三、容器Container
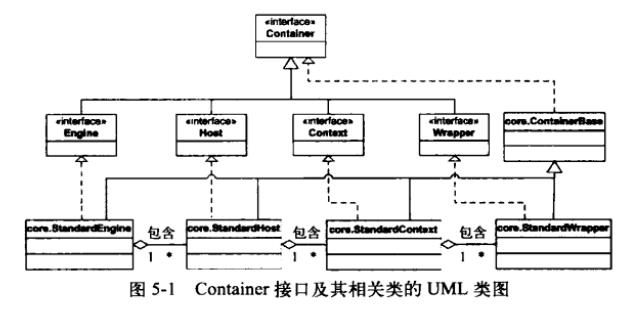
Container 是容器的父接口,所有子容器都必须实现这个接口。
Container 容器的设计用的是典型的责任链的设计模式,它有四个子容器组件构成,分别是:Engine、Host、Context、Wrapper,这四个组件不是平行的,而是父子关系,Engine 包含 Host,Host 包含 Context,Context 包含 Wrapper。通常一个 Servlet class 对应一个 Wrapper,如果有多个 Servlet 就可以定义多个 Wrapper。
| 容器定义 | 标准实现类 | 基础阀类 | 其他 |
|
Engine: 表示整个Catalina servlet引擎 |
StandardEngine | StandardEngineValue |
使用映射器Mapper返回子容器中特定的Host |
|
Host: 表示包含一个或者多个Context容器的虚拟主机 |
StandardHost | StandardHostValue | 使用映射器Mapper返回子容器中特定的context |
|
Context: 表示一个Web应用程序 |
StandardContext | StandardContextValue | 使用映射器Mapper返回子容器中特定的Wrapper |
|
Wrapper: 表示一个独立的servlet |
StandardWrapper | StandardWrapperValue |
调用其invoke方法之前先要执行过滤器链 会调用具体servlet的service(),该service默认是无状态可并发的 |
四、容器Container如何处理请求
我们现在解决传递到container的请求是如何找到对应的servlet的,首先关注connector启动的时候Container的初始化流程:
public static void main(String[] args) { HttpConnector connector = new HttpConnector(); //两个wapper Wrapper wrapper1 = new SimpleWrapper(); wrapper1.setName("Primitive"); wrapper1.setServletClass("PrimitiveServlet"); Wrapper wrapper2 = new SimpleWrapper(); wrapper2.setName("Modern"); wrapper2.setServletClass("ModernServlet"); //建立context和wapper的关系 Context context = new SimpleContext(); context.addChild(wrapper1); context.addChild(wrapper2); //建立两个阀,并放到context的管道中 Valve valve1 = new HeaderLoggerValve(); Valve valve2 = new ClientIPLoggerValve(); ((Pipeline) context).addValve(valve1); ((Pipeline) context).addValve(valve2); // 建立Mapper,用于映射wrapper // context.addServletMapping(pattern, name); Mapper mapper = new SimpleContextMapper(); mapper.setProtocol("http"); context.addMapper(mapper);
context.addServletMapping("/Primitive", "Primitive"); context.addServletMapping("/Modern", "Modern");
//建立class loader
Loader loader = new SimpleLoader();
context.setLoader(loader); //建立连接器和容器的关系
connector.setContainer(context);
try {
connector.initialize(); //启动连接器
connector.start();
}
catch (Exception e) { e.printStackTrace(); }
}
}
1、管道Pipeline:我们这里看到了Pipeline,可以理解为Context容器内部维护了一个管道,可以向这个管道中添加各式各样的阀。
当invoke调用到达context容器后,下面实际调用的是Pipeline的invoke方法,该方法依次遍历管道上的各种阀,一个阀处理完成后,交个下一个阀进行处理,该设计模式为责任链模式。基础阀总是随后一个执行,基础阀一般用来找到对应的子容器warpper并调用子容器的service()方法。
2、映射器Mapper:那么是如何找到对应的servlet的呢,这里用到了映射器Mapper,context根据映射规则就可以找到对应的servlet,执行对应的service(),至此,一个处理请求完毕。
