之前我们学习了XPath的简单使用,参考:https://www.cnblogs.com/minseo/p/15502584.html
今天我们来练习XPath的使用,使用XPath分析豆瓣电影排行榜,本次我们练习获取电影排行榜的新片榜信息,练习获取的内容是新片的url,影片名称,导演名
为了便于查看XPath分析html的整个过程我们把网页的源码下载下来,使用文本编辑器Notepad++打开,该文本编辑器可以清楚的查看标签的对应关系。
首先我们来查找10部新片的url
查看源码发现豆瓣新片榜包含在一个标签<div>内该标签有一个唯一识别的id=“conetent”

使用XPath查找这个标签
# 爬取豆瓣电影排行榜的新片帮,使用同步方法
# 导入模块
import requests
from lxml import etree
# 设置访问客户端头部信息,不设置可能无法使用requests访问
headers = {'User-Agent': 'M'}
movice_url = 'https://movie.douban.com/chart'
resp = requests.get(movice_url,headers=headers)
# 获取响应的所有源码信息
movice_resp_text = resp.text
# 使用etree.HTML转换成可以使用xpath分析的lxml.etree._Element对象
movice_etree_element = etree.HTML(movice_resp_text)
movice_url = movice_etree_element.xpath('//*[@id="content"]')
print(movice_url)
XPath代码解析
xpath('//*[@id="content"]')
// # 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置
* # 通配符匹配所有
[@id="content"] # 匹配标签属性,本次这个id属性是唯一的所以可以匹配到一个唯一的标签
注意:匹配代码如果有多个引号则内部和外部不能使用相同的引号符号,即外部使用单引号则内部需要使用双引号,反之亦然
本次查找到一个对象输出如下
[<Element div at 0x134e93395c8>]
如果不确定是否查到的是这个标签,可以打印标签的关键属性查看
打印id属性可以看到确实是对应的标签
movice_url = movice_etree_element.xpath('//*[@id="content"]/@id')
print(movice_url)
# ['content']
下面缩小范围继续查找,在上一步查找到的标签下继续查找<div>标签
movice_url = movice_etree_element.xpath('//*[@id="content"]/div')
print(movice_url)
# [<Element div at 0x1f2b3248688>]
又找到唯一一个,打印标签的class属性看一下找到的是哪个标签
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/@class')
print(movice_url)
# ['grid-16-8 clearfix']
可以看到找到的是源码里面对应的下面这个标签
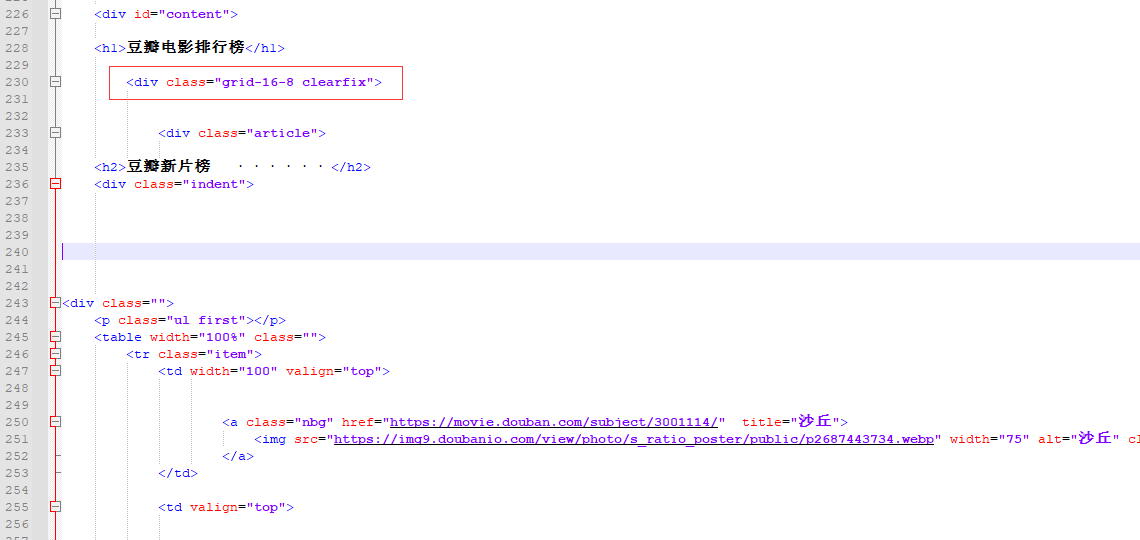
很明显还没有找到对应的电影url
下面缩小范围继续查找
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div')
print(movice_url)
# [<Element div at 0x288c4f18508>, <Element div at 0x288c4f18548>, <Element div at 0x288c4f18488>]
在找到的上一个标签<div>下找到3个<div>标签,下面我们还是通过属性来确定新片在这三个标签中的哪一个标签
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div')
