参考:https://www.cnblogs.com/dbf-/p/11118628.html
queue(队列)
主要作用
1,解耦,使程序实现松耦合(一个模块修改不会影响其他模块)
2,提高效率
队列于列表的区别
队列中数据只有一份,取出来就没有了,区别于列表,列表数据取出来只是复制了一份,队列取出来相当于剪贴一份
分类
FIFO(先入先出)
默认即为先入先出
示例
queue_test.py
import queue # 先入先出(默认) q = queue.Queue() q.put(1) q.put(2) q.put(3) print(q.get()) print(q.get()) print(q.get()) # 1 # 2 # 3
LIFO(先入后出)
定义方法 queue.LifoQueue()
示例
# 先入后出 q = queue.LifoQueue() q.put(1) q.put(2) q.put(3) print(q.get()) print(q.get()) print(q.get()) # 输出 # 3 # 2 # 1
PriorityQueue(数据可设置优先级)
定义方法 queue.PriorityQueue()
同优先级按照ASCII排序
示例
# 数据可设置优先级,同优先级按照ASCII排序 q = queue.PriorityQueue() # 本次写入元素为元组 q.put((2,'2')) q.put((1,'1')) q.put((3,'3')) q.put((1,'a')) print(q.get()) print(q.get()) print(q.get()) print(q.get()) # 输出 # (1, '1') # (1, 'a') # (2, '2') # (3, '3')
queue模块
queue 模块中有 Queue 类,LifoQueue、PriorityQueue 都继承了 Queue
maxsize
maxsize 是实例化 Queue 类时的一个参数,默认为 0即队列容量无限
Queue(maxsize=0) 可以控制队列中数据的容量
示例
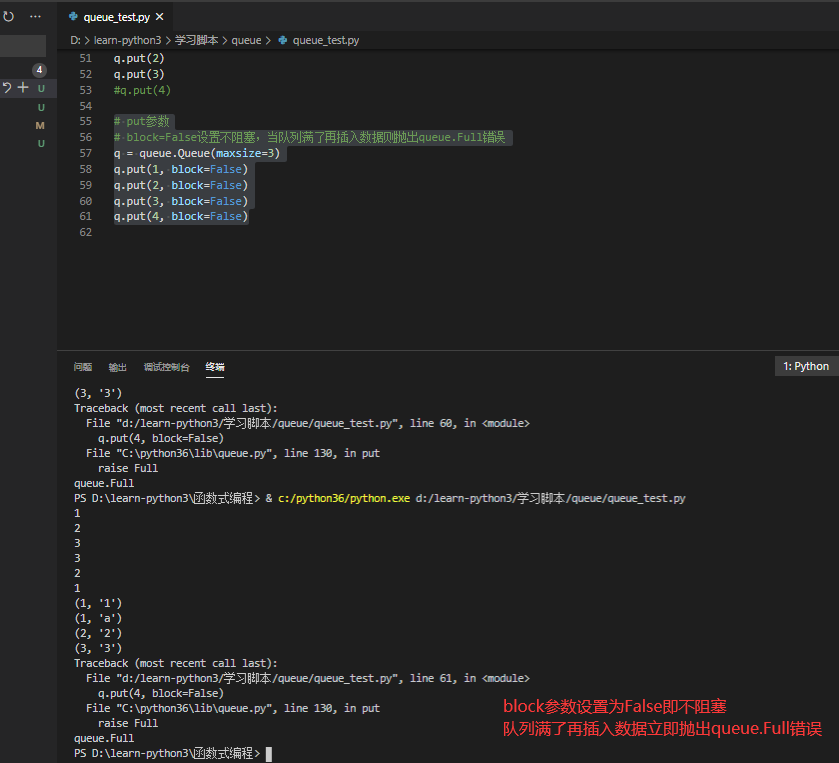
假设把maxsize参数设置为3则当队列已经有3个元素再put元素则会陷入阻塞状态
# maxsize控制队列容量,默认为0即默认无穷大 q = queue.Queue(maxsize=3) q.put(1) q.put(2) q.put(3) q.put(4)
运行结果

put
Queue.put(block=True, timeout=None)
block用于设置是否阻塞,默认为True即阻塞,timeout用于设置阻塞等待时长即如果等待时长到了则退出阻塞抛出full错误
示例
# put参数 # block=False设置不阻塞,当队列满了再插入数据则抛出queue.Full错误 q = queue.Queue(maxsize=3) q.put(1, block=False) q.put(2, block=False) q.put(3, block=False) q.put(4, block=False)
运行结果
