之前一段时间由于版本迭代任务紧,组内代码质量不尽如人意。接二连三的被测试提醒后台错误之后, 我们决定搭建一个后台日志分析系统, 经过几个方案比较后,选择的相对更简单的ELK方案。
ELK 是Elasticsearch, Logstash,Kibana三个组件的首字母组合,这种方案最初的做法是:使用Logstash 去服务上采集日志文件, 然后做一些过滤处理后发送给 Elasticsearch, 在Elasticsearch中创建相应的索引,由Kibana提供统计分析的页面访问。但是Logstash 本身资源消耗较大,如果把它放到业务系统的服务器上会对系统造成不小的影响,一般的做法采用beats来替代(beats是一个更轻量级的收集器),参考如下图-1,此外也会有在数据量比较大时引入消息队列来环节组件压力。
详细的关于各组件的介绍建议参考Elastic 提供的官方文档

(图-1)
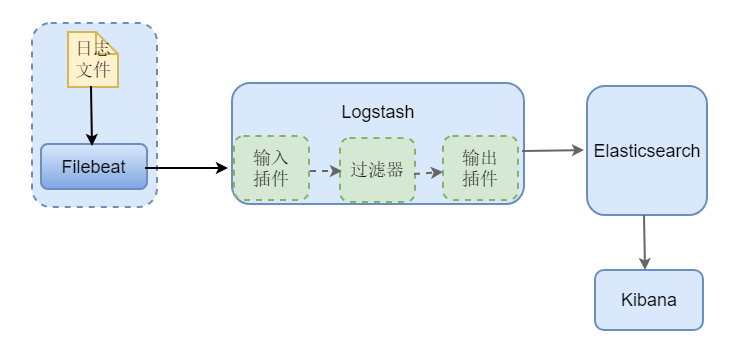
(图-2)
本文将基于上图-2的架构来介绍ELK日志系统的搭建。由于环境限制,这里各组件均部署在同一服务器上。
1)搭建elasticsearch
elasticsearch的下载安装配置在所有组件中相对是最复杂的,但是它依然可以很简单的按照如下几个步骤顺利完成:
① 官网下载地址 :https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.1.1-linux-x86_64.tar.gz
② 解压之后配置 elasticsearch-7.1.1/config/elasticsearch.yml 文件,如下
# ---------------------------------- Cluster ----------------------------------- # 指定集群名 cluster.name: customer-service # ------------------------------------ Node ------------------------------------ # 在集群名为customer-service 的集群下的 node-1 节点 node.name: node-1 # ---------------------------------- Network ----------------------------------- # 开启本质之外的网络访问 network.host: 0.0.0.0 # --------------------------------- Discovery ---------------------------------- # 定义初始主机点 cluster.initial_master_nodes: ["node-1"]
③ 启动elasticsearch (处于安全考虑 elasticsearch 只能非root用户启动,需要将elasticsearch解压文件切换所属用户)
# 解压路径下
./bin/elasticsearch
④ 验证elasticsearch是否启动成功
curl http://localhost:9200
如果看到如下结果,代表启动成功
{ "name" : "node-1", "cluster_name" : "elasticsearch", "cluster_uuid" : "tYgc-2l3ThqcEfFKfeWgBQ", "version" : { "number" : "7.1.1", "build_flavor" : "default", "build_type" : "tar", "build_hash" : "7a013de", "build_date" : "2019-05-23T14:04:00.380842Z", "build_snapshot" : false, "lucene_version" : "8.0.0", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search" }
2)Kibana的安装
① 官网下载:https://artifacts.elastic.co/downloads/kibana/kibana-7.1.1-linux-x86_64.tar.gz
② 配置解压路径下的/kibana-7.1.1-linux-x86_64/config/kibana.yml文件:
# 将server.host 改为所有IP, 这样以便不同主机可以访问到kibana页面
server.host: 0.0.0.0