print(movice_url[0].xpath('@class'),movice_url[1].xpath('@class'),movice_url[2].xpath('@class'))
# ['article'] ['aside'] ['extra']
通过取列表的元素再使用xpath方法去查找属性class的值来确定3个标签的位置
关键关键字在源码中查找这三个标签的位置
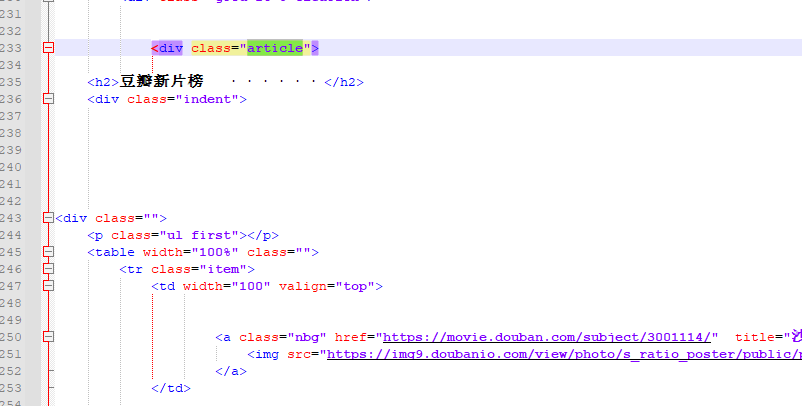
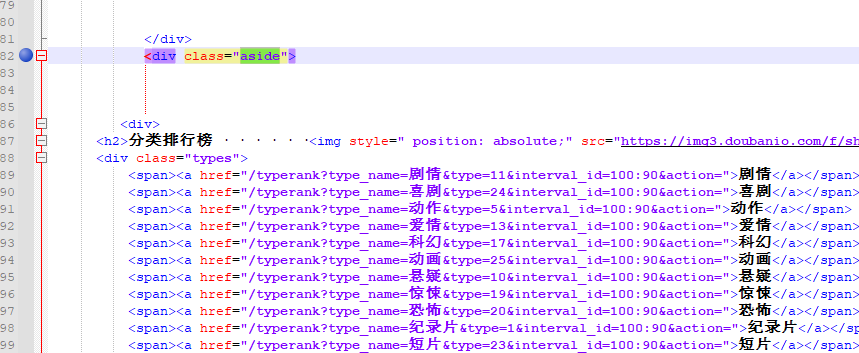

很明显我们要找的电影url在第一个标签内
缩小范围继续查找,查找第一个标签
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div[1]')
print(movice_url)
# print(movice_url)
[<Element div at 0x23daef97788>]
注意:这里第一个标签的下标是1而不是像python其他对象比如list的第一个标签是0
这次又返回一个对象
下面继续查找下一个div标签打印属性class
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div[1]/div/@class')
print(movice_url)
# ['indent']
又找到唯一一个<div>标签,在源码里如下位置
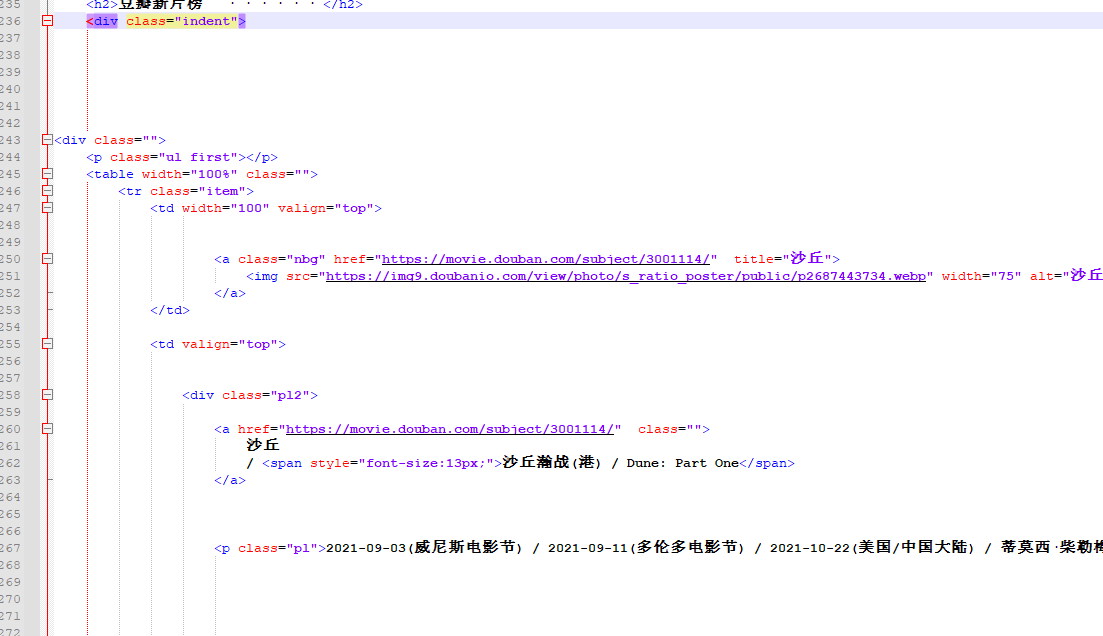
缩小范围继续查找
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div[1]/div/div')
print(movice_url)
# [<Element div at 0x2d9b21186c8>]
又只有一个,新片还在这个标签范围内
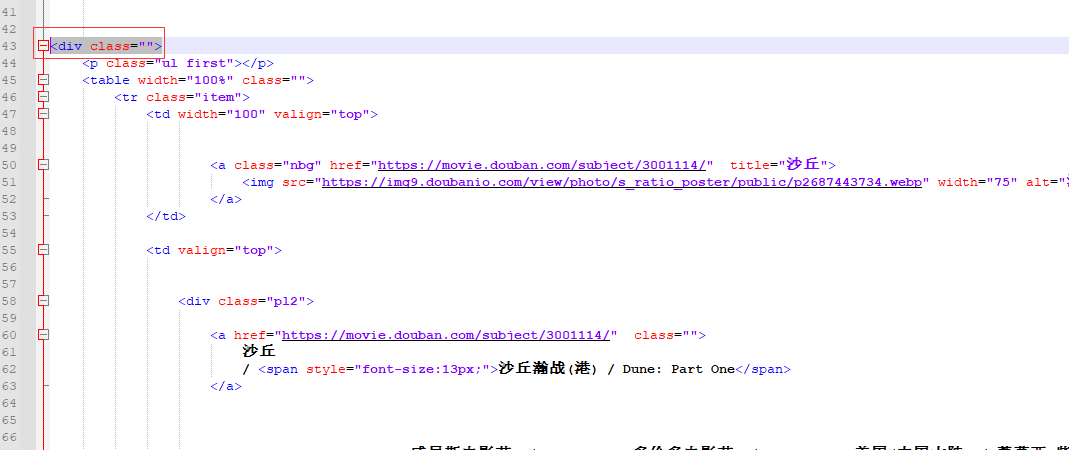
缩小范围继续查,因为这个标签下面是table标签使用我们使用table标签查找
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div[1]/div/div/table')
print(movice_url)
# [<Element table at 0x1bedccf8608>, <Element table at 0x1bedccf8588>, <Element table at 0x1bedccf85c8>, <Element table at 0x1bedccf8508>, <Element table at 0x1bedccf8188>, <Element table at 0x1bedccf8148>, <Element table at 0x1bedccf8108>, <Element table at 0x1bedccf8048>, <Element table at 0x1bedccf8088>, <Element table at 0x1bedccf8208>]
在这个<div>标签下包含了10个table标签,很明显新片10部电影的信息在这10个table内
缩小范围继续查找这10部电影对应的url下面查找tr标签
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div[1]/div/div/table/tr')
print(movice_url)
# [<Element tr at 0x2135c038648>, <Element tr at 0x2135c0385c8>, <Element tr at 0x2135c038608>, <Element tr at 0x2135c038548>, <Element tr at 0x2135c0381c8>, <Element tr at 0x2135c038188>, <Element tr at 0x2135c038148>, <Element tr at 0x2135c038088>, <Element tr at 0x2135c0380c8>, <Element tr at 0x2135c038248>]
还是10个对象,代表10部电影的内容都在这10行内
