5 0 sync /sbin /bin/sync shutdown x 6 0 shutdown /sbin /sbin/shutdown halt x 7 0 halt /sbin /sbin/halt mail x 8 12 mail /var/spool/mail /sbin/nologin operator x 11 0 operator /root /sbin/nologin
输出行号大于2的第一列和第三列
awk 'NR>=2{print $1,$3}' passwd
awk处理文本执行过程
1,awk读入第一行内容
2,判断是否符合条件(NR>=2)
不符合条件,不处理
符合条件,打印1,3列
3,顺序读取第2,3,4,5...行知道文件结尾
域和记录
awk里面使用$0,$1...表示对于的列其中$0表示整行记录 $NF表示最后一列
awk对每个要处理的数据认为都具有格式和结构,而不仅仅是一堆字符串。默认情况下,每一行内容成为一个记录。
输入行号加内容
awk '{print NR,$0}' passwd
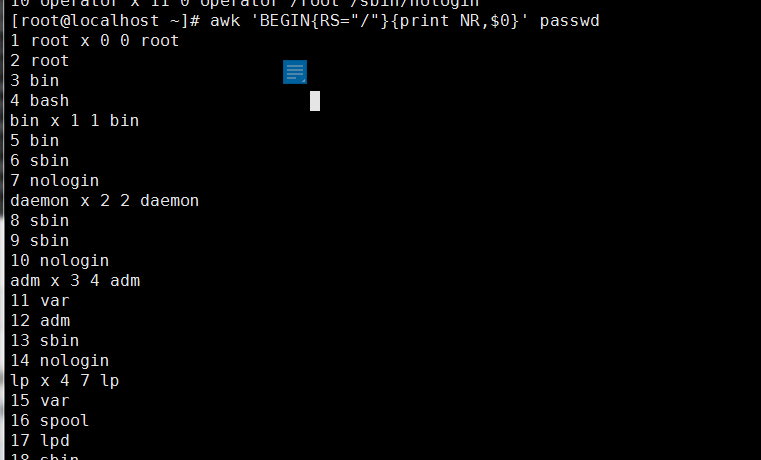
默认行的分隔符RS是换行,可以改成其他字符例如/
awk 'BEGIN{RS="/"}{print NR,$0}' passwd
awk把文件当做一个连续的字符串。默认 为换行符
FS分隔符默认是空格,连续空格和tab建
使用以下格式指定分隔符
awk -F ":"
使用分隔符分割passwd文件
awk -F ":" '{print $1,$NF}' /etc/passwd
使用FS变量定义分隔符效果是一样的
awk 'BEGIN{FS=":"}{print $1,$NF}' /etc/passwd
PS:输出分隔符OFS 用的不多
awk 'BEGIN{FS=":";OFS="/"}{print $1,$NF}' /etc/passwd
指定多个分隔符,以:和/为分隔符
awk -F "[:/]" '{print $1}' /etc/passwd
awk正则表达式
匹配以s开头的一整行
awk '/^s/{print $0}' passwd
匹配第五个区域以r开头的行(sed不方便)
awk '$5~/^r/ {print $0}' passwd
$5代表第五个区域 ~代表匹配 ,匹配的符合用//放在中间
匹配第五区域以c结尾的显示一整行
awk '$5~/c$/ {print $0}' passwd
匹配包含一个或者两个o的行并且打印出整行
awk --posix '/o{1,2}/{print $0}' passwd
打印大于第2行小于第5行的整行
awk 'NR>=2&&NR<=5{print NR,$0}' passwd
未完待续30