小结
阻塞
当队列满了之后,put 就会阻塞,一直等待队列不再满时向里面添加数据
不阻塞
当队列满了之后,如果设置 put 不阻塞,或者等待时长到了之后会报错:queue.Full
get
Queue.get(block=True, timeout=None)
阻塞
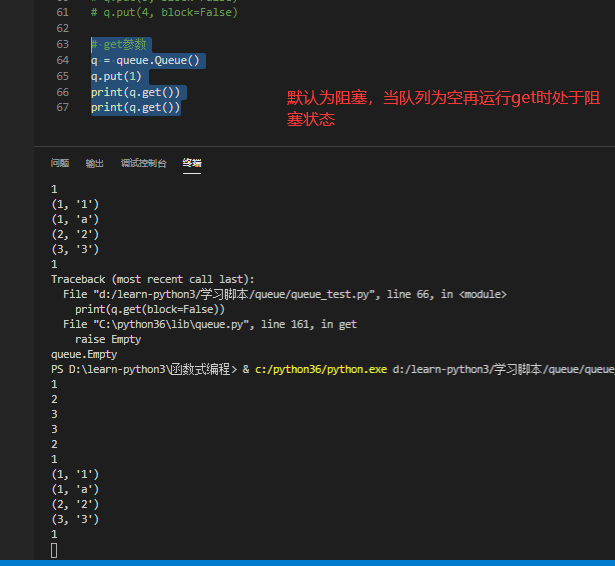
当队列空了之后,get 就会阻塞,一直等待队列中有数据后再获取数据
不阻塞
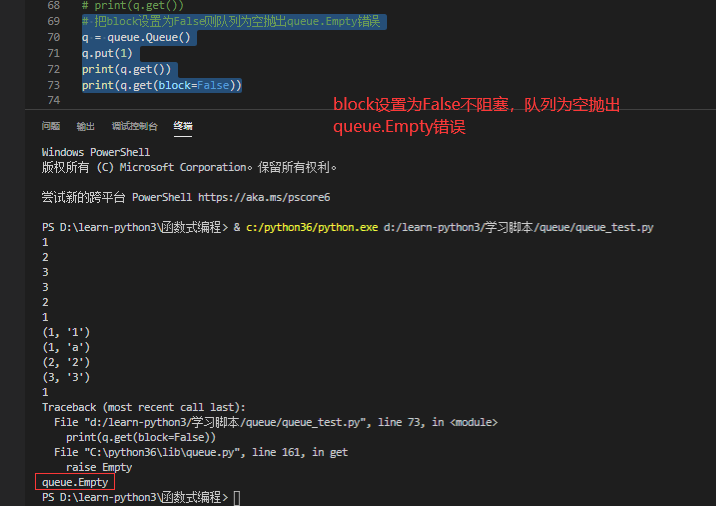
当队列空了之后,如果设置 get 不阻塞,或者等待时长到了之后会报错:_queue.Empty
示例
# get参数 q = queue.Queue() q.put(1) print(q.get()) print(q.get())
运行结果
get阻塞示例2
# 把block设置为False则队列为空抛出queue.Empty错误 q = queue.Queue() q.put(1) print(q.get()) print(q.get(block=False))
运行结果
full & empty
Queue.empty()/Queue.full() 用于判断队列是否为空、满
尽量使用 qsize 代替
示例
# full & empty q = queue.Queue(maxsize=1) q.put(1) # 队列满了full()返回True print(q.full()) # True # 队列空了empty()返回True q.get() print(q.empty()) # True
qszie
Queue.qsize() 用于获取队列中大致的数据量
注意:在多线程的情况下不可靠
因为在获取 qsize 时,其他线程可能又对队列进行操作了
示例
# qsize q = queue.Queue() q.put(1) # 队列元素数量为1 print(q.qsize()) # 1
join
join会在队列存在未完成任务时阻塞,等待队列无未完成任务,需要配合task_done使用
task_done
执行一次 put 会让未完成任务 +1 ,但是执行 get 并不会让未完成任务 -1 ,需要使用 task_done 让未完成任务 -1 ,否则 join 就无法判断
队列为空时执行会报错:ValueError: task_done() called too many times
示例
queue_test2.py
import queue
import threading
import time
def q_put():
for i in range(10):
q.put('1')
while True:
q.put('2')
time.sleep(1)
def q_get():
while True:
temp = q.get()
q.task_done()
print(temp)
time.sleep(0.3)
q = queue.Queue()