缩小范围继续查找
movice_etree_element = etree.HTML(movice_resp_text)
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div[1]/div/div/table/tr/td')
print(movice_url)
这次返回了20个对象即20个td即每行有2列,我们取需要的列即第一列
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div[1]/div/div/table/tr/td[1]')
print(movice_url)
又返回10个列标签,我们需要是url信息就在这10个列内
是以下源码对应的列,一共10个只截取出一个展示
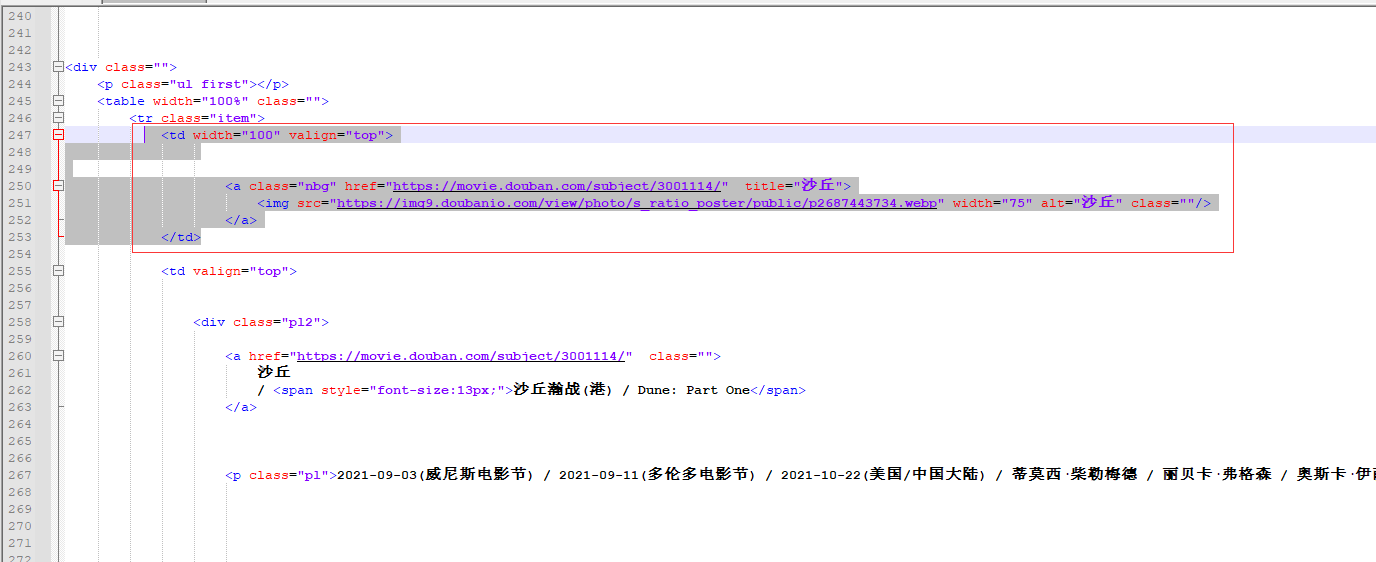
缩小范围继续查找这次我们找<a>标签
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div[1]/div/div/table/tr/td[1]/a')
print(movice_url)
没有问题还是返回10个对应的<a>标签,即源码对应的
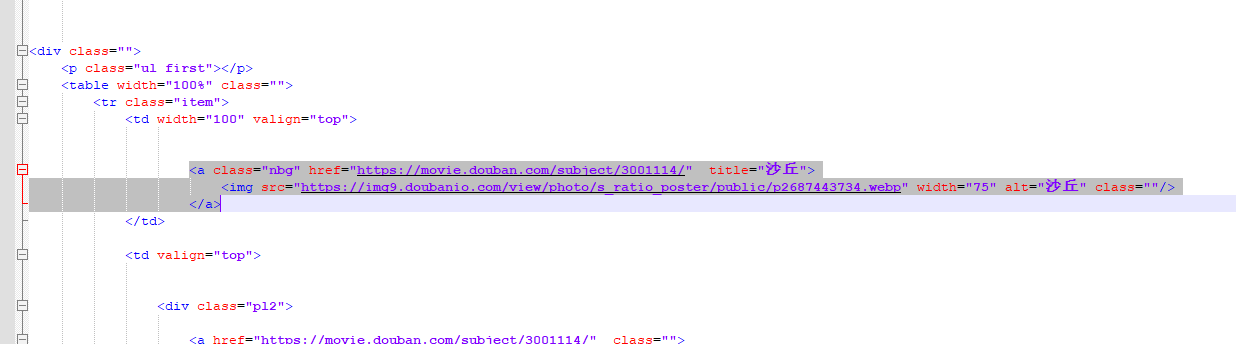
下面去这个标签是href属性值就把10部电影的url取出来了
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div[1]/div/div/table/tr/td[1]/a/@href')
print(movice_url)
# ['https://movie.douban.com/subject/3001114/', 'https://movie.douban.com/subject/33457594/', 'https://movie.douban.com/subject/34820925/', 'https://movie.douban.com/subject/35235502/', 'https://movie.douban.com/subject/1428581/', 'https://movie.douban.com/subject/34626280/', 'https://movie.douban.com/subject/35158124/', 'https://movie.douban.com/subject/34874432/', 'https://movie.douban.com/subject/35115642/', 'https://movie.douban.com/subject/32568661/']
根据取得的url取其中一个url分析取得这部电影的电影名和导演名
原理和上述是一样的,关键是从源码中找出对应的信息
# 设置访问客户端头部信息,不设置可能无法使用requests访问
headers = {'User-Agent': 'M'}
movice_url = 'https://movie.douban.com/subject/3001114/'
resp = requests.get(movice_url,headers=headers)
# 获取响应的所有源码信息
movice_resp_text = resp.text
# 使用etree.HTML转换成可以使用xpath分析的lxml.etree._Element对象
movice_etree_element = etree.HTML(movice_resp_text)
movice_name = movice_etree_element.xpath('//*[@id="content"]/h1/span[1]/text()')
movice_author = movice_etree_element.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')