③ 浏览器访问 http://ip:5601 (默认5601端口,可以在kibana.yml中配置) 得到如下页面表示启动成功
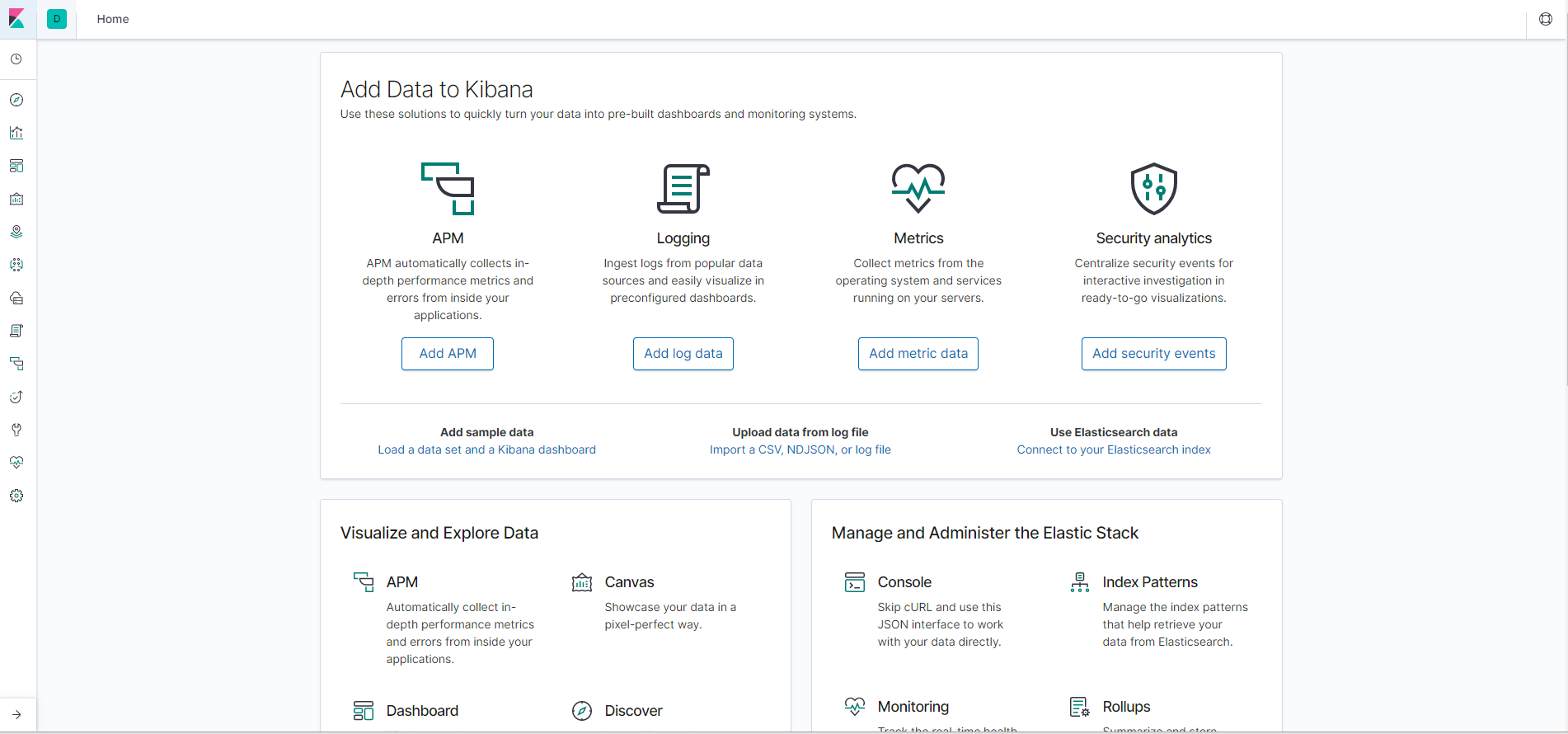
(图-3)
3)Filebeat 的安装
① 官方下载:https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.1.1-linux-x86_64.tar.gz
② 配置解压路径下的配置文件 filebeat.yml 如下:
#=========================== Filebeat inputs ============================= filebeat.inputs: # Each - is an input. Most options can be set at the input level, so # you can use different inputs for various configurations. # Below are the input specific configurations. - type: log # Change to true to enable this input configuration. enabled: true # 需要被采集的日志文件的路径 paths: - /app/applogs/provider/info/dubbo-info.log #----------------------------- Logstash output -------------------------------- output.logstash: # 指定logstash的地址和端口 hosts: ["127.0.0.1:5044"]
③ 启动 filebeat
# 注意使用root用户登录, 准确的说是注意用户对文件所拥有的权限
# -e 让日志打印到控制台, -c 重新指定启动的配置文件, -d 指定调试选择者器
./filebeat -e -c filebeat.yml -d "publish"
4)Logstash 的安装
① 官网下载:https://artifacts.elastic.co/downloads/logstash/logstash-7.1.1.tar.gz