3、总体过一遍:连接器收到请求后,创建request/response,调用StandardContext的invoke方法;该invoke方法调用其管道对象的invoke方法,管道对象的invoke方法会依次调用其阀的invoke,最后调用基础阀的invoke;基础阀是StandardContextValue类的实例,基础阀的invoke方法被调用,基础阀invoke会获取Wrapper实例,并依次执行Warpper的管道对象的阀,最终通过Mapper找到对应的servlet,执行servlet的service()方法。
五、容器Container生命周期管理Lifecycle
catalina允许一个组件包含多个其他组件,当父组件启动和关闭的时候,子组件会跟着一起启动和关闭,该部分关键是Lifecycle接口
public interface Lifecycle { public void addLifecycleListener(LifecycleListener listener); public void removeLifecycleListener(LifecycleListener listener); public void start() throws LifecycleException; public void stop() throws LifecycleException; }
1、启动/关闭的时候,会依次遍历注册到该容器的子容器,调用子容器的start/stop方法,像链式爆炸一样,把整个关联的容器都启动/关闭
2、事件Listener会预先调用容器的addLifecycleListener方法,将事件监听器加到该容器维护的监听器数组中,于是容器在特定的时机调用 lifecycle.fireLifecycleEvent(START_EVENT, null);就会遍历这些监听器,调用这些监听器的lifecycleEvent()方法,这是一种典型的发布者订阅者模式的应用。
六、载入器Loader
tomcat使用自定义载入器的原因:
1、servlet应该只允许载入web-inf/classes、web-inf/lib下的类,访问其余目录(环境变量中classpath指定的路径)会是危险的,因此要设置一些载入规则。
2、将载入的类缓存起来
3、支持自动重载的功能。当web-inf/classes、web-inf/lib下的类发生变化的时候,web应用会重新载入这些类。tomcat实现该功能的方法是使用一个额外的线程不断地检查这些类的时间戳,发现变动后会自动载入。
支持自动重载功能,需要设置server.xml
<Context docBase="D:ProgramServerTomcat7stswebapps raveller" path="/traveller" reloadable="true" source="org.eclipse.jst.jee.server:traveller"/>
org.apache.catalina.loader.webappLoader类实现Loader接口,作为应用载入器,负责载入web应用程序中使用到的类。
WebappLoader类会创建org.apache.catalina.loader.WebappClassLoader类的实例作为类载入器,WebappClassLoader默认会使用java.net.URL.ClassLoader具体承担载入类的工作。
WebappClassLoader会缓存它所加载的类,它会维护一个Vector对象,保存已经载入的类,防止这些类在不适用的时候被当做垃圾回收。
七、Session管理器
1、session对象怎么存储的
Context容器的Session管理器会管理Context容器中所有活动的Session对象,这些活动的Session对象都存储在一个名为sessions的HashMap变量中
2、session对象超时失效是怎么做到的
Session管理器通过建立一个专门的线程,来实现销毁已经失效的Session对象的。其思想就是周期地遍历Session管理器管理的所有Session对象,将Session对象的lastAccessedTime和当前时间进行比较,如果两者的差值超过了某个常数,就会调用Session对象的expire()方法使其失效。
3、session对象的持久化
session管理器可以将session对象持久化,存储到文件存储器或者通过JDBC存储到数据库中。以便再次启动的时候重新读入内存,维持session的状态不变化。
在持久化session管理器中,session可以备份,也可以换出。当备份一个session对象的时候,该Session对象会被复制到存储器中,而原对象依然保留在内存中。当对象被换出,意思是当前活动的session对象超过了上限值,或者这个session对象闲置了过长的时间,之所以换出是为了节省时间。
因为session对象可以被换出,所以它既可能存储在内存中,也可能存储在存储器中,因此,当客户端需要访问session数据的时候,findSession()方法会在内存中查找是否存在该session实例,如果没有找到,就到存储器中去查找。
public Session findSession(String id) throws IOException { Session session = super.findSession(id); if (session != null) return (session); // See if the Session is in the Store session = swapIn(id); return (session); }