print(movice_name,movice_author)
# ['沙丘 Dune'] ['丹尼斯·维伦纽瓦']
下面把以上代码修改成函数然后获取10部新片的信息,并查看执行的时间
d:/learn-python3/学习脚本/aiohttp/get_movice_use_sync.py
# 爬取豆瓣电影排行榜的新片帮,使用同步方法
# 导入模块
import requests
from lxml import etree
import time
def get_movice_url():
# 设置访问客户端头部信息,不设置可能无法使用requests访问
headers = {'User-Agent': 'M'}
movice_url = 'https://movie.douban.com/chart'
resp = requests.get(movice_url,headers=headers)
# 获取响应的所有源码信息
movice_resp_text = resp.text
# 使用etree.HTML转换成可以使用xpath分析的lxml.etree._Element对象
movice_etree_element = etree.HTML(movice_resp_text)
# 获取10部电影的url返回一个list元素为10部电影url
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div[1]/div/div/table/tr/td[1]/a/@href')
return movice_url
def get_movice_info():
movice_url = get_movice_url()
# print(movice_url)
# 设置访问客户端头部信息,不设置可能无法使用requests访问
headers = {'User-Agent': 'M'}
# 定义空字典用于接收影片信息
movice_info = {}
# 把获取到的电影url遍历出影片名称和导演
for url in movice_url:
resp = requests.get(url,headers=headers)
# 获取响应的所有源码信息
movice_resp_text = resp.text
# 使用etree.HTML转换成可以使用xpath分析的lxml.etree._Element对象
movice_etree_element = etree.HTML(movice_resp_text)
# 获取影片的名称和导演
movice_name = movice_etree_element.xpath('//*[@id="content"]/h1/span[1]/text()')
movice_author = movice_etree_element.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')
# 把获取到的影片名称和导演作为一个value赋值给字典,字典key为影片url
movice_info[url] = {'name':movice_name,'author':movice_author}
return movice_info
if __name__ == '__main__':
start_time = time.time()
movice_info = get_movice_info()
print(movice_info)
end_time = time.time()
print(end_time-start_time)
输出如下,返回字典包含了影片的url,影片名称和导演名,执行时间为8秒多
{'https://movie.douban.com/subject/3001114/': {'name': ['沙丘 Dune'], 'author': ['丹尼斯·维伦纽瓦']}, 'https://movie.douban.com/subject/33457594/': {'name': ['摩加迪