t1 = threading.Thread(target=q_put)
t2 = threading.Thread(target=q_get)
t1.start()
t2.start()
q.join()
print('queue is empty now')
运行输出
输出结果分析
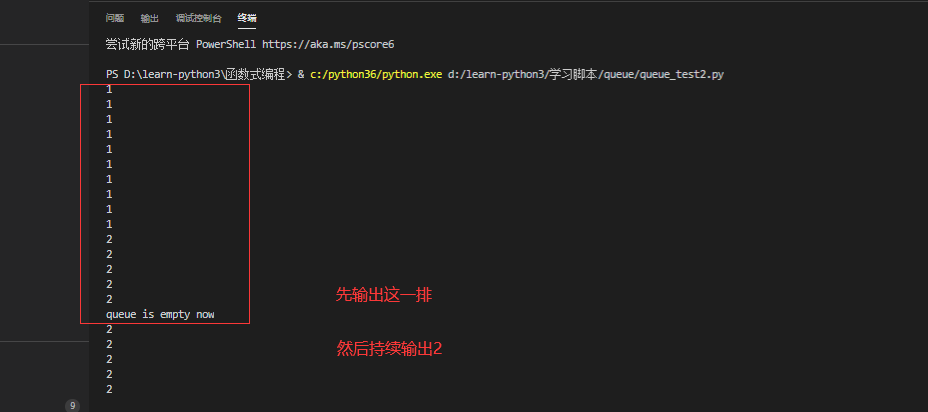
1,t1线程运行q_put()函数首先往队列q内放置10个1,然后没隔1秒放入1个2
2,t2线程没隔0.3秒从队列q取数据,每次都运行task_done使队列任务-1
3,运行到q.join()的时候,t1和t2线程还在持续运行,因为t2取数据的间隔时间比t1的间隔时间小,所以一定有取空队列数据的时候
4,当取空队列数据时,主线程运行打印‘queue is empty now’ 这个队列为空是暂时的,即t1还在持续往队列写数据,t2持续读取数据所以一直输出2
注意:以下两种情况会导致无法打印‘queue is empty now‘
1,未加task_done语句,则未完成任务不会减少所以语言一直阻塞在join,输出完1以后一直输出2
2,q_get()睡眠时间比q_put()睡眠时间长,即往队列写数据比从队列取数据速度快,未完成任务永远不可能为0
生产者和消费者模型(主要用于解耦)
在多线程开发中,如果生产线程处理速度很快,而消费线程处理速度很慢,那么生产线程就必须等到消费线程处理完,才能继续生产数据。同样的道理,如果消费线程的处理能力大于生产线程,那么消费线程就必须等到生产线程。为了解决这个问题引入生产者和消费者模式。
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
示例
queue_test3.py
import threading
import time
import queue
def producer():
count = 1
while True:
q.put('No.%i' % count)
print('Producer put No.%i' % count)
time.sleep(1)
count += 1
def customer(name):
while True:
print('%s get %s' % (name, q.get()))
time.sleep(1.5)
q = queue.Queue(maxsize=5)
p = threading.Thread(target=producer, )
c = threading.Thread(target=customer, args=('jack', ))
p.start()
c.start()
运行输出如下
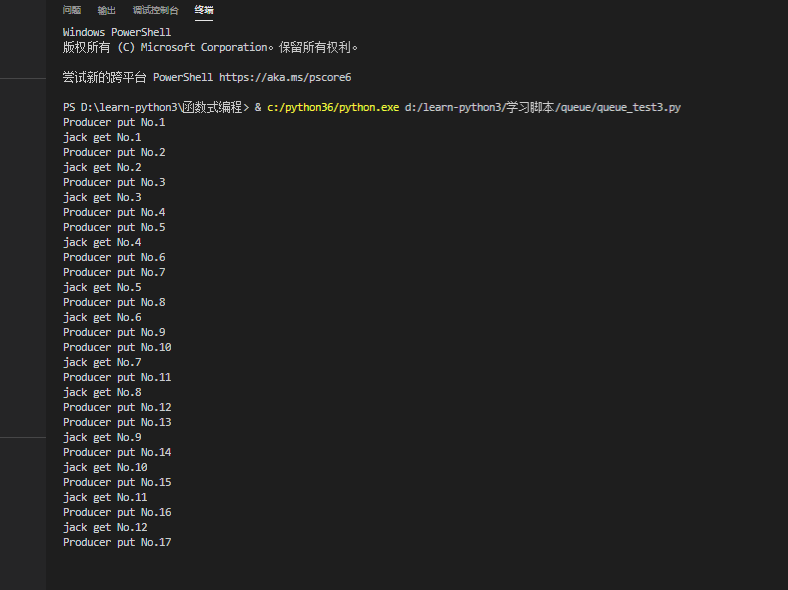
解析
生产者每隔1秒往队列插入一个数字从1开始加1递增,消费者每隔1.5秒从队列读取数据
因为生产者生产数据时间间隔比消费者间隔小,并且设置了队列的长度为5,所以运行脚本一段时间后生产者的数据始终保持5个
如果不设置maxsize限制队列长度,那么持续运行生产者中的数据会一直递增