② 配置logstash,增加customer-service-logstash.yml 的配置文件,文件配置内容如下:
# logstash 输入配置,这里我们采用beat采集日志
input { beats { port => "5044" } }
# The filter part of this file is commented out to indicate that it is # optional. filter { grok { match => { "message" => "%{COMBINEDAPACHELOG}"} }
# 此外还可以添加其他过滤器插件 } output {
# 输出到控制台打印 stdout { codec => rubydebug }
# 输出到elasticsearch ,并指定索引名称 elasticsearch { hosts => [ "127.0.0.1:9200" ] index => "logstash-customer-service-log" } }
③ 启动logstash
# -f 从指定路径获取logstash启动的yml配置文件
# --config.reload.automatic 监听配置文件 如果有改动自动加载
bin/logstash -f first-pipeline.conf --config.reload.automatic
所有上述组件配置启动成功后,我们可以到kibana界面, 在侧边栏 management 下按下图-4方式创建 索引模式后,然后在图-5中可以获取到实时的日志记录。
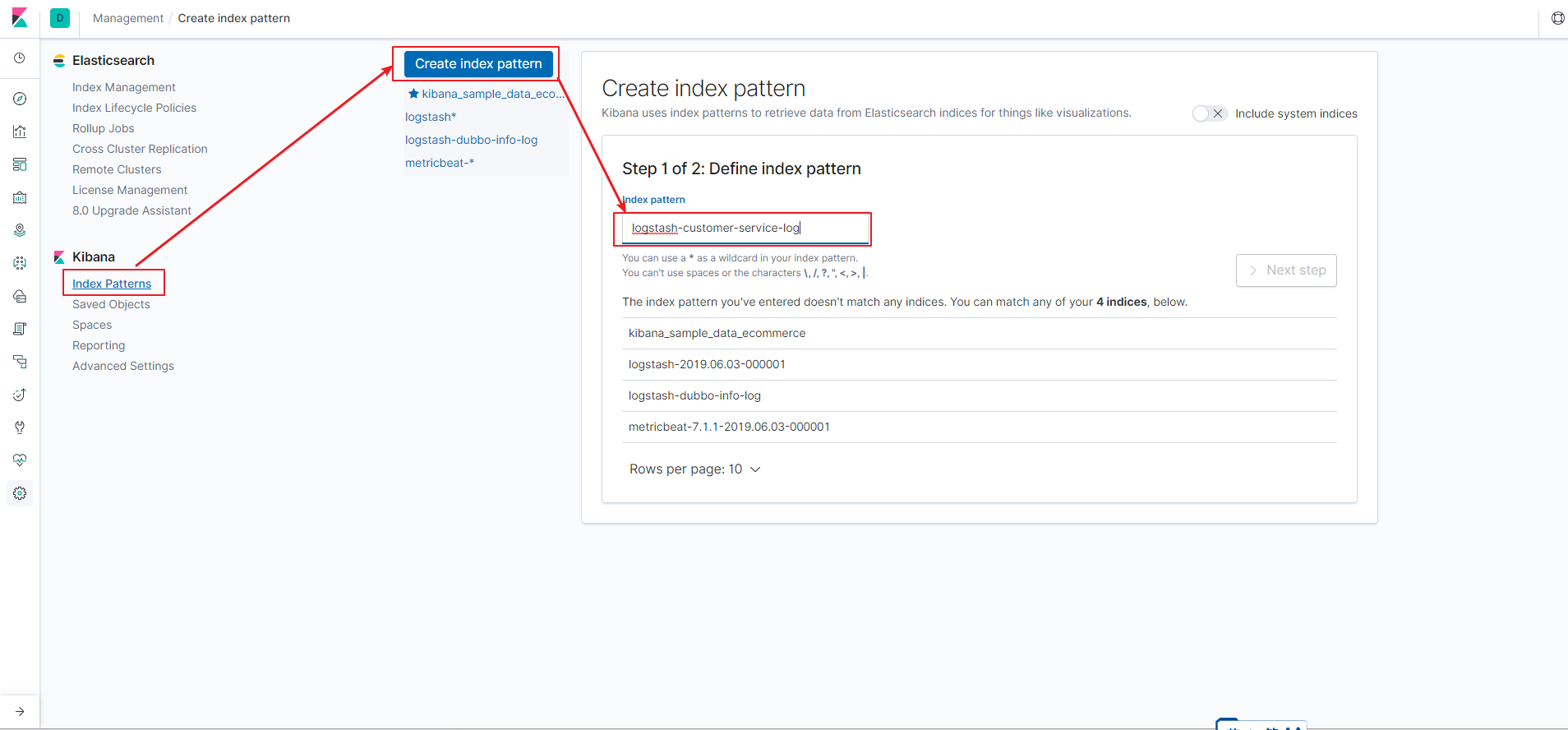
(图-4)
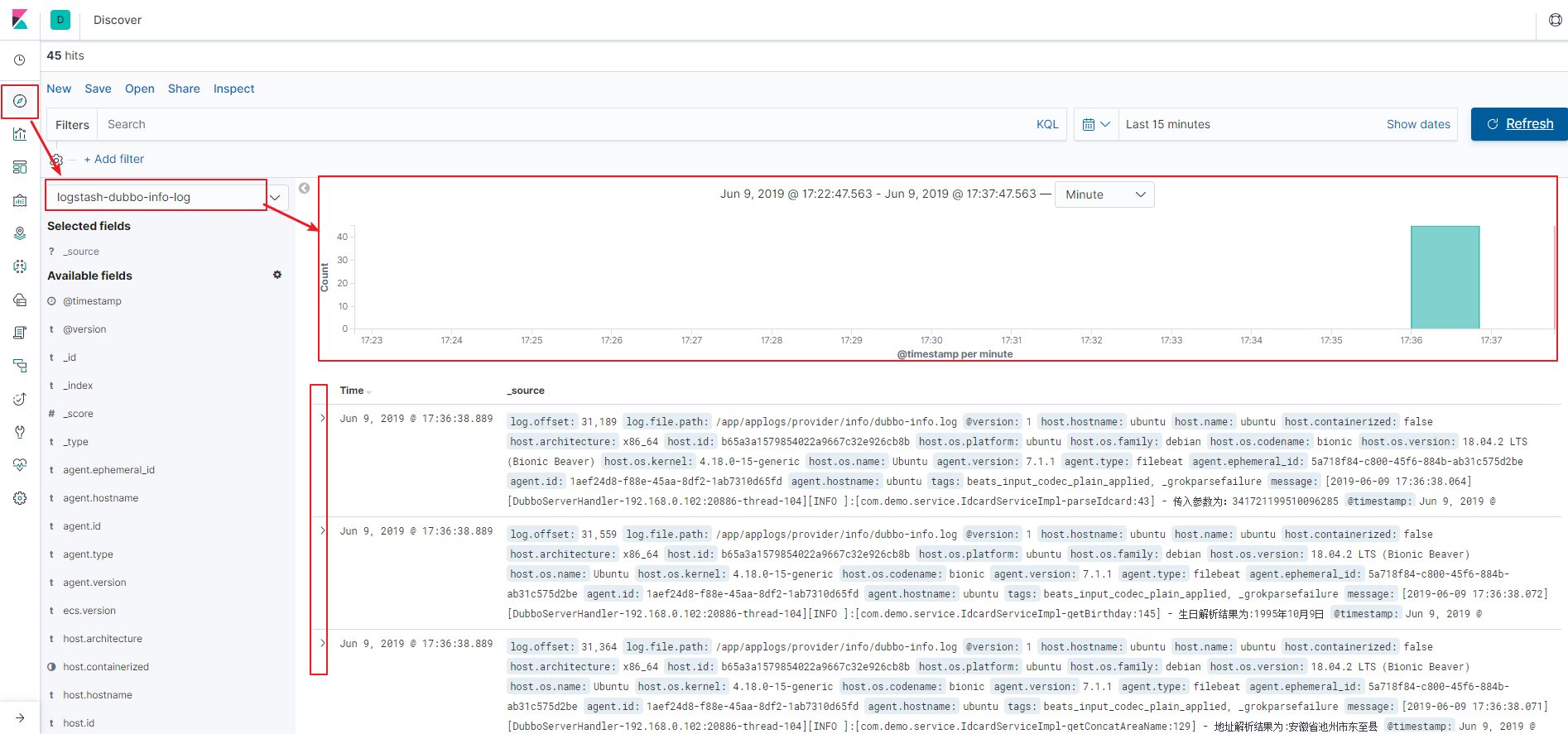
(图-5)
我们在logstash中增加对error级别日志的过滤处理,将这些日志统一放到 logstash-customer-service-error 索引中,然后在 kibana 中创建该索引同名的pattern, 这样在discover页签下可以直观的通过 时间段的筛选来定位error日志,并在下面的 expanded document 下查看日志的具体内容,这样一来就不需要挨个连接到服务器去手动查看日志了。