BiLSTM-CRF做命名实体识别NER任务
入门讲解参考:https://mp.weixin.qq.com/s/x9ZYVZkbhysaH3CXfp3Blg
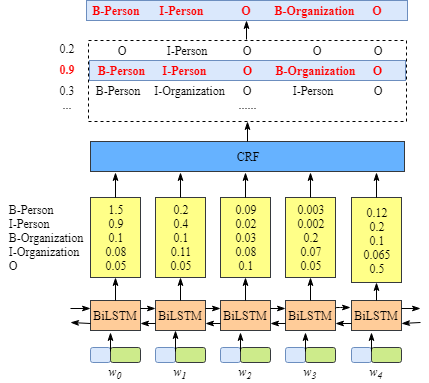
注意:图中BiLSTM和CRF没有直接输入或连接关系。
CRF的意义是从所有可能排列的路径中,选择概率最大的路径。其实CRF是一个(N+2)x(N+2)矩阵,矩阵中(i,j)表示从标签i转移到标签j的概率,+2表示加入START和END标签。该矩阵经反向传播学习。
损失函数包括两部分Emission得分和Transition得分。
Emission得分
emission得分就是LSTM的输出NxL,N表示句子长度,L表示标签数量。用(E_i[k])表示,表示在i时刻标签k的分数。
Transition得分
transition得分就是CRF需要学习的参数(N+2)x(N+2)。用(T[i,j])表示,表示标签i转移到标签j的概率。
损失函数
定义:
- 句子:(X=(x_1, x_2, ..., x_n))
- 标签:(y = (y_1, y_2,...,y_n))
- 标签y的得分:(s(X, y)= sumlimits^n_{i=1}{E_i[y_i]}+sumlimits_{i=1}^{n-1}T[y_i,y_{i+1}])
所以,序列的得分可以定义为归一化之后的概率:
取对数:
关键是求第二项:所有路径的指数分数和
动态规划(前向算法):可以求每一时刻t的所有状态的分数,然后加起来最后时刻T的所有状态的分数。
设t时刻标签为i的路径(即(y_t=i))的指数和的对数:
则t+1时刻,标签为j的路径的指数和的对数:
设一个L维的向量(alpha_t[i]) 表示t时刻标签为i的路径的分数和:(alpha_t = [alpha_t(y_t=1),...,alpha_t(y_t=L)])
那么t+1时刻为:(alpha_{t+1} = [log sum exp(alpha_t(1)+E_{t+1}[1]+T[i,1]),...,logsum exp({alpha_t(L)+E_{t+1}[L]+T[i,L])}])
注意:
在每步计算log_sum_exp(xi)时,需要对xi缩放,保证指数最大不超过0,于是就不会上溢出。取xi最大值a,于是:
(logsum exp(x_i) = logsum [exp(x_i-a)* exp(a)] = a + logsum exp(x_i - a))
预测
预测时候需要用到维特比算法:利用前向算法,在每步之间保存上一个时刻到当前时刻的最优路径,最后回溯路径。
代码实现
pytroch代码讲解以及实现,请参考:https://zhuanlan.zhihu.com/p/97676647