沙 모가디슈'], 'author': ['柳昇完']}, 'https://movie.douban.com/subject/34820925/': {'name': ['钛 Titane'], 'author': ['朱利亚·迪库诺']}, 'https://movie.douban.com/subject/35235502/': {'name': ['驾驶我的车 ドライブ・マイ・カー'], 'author': ['滨口龙介']}, 'https://movie.douban.com/subject/1428581/': {'name': ['天书奇谭'], 'author': ['王树忱', '钱运达']}, 'https://movie.douban.com/subject/34626280/': {'name': ['月光光心慌慌:杀戮 Halloween Kills'], 'author': ['大卫·戈登·格林']}, 'https://movie.douban.com/subject/35158124/': {'name': ['盛夏未来'], 'author': ['陈正道']}, 'https://movie.douban.com/subject/34874432/': {'name': ['花束般的恋爱 花束みたいな恋をした
'], 'author': ['土井裕泰']}, 'https://movie.douban.com/subject/35115642/': {'name': ['平行森林'], 'author': ['郑雷']}, 'https://movie.douban.com/subject/32568661/': {'name': ['妈妈的神奇小子 媽媽的神奇小子'], 'author': ['尹志文']}}
8.593812465667725
下面结合aiohttp和asyncio使用异步方法执行同样的操作
get_movice_use_async.py
# 爬取豆瓣电影排行榜的新片帮,使用异步方法
# 导入模块
import requests
from lxml import etree
import time
import asyncio
import aiohttp
async def get_movice_url():
# 设置访问客户端头部信息,不设置可能无法使用requests访问
headers = {'User-Agent': 'M'}
movice_url = 'https://movie.douban.com/chart'
async with aiohttp.ClientSession() as session:
async with session.get(movice_url,headers=headers) as resp:
# print(resp.status)
# 获取响应的所有源码信息
movice_resp_text = await resp.text()
# 使用etree.HTML转换成可以使用xpath分析的lxml.etree._Element对象
movice_etree_element = etree.HTML(movice_resp_text)
# 获取10部电影的url返回一个list元素为10部电影url
movice_url = movice_etree_element.xpath('//*[@id="content"]/div/div[1]/div/div/table/tr/td[1]/a/@href')
return movice_url
async def get_movice_info(url):
# 设置访问客户端头部信息,不设置可能无法使用requests访问
headers = {'User-Agent': 'M'}
# 把获取到的电影url遍历出影片名称和导演
async with aiohttp.ClientSession() as session:
async with session.get(url,headers=headers) as resp:
# 获取响应的所有源码信息
movice_resp_text = await resp.text()
# 使用etree.HTML转换成可以使用xpath分析的lxml.etree._Element对象
movice_etree_element = etree.HTML(movice_resp_text)
# 取影片的名称和导演
movice_name = movice_etree_element.xpath('//*[@id="content"]/h1/span[1]/text()')
movice_author = movice_etree_element.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')
# 把获取到的影片名称和导演作为一个value赋值给字典,字典key为影片url
return {url:{'name':movice_name,'author':movice_author}}
# 定义主执行协程函数main
async def main():
# 首先调用协程函数获取影片url,返回一个list 元素为影片url
movice_url = await get_movice_url()
# 创建tasks把10部影片url作为参数传递给协程函数get_movice_info来获取影片名称和导演信息
tasks = [get_movice_info(url) for url in movice_url]
# 使用asyncio.gather方法运行,10个请求是同时运行的,按顺序返回结果
movice_info = await asyncio.gather(*tasks)
print(movice_info)
# 执行并计算执行耗时
if __name__ == '__main__':
start_time = time.time()
asyncio.run(main())
end_time = time.time()
print(end_time-start_time)
输出如下
[{'https://movie.douban.com/subject/3001114/': {'name': ['沙丘 Dune'], 'author': ['丹尼斯·维伦纽瓦']}}, {'https://movie.douban.com/subject/33457594/': {'name': ['摩加
迪沙 모가디슈'], 'author': ['柳昇完']}}, {'https://movie.douban.com/subject/34820925/': {'name': ['钛 Titane'], 'author': ['朱利亚·迪库诺']}}, {'https://movie.douban.com/subject/35235502/': {'name': ['驾驶我的车 ドライブ・マイ・カー'], 'author': ['滨口龙介']}}, {'https://movie.douban.com/subject/1428581/': {'name': ['天书奇谭'], 'author': ['王树忱', '钱运达']}}, {'https://movie.douban.com/subject/34626280/': {'name': ['月光光心慌慌:杀戮 Halloween Kills'], 'author': ['大卫·戈登·格林']}}, {'https://movie.douban.com/subject/35158124/': {'name': ['盛夏未来'], 'author': ['陈正道']}}, {'https://movie.douban.com/subject/34874432/': {'name': ['花束般的恋爱 花束み
たいな恋をした'], 'author': ['土井裕泰']}}, {'https://movie.douban.com/subject/35115642/': {'name': ['平行森林'], 'author': ['郑雷']}}, {'https://movie.douban.com/subject/32568661/': {'name': ['妈妈的神奇小子 媽媽的神奇小子'], 'author': ['尹志文']}}]
1.7407007217407227
可以看到执行相同的任务异步耗时比同步耗